Multi-Agent Coordination with Limited Information
In multi-agent systems with partial observability, agents must coordinate using limited information. This problem examines what information enables coordination through systematic ablation of available signals.
Problem Setting
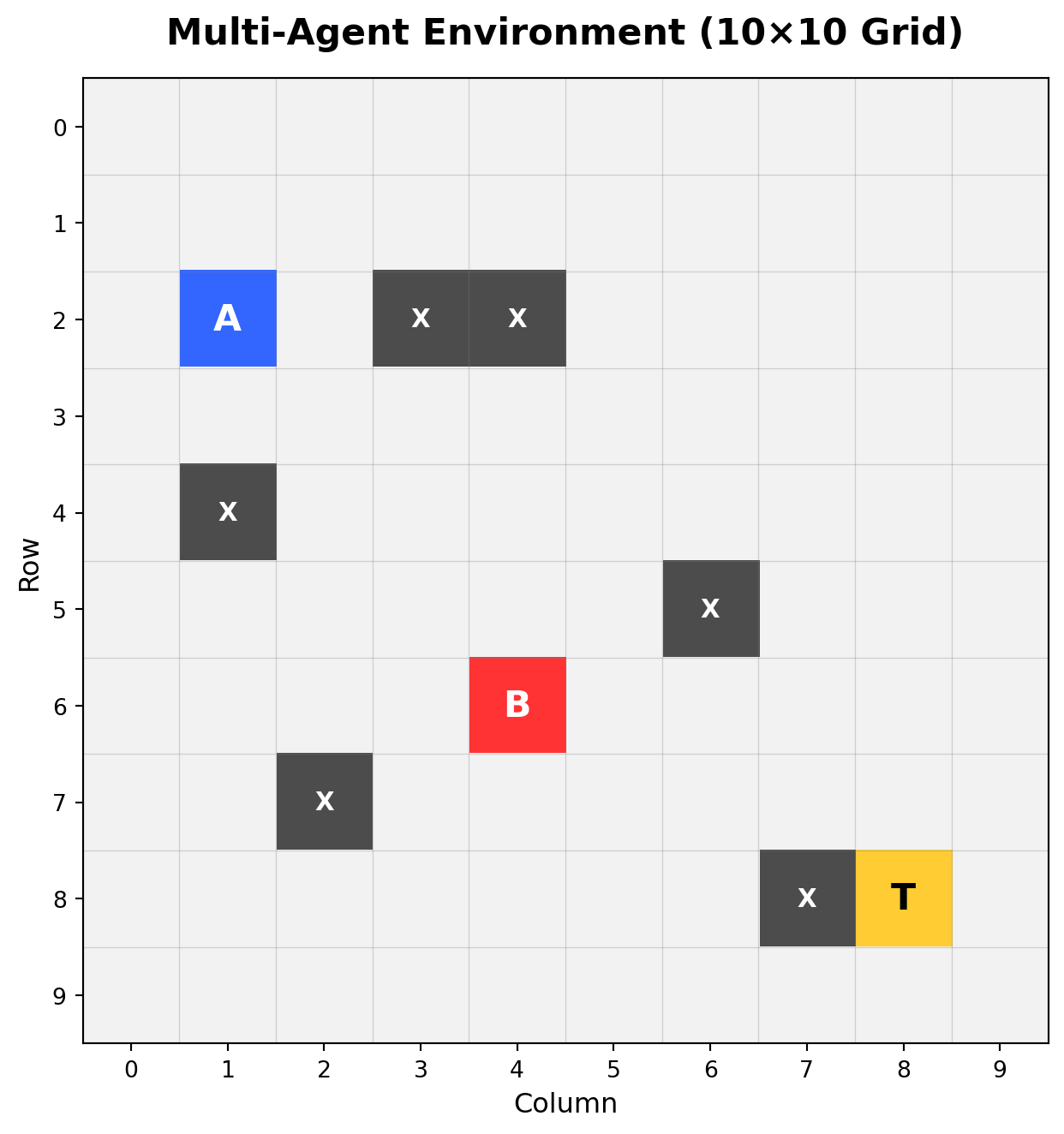
Two agents navigate a 10×10 gridworld with partial observability, attempting to simultaneously occupy a target location. Each agent observes only a 3×3 local patch centered on its position. Additional information channels may include distance to target and inter-agent communication.
Environment:
- Agents A and B: Must coordinate to reach target simultaneously
- Target (T): Shared goal location
- Obstacles (X): Impassable cells
- Grid size: 10×10
- Episode limit: 50 steps maximum
Observation and Action Spaces
Base Scenario: Independent Agents
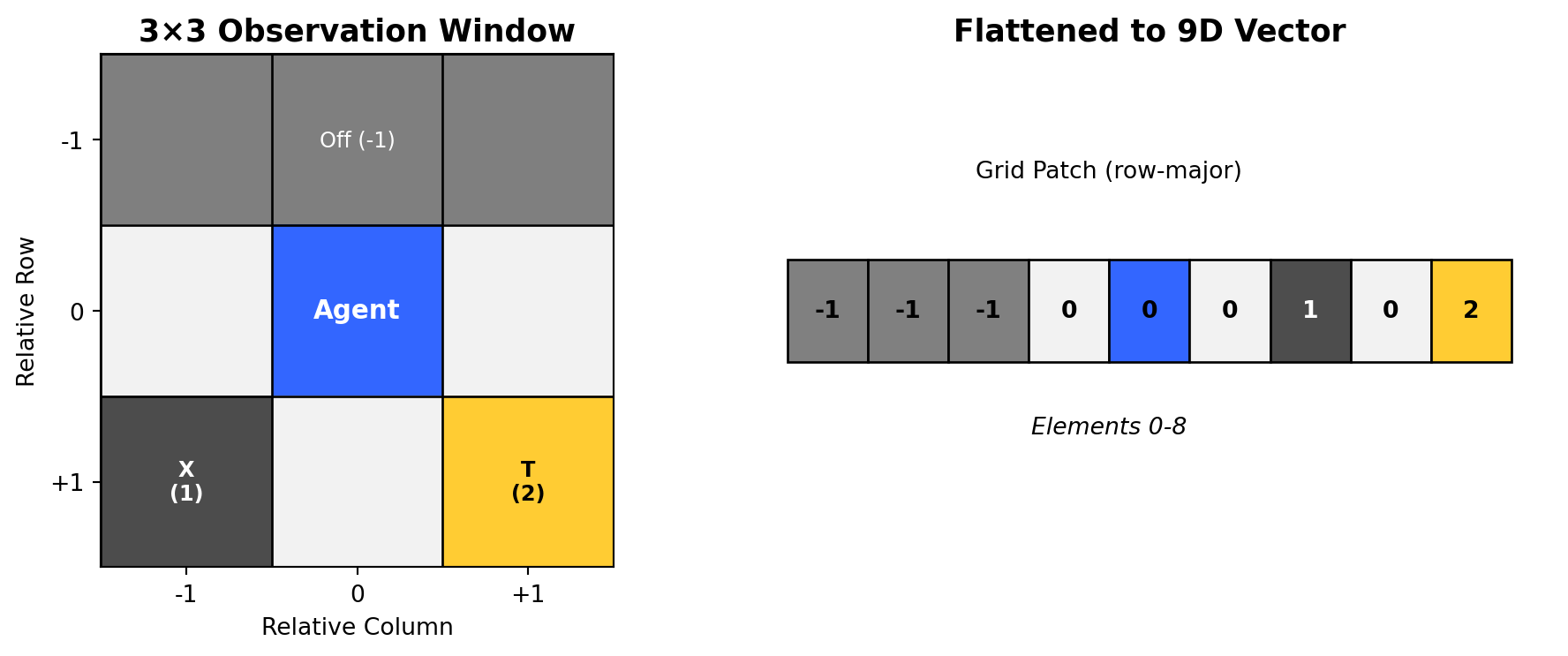
Each agent receives a 9-dimensional observation vector:
Elements 0-8: Flattened 3×3 grid patch (row-major order)
- Cell values: 0 (free), 1 (obstacle), 2 (target), -1 (off-grid)
- Agent positions not explicitly marked in observations
In this scenario, agents operate independently with only local observations.
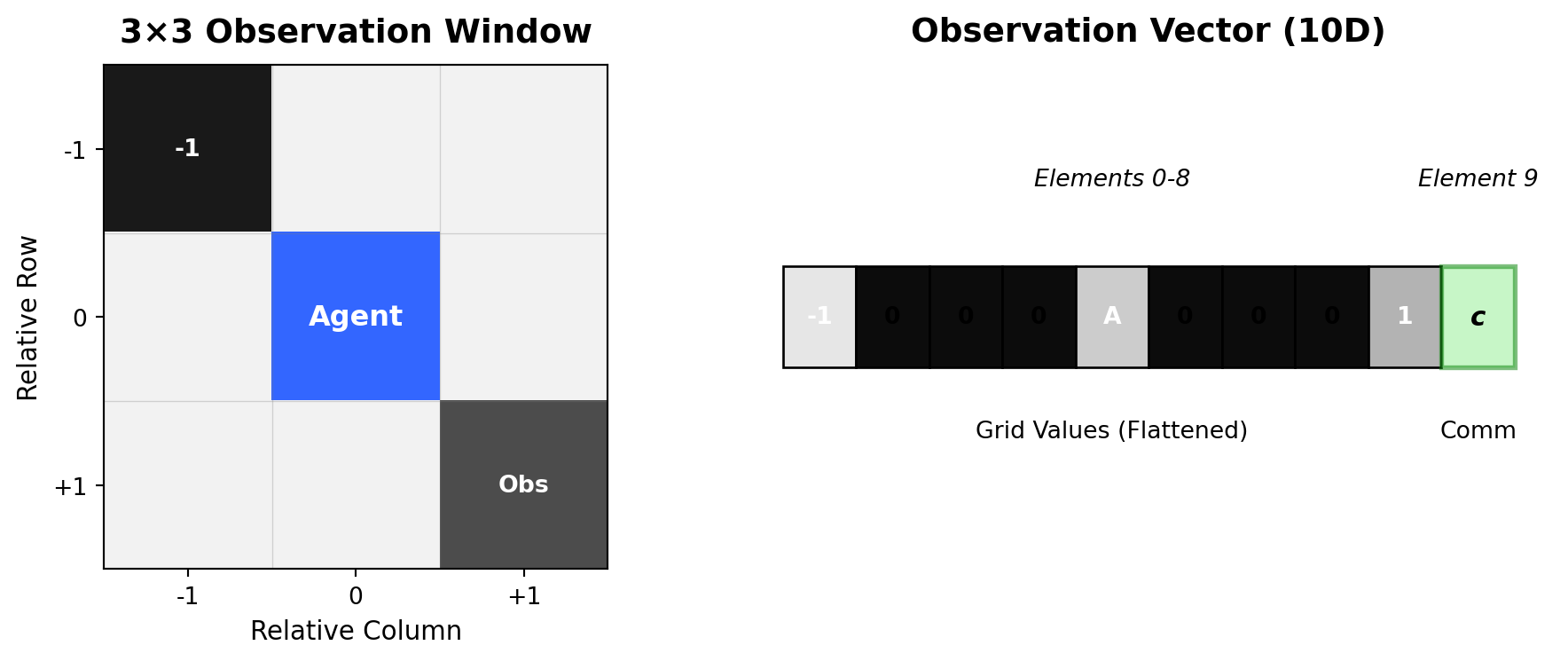
Scenario B: Communication Channel
Observation extends to 10 dimensions:
- Elements 0-8: Same as base scenario
- Element 9: Communication scalar from partner agent (bounded [0,1])
Agents can now share information through a learned communication protocol.
Scenario C: Distance and Communication
Observation extends to 11 dimensions:
- Elements 0-8: Same as base scenario
- Element 9: Communication scalar from partner agent
- Element 10: Normalized distance between agents
Distance computation: \[d = \frac{\sqrt{(x_A - x_B)^2 + (y_A - y_B)^2}}{\sqrt{H^2 + W^2}}\]
where \((x_A, y_A)\) and \((x_B, y_B)\) are the positions of agents A and B, and \(H, W\) are grid dimensions. This distance represents signal strength in a beacon-like communication system. Normalization ensures the distance is bounded in [0,1] regardless of grid size, maintaining consistent input scale across different environments.
The action space combines movement and communication:
- Movement actions: {Up, Down, Left, Right, Stay}
- Communication output: Bounded scalar \(c \in [0, 1]\)
Deep Q-Network Architecture
The agent network processes partial observations to produce action-values and communication signals:
\[\begin{aligned} h &= \text{ReLU}(W_1 \cdot [\text{obs}, \text{comm}_{in}] + b_1) \\ Q(s,a) &= W_{action} \cdot h + b_{action} \quad \in \mathbb{R}^5 \\ c_{out} &= \sigma(W_{comm} \cdot h + b_{comm}) \quad \in [0, 1] \end{aligned}\]
Multi-Agent Q-Learning
The agents learn through independent Q-learning with shared experiences. The temporal difference target for agent \(i\):
\[y_i = r + \gamma \max_{a'} Q_i(s', a'; \theta^-_i)\]
where \(\theta^-\) represents target network parameters (updated periodically for stability). The loss combines both agents’ TD errors:
\[\mathcal{L} = \mathbb{E}_{(s,a,r,s') \sim \mathcal{D}} \left[ (Q_A(s_A, a_A) - y_A)^2 + (Q_B(s_B, a_B) - y_B)^2 \right]\]
Experience replay \(\mathcal{D}\) stores tuples \((s_A, s_B, a_A, a_B, c_A, c_B, r, s'_A, s'_B)\) capturing joint experiences.
Reward Structure
Reward structure:
\[R(s,a) = \begin{cases} +10 & \text{if both agents on target} \\ +2 & \text{if one agent on target} \\ -0.1 & \text{step penalty} \end{cases}\]
The partial reward for single-agent arrival provides intermediate feedback to guide exploration, while the full reward requires coordination.
Agents must:
- Discover the target location through exploration
- Coordinate arrival timing
- Learn which actions and communications led to success
Tasks
You may use the provided starter code, but must follow the interfaces exactly. Use discount factor γ = 0.99.
Implement the multi-agent environment following the
MultiAgentEnvinterface specification belowImplement the DQN architecture with dual outputs (Q-values and communication signal) following the
AgentDQNinterfaceImplement experience replay with batched updates
Implement \(\epsilon\)-greedy exploration for action selection
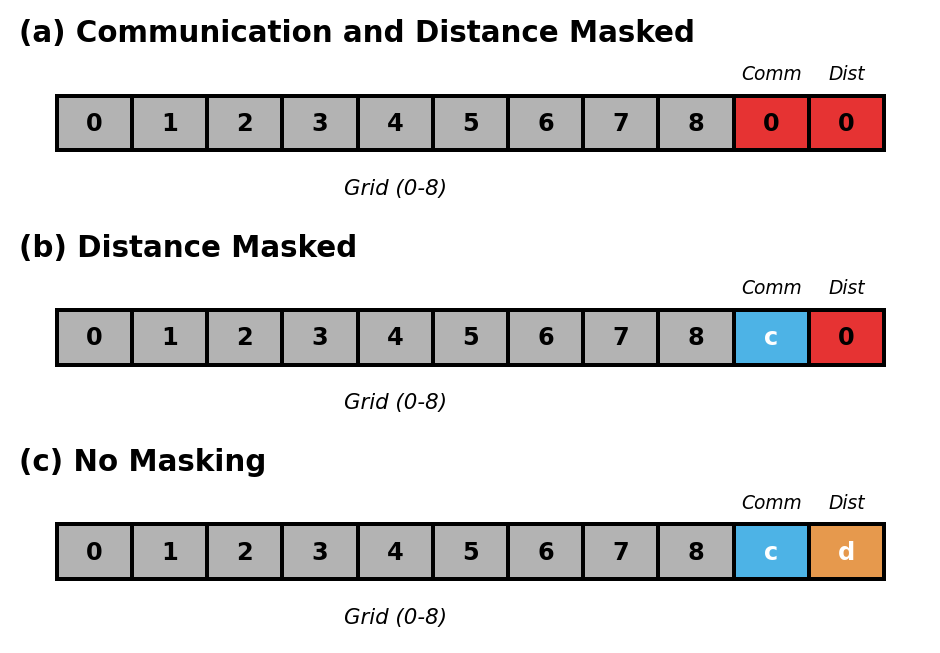
Conduct ablation study using a unified 11-dimensional observation space and single network architecture. Control information availability through input masking:
- (a) Independent: Mask elements 9-10 with zeros
- (b) Communication Only: Mask element 10 with zero
- (c) Full Information: No masking
- Train all three configurations and save models in TorchScript format
Report Requirements
Your report for Problem 2 should include:
- Training hyperparameters (learning rate, batch size, epsilon schedule, replay buffer size)
- Training curves for all three configurations showing average reward and success rate
- Final success rates for each configuration
- Comparison table of performance across configurations
- Analysis of how distance information and communication affect coordination
- Discussion of learned strategies in each configuration
Required Interfaces
The following interfaces must be implemented exactly as specified for autograding:
Environment Interface
class MultiAgentEnv:
def __init__(self, grid_size=(10, 10), obs_window=3, max_steps=50):
"""
Initialize the environment.
Parameters:
grid_size: Tuple defining grid dimensions (default 10x10)
obs_window: Size of local observation window (must be odd, default 3)
max_steps: Maximum steps per episode
"""
def reset(self):
"""
Reset environment to initial state.
Returns:
obs_A, obs_B: Tuple[np.ndarray, np.ndarray]
Each observation is an 11-dimensional vector:
- Elements 0-8: Flattened 3x3 grid patch (row-major order)
- Element 9: Communication signal from partner
- Element 10: Normalized L2 distance between agents
"""
def step(self, action_A, action_B, comm_A, comm_B):
"""
Take a step in the environment.
Parameters:
action_A, action_B: Discrete actions (0:Up, 1:Down, 2:Left, 3:Right, 4:Stay)
comm_A, comm_B: Communication scalars from each agent
Returns:
(obs_A, obs_B), reward, done
- reward: +10 if both agents at target, +2 if one agent at target, -0.1 per step
- done: True if both agents at target or max steps reached
"""Network Interface
class AgentDQN(nn.Module):
def __init__(self, input_dim=11, hidden_dim=64, num_actions=5):
"""
Initialize the DQN.
Parameters:
input_dim: Dimension of input vector (default 11)
hidden_dim: Number of hidden units (default 64)
num_actions: Number of discrete actions (default 5)
"""
def forward(self, x):
"""
Forward pass.
Parameters:
x: Tensor of shape [batch_size, input_dim]
Returns:
action_values: Tensor of shape [batch_size, num_actions]
comm_signal: Tensor of shape [batch_size, 1]
"""