Object Detection and Segmentation
EE 641 - Unit 2
Discrete Convolution Operation
Definition
For 2D discrete signals \(x\) and kernel \(h\):
\[(x * h)[i,j] = \sum_{m=0}^{K-1} \sum_{n=0}^{K-1} h[m,n] \cdot x[i+m, j+n]\]
where \(K\) is the kernel dimension.
Neural Network Convention
CNNs implement cross-correlation (not convolution):
- No kernel flipping
- Direct sliding dot product
- Mathematically: \((x \star h)\) not \((x * h)\)
This distinction is academic during learning since kernels are learned.
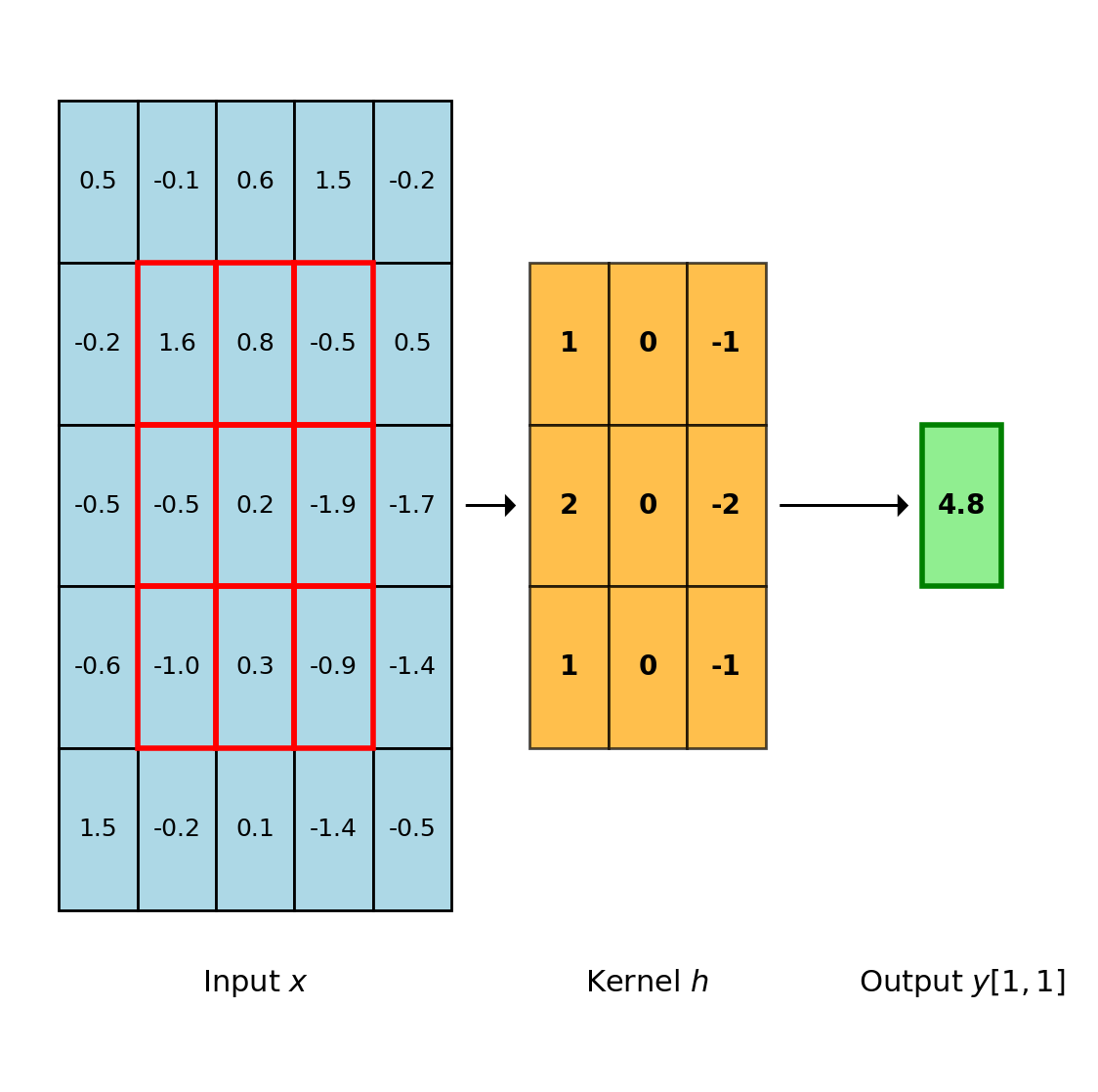
One output element requires \(K^2\) multiply-accumulate operations
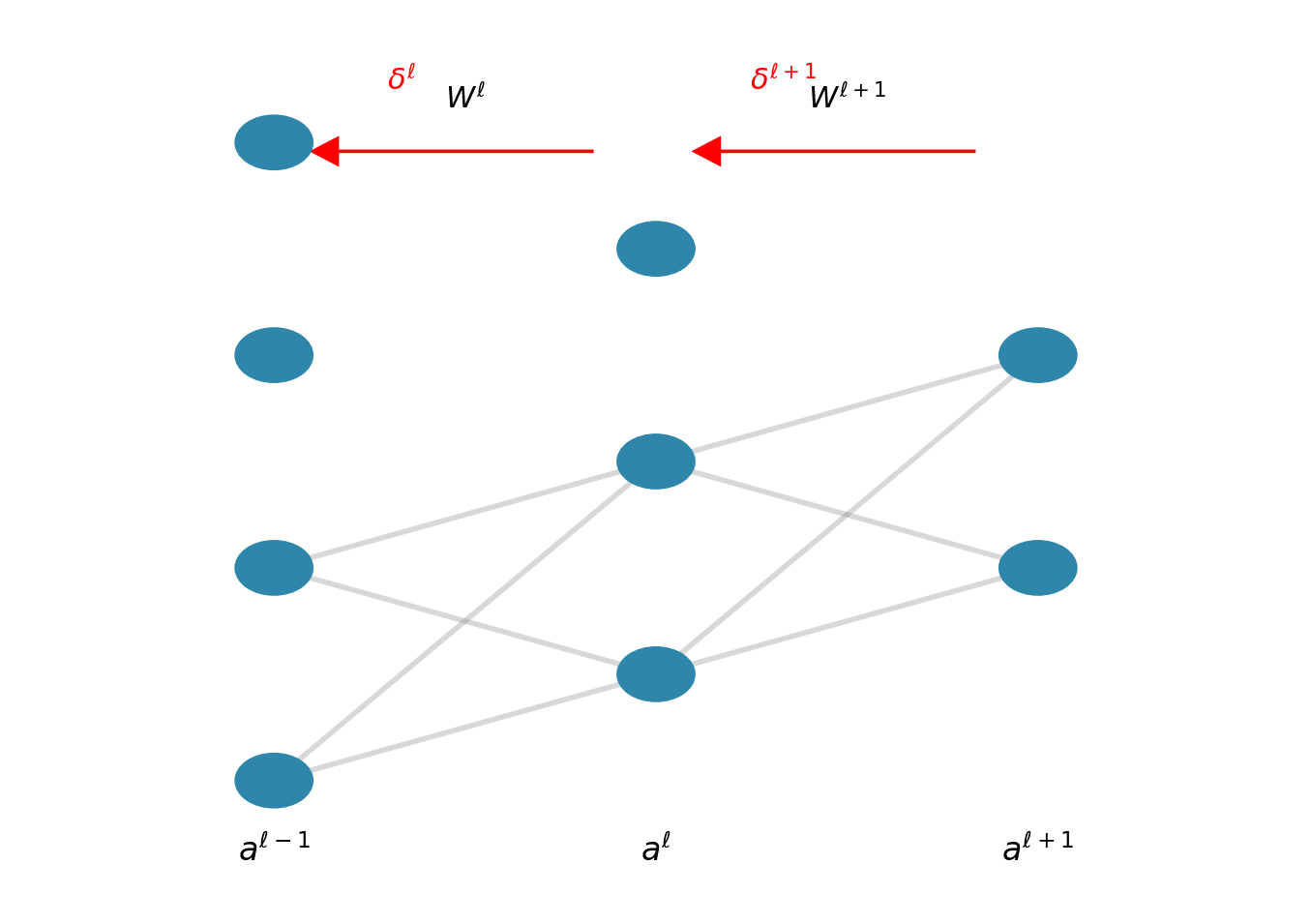
Gradient Flow: Output to Input
Given loss gradient \(\frac{\partial \mathcal{L}}{\partial y[i,j]}\), we require \(\frac{\partial \mathcal{L}}{\partial x[p,q]}\).
Dependency Analysis
Element \(x[p,q]\) contributes to output positions: \[\{y[i,j] : p-K+1 \leq i \leq p, \; q-K+1 \leq j \leq q\}\]
By chain rule: \[\frac{\partial \mathcal{L}}{\partial x[p,q]} = \sum_{i,j} \frac{\partial \mathcal{L}}{\partial y[i,j]} \cdot \frac{\partial y[i,j]}{\partial x[p,q]}\]
Since \(y[i,j] = \sum_{m,n} h[m,n] \cdot x[i+m, j+n]\):
\[\frac{\partial y[i,j]}{\partial x[p,q]} = \begin{cases} h[p-i, q-j] & \text{if } 0 \leq p-i < K, \; 0 \leq q-j < K \\ 0 & \text{otherwise} \end{cases}\]
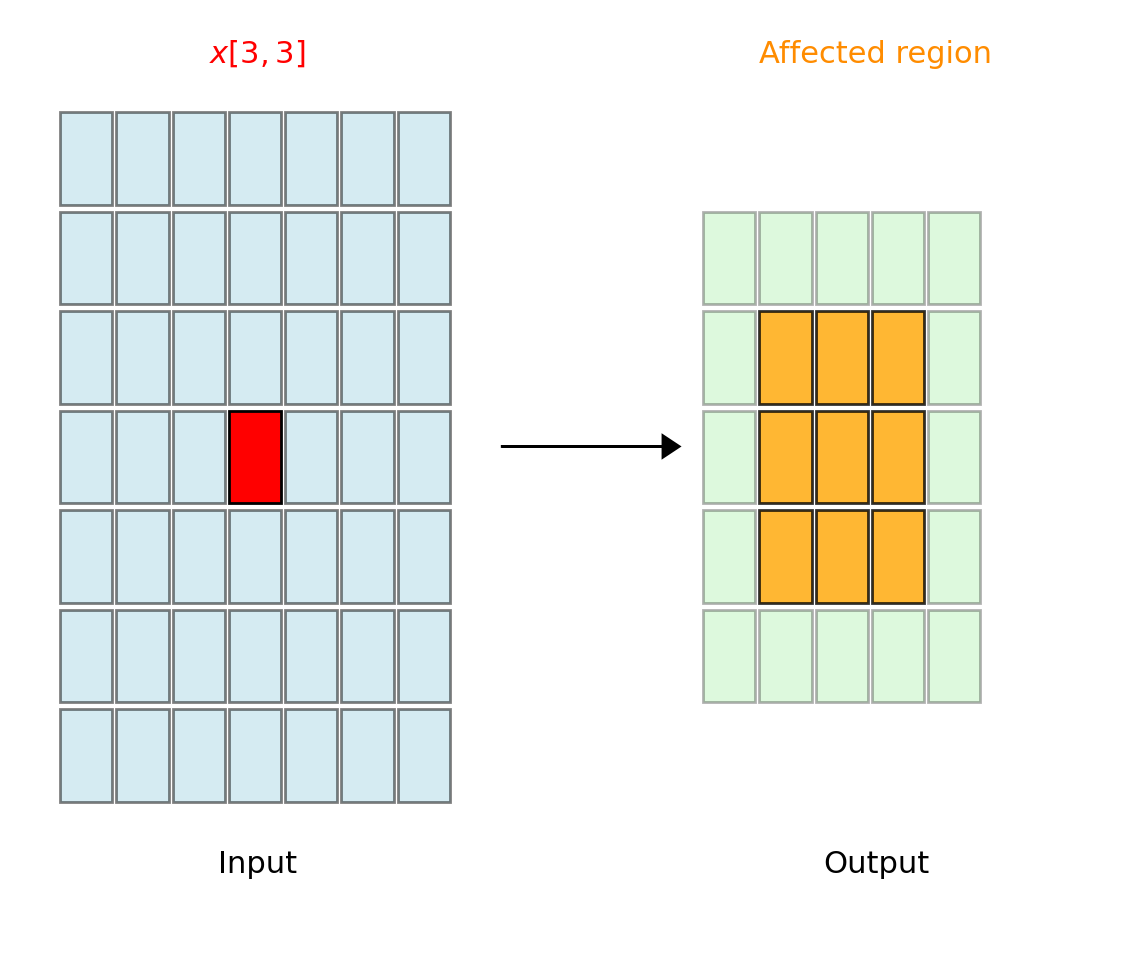
\(x[3,3]\) influences a \(3 \times 3\) region in output (for \(K=3\))
Transposed Convolution Emerges
Substituting the partial derivative:
\[\frac{\partial \mathcal{L}}{\partial x[p,q]} = \sum_{i=p-K+1}^{p} \sum_{j=q-K+1}^{q} \frac{\partial \mathcal{L}}{\partial y[i,j]} \cdot h[p-i, q-j]\]
Change of variables: \(m = p-i\), \(n = q-j\):
\[\frac{\partial \mathcal{L}}{\partial x[p,q]} = \sum_{m=0}^{K-1} \sum_{n=0}^{K-1} h[m,n] \cdot \frac{\partial \mathcal{L}}{\partial y[p-m, q-n]}\]
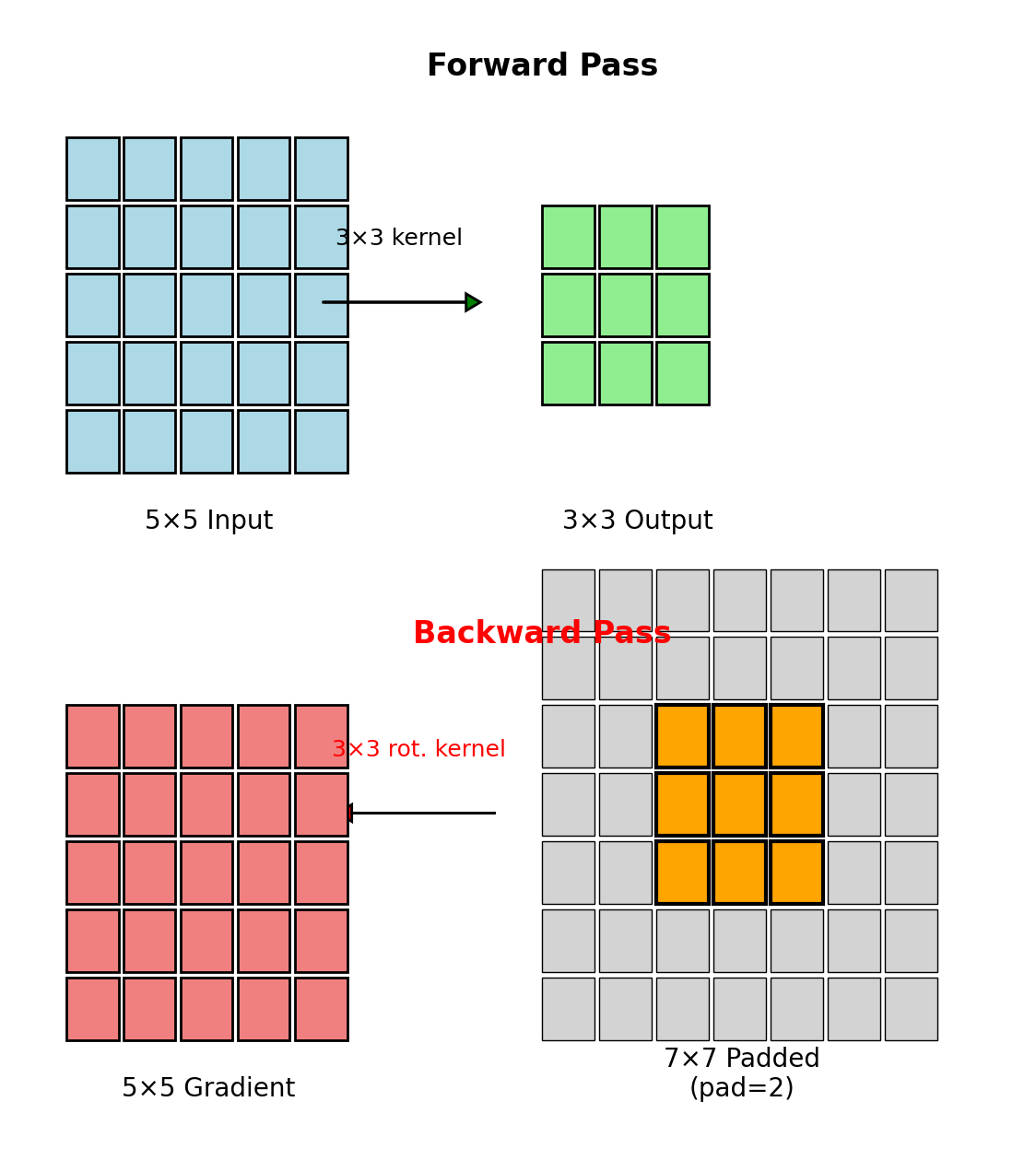
This is convolution with a rotated kernel:
\[\boxed{\frac{\partial \mathcal{L}}{\partial x} = \frac{\partial \mathcal{L}}{\partial y} * h^{\text{rot180}}}\]
where \(h^{\text{rot180}}[m,n] = h[K-1-m, K-1-n]\)
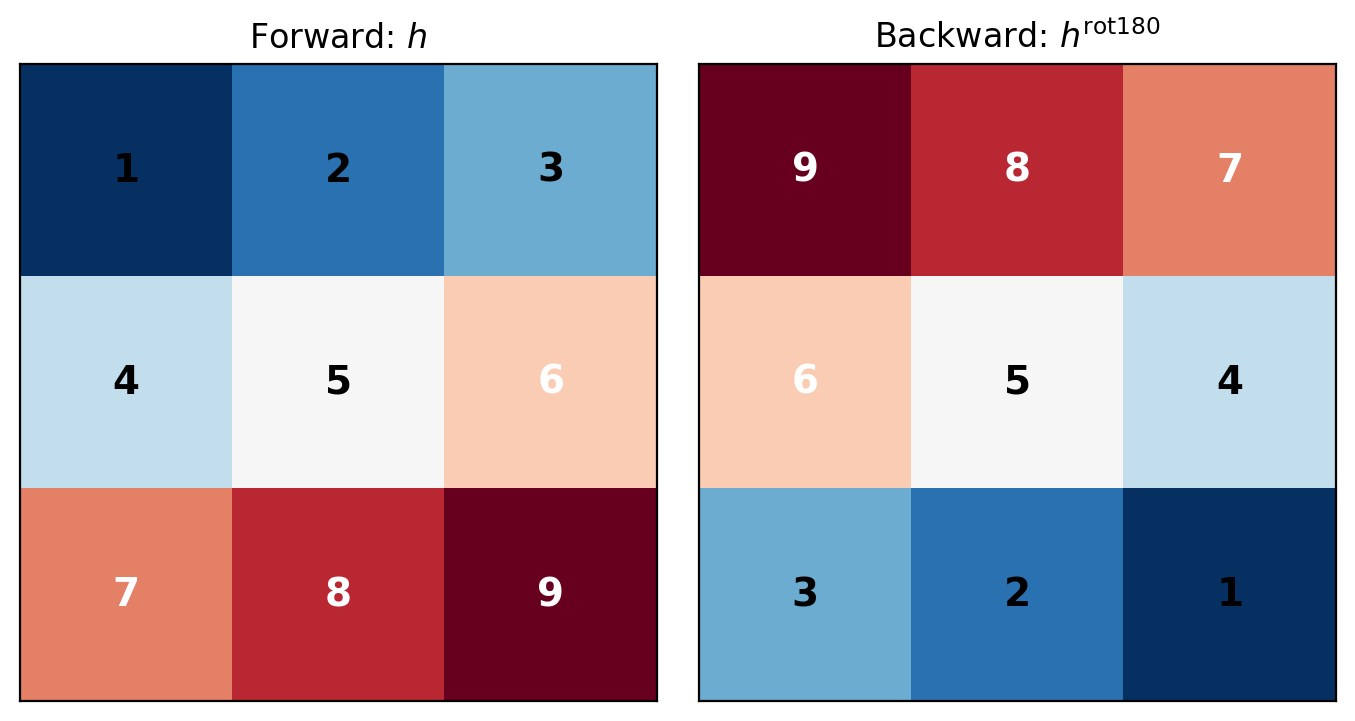
180° rotation: \(h[m,n] \rightarrow h[K-1-m, K-1-n]\)
Dimensional Analysis: Padding Requirements
Forward Pass
- Input: \(H \times W\)
- Kernel: \(K \times K\)
- Valid convolution: \((H-K+1) \times (W-K+1)\)
Backward Pass
- Gradient w.r.t. output: \((H-K+1) \times (W-K+1)\)
- Need gradient w.r.t. input: \(H \times W\)
Required Padding
To recover original dimensions: \[\text{pad} = K - 1\]
This yields “full” convolution in backward pass.
Weight Gradient Computation
Derivation
Each kernel element \(h[m,n]\) appears in computing all output positions:
\[\frac{\partial \mathcal{L}}{\partial h[m,n]} = \sum_{i,j} \frac{\partial \mathcal{L}}{\partial y[i,j]} \cdot \frac{\partial y[i,j]}{\partial h[m,n]}\]
From \(y[i,j] = \sum_{m',n'} h[m',n'] \cdot x[i+m', j+n']\):
\[\frac{\partial y[i,j]}{\partial h[m,n]} = x[i+m, j+n]\]
Therefore: \[\boxed{\frac{\partial \mathcal{L}}{\partial h[m,n]} = \sum_{i,j} \frac{\partial \mathcal{L}}{\partial y[i,j]} \cdot x[i+m, j+n]}\]
This is the correlation between input and output gradient.
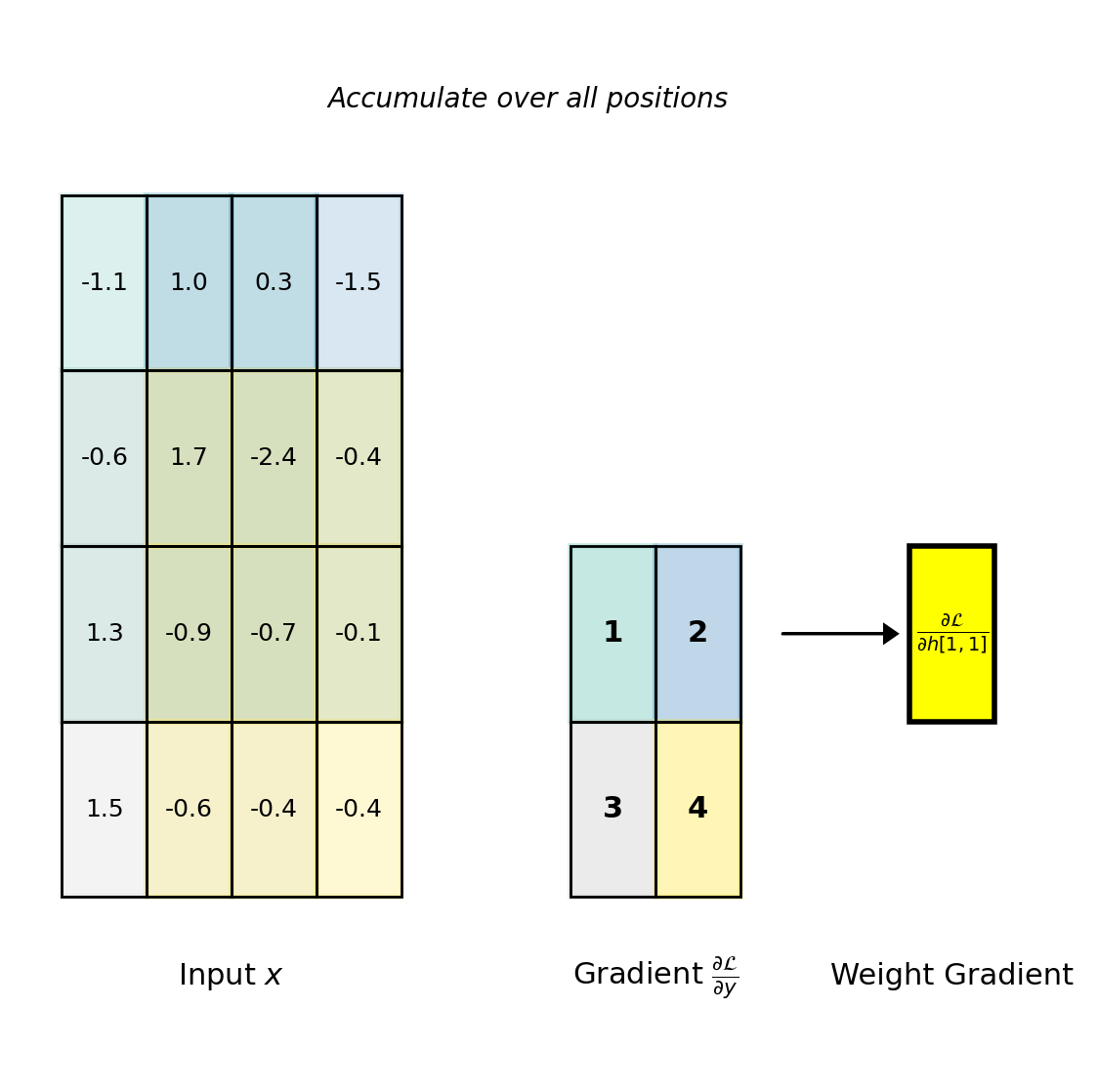
Each weight gradient accumulates contributions from all spatial positions where that weight was applied.
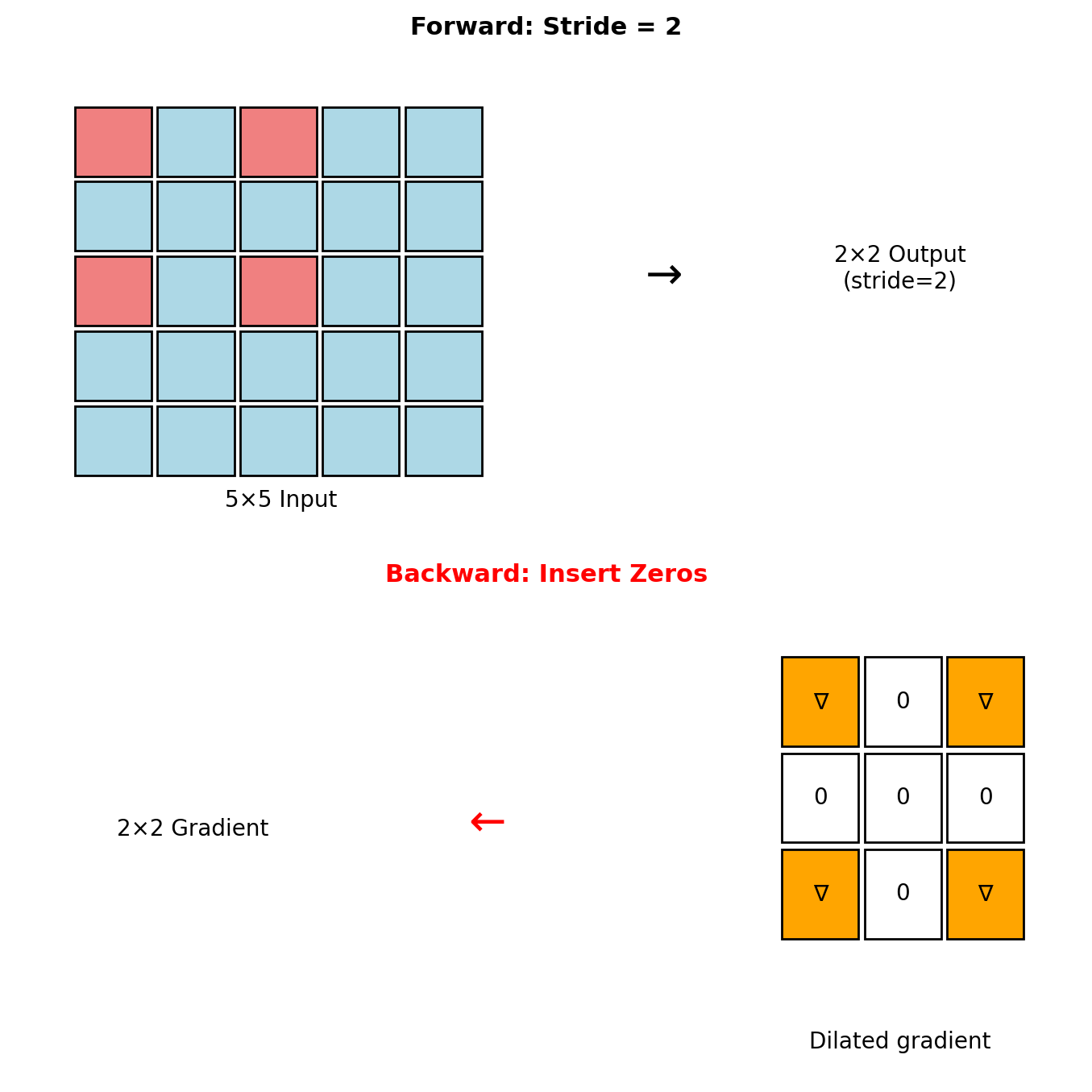
Strided Convolutions
Forward (stride \(s > 1\))
Output dimension: \[H_{\text{out}} = \left\lfloor \frac{H_{\text{in}} - K}{s} \right\rfloor + 1\]
Convolution with stride \(s\): \[y[i,j] = \sum_{m,n} h[m,n] \cdot x[si+m, sj+n]\]
Backward (fractional stride)
Insert \((s-1)\) zeros between gradient elements: \[\tilde{g}[i,j] = \begin{cases} \frac{\partial \mathcal{L}}{\partial y[i/s, j/s]} & \text{if } s|i \text{ and } s|j \\ 0 & \text{otherwise} \end{cases}\]
Then apply standard transposed convolution to \(\tilde{g}\).
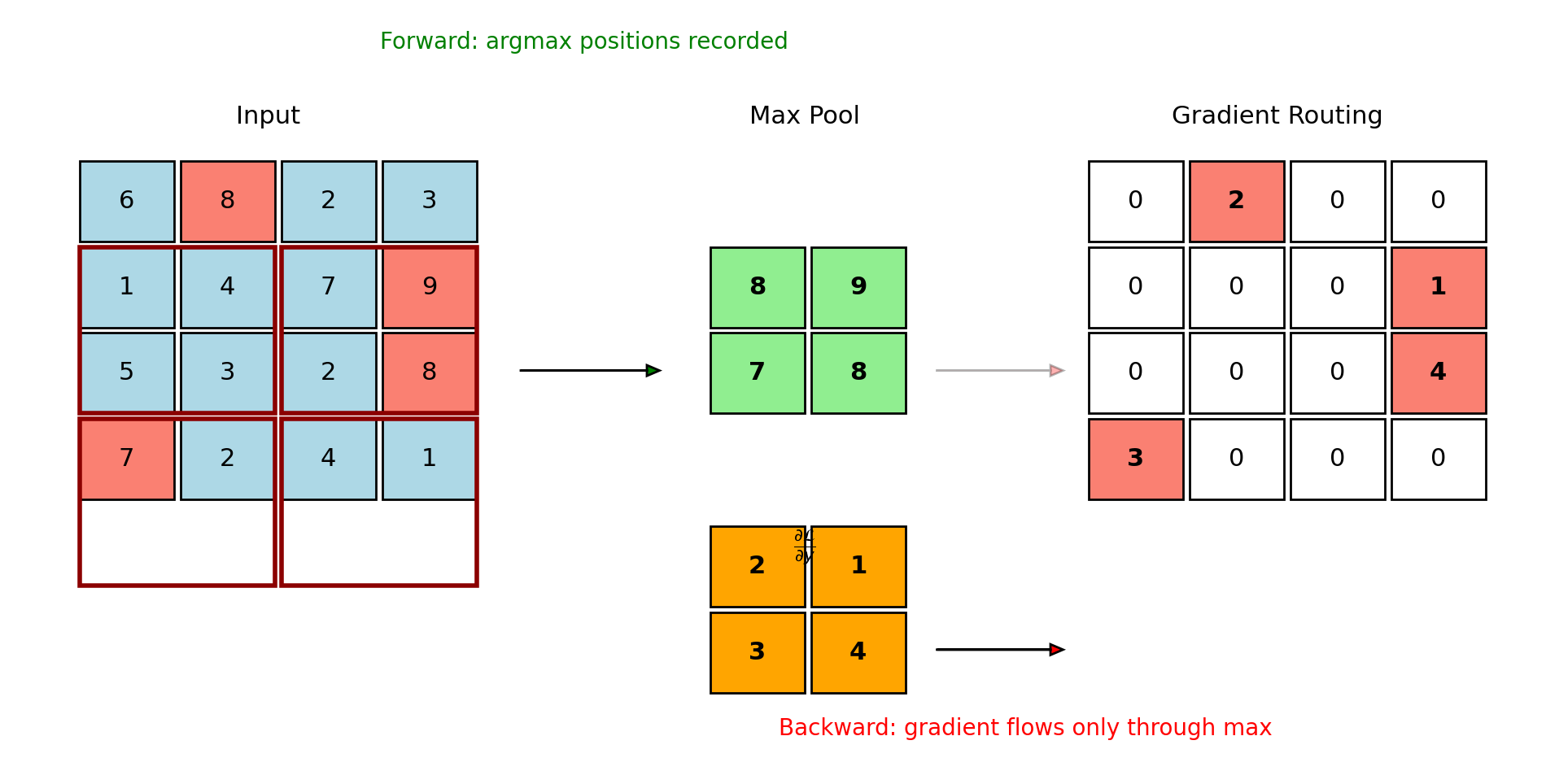
Max Pooling: Gradient Routing
Multiple Channel Processing
Tensor Dimensions
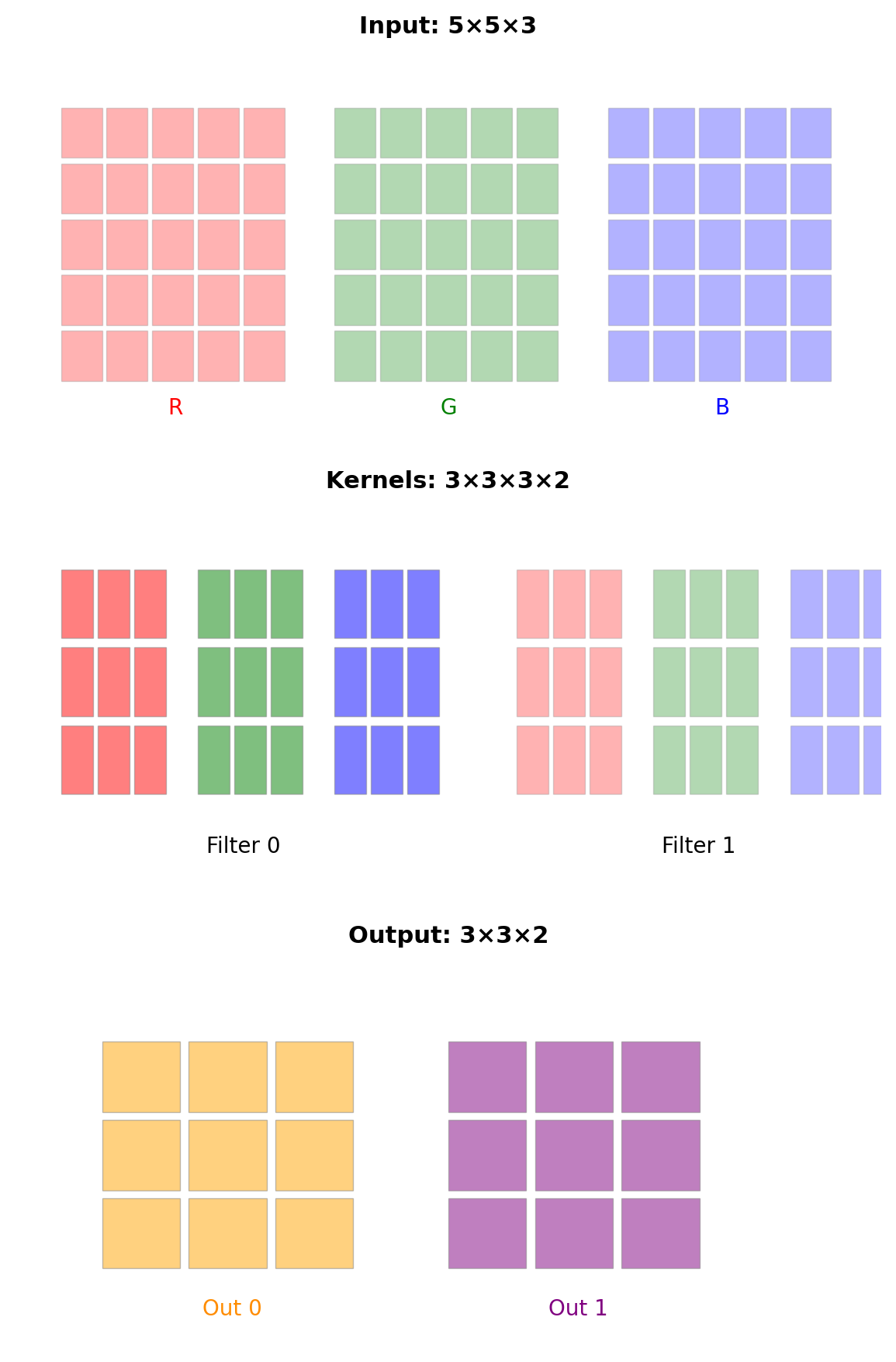
- Input: \((H, W, C_{\text{in}})\)
- Kernels: \((K, K, C_{\text{in}}, C_{\text{out}})\)
- Output: \((H', W', C_{\text{out}})\)
Forward Computation
\[y[i,j,c_o] = \sum_{c_i=0}^{C_{\text{in}}-1} \sum_{m=0}^{K-1} \sum_{n=0}^{K-1} h[m,n,c_i,c_o] \cdot x[i+m,j+n,c_i]\]
Gradient Computation
Input gradient (sum over output channels): \[\frac{\partial \mathcal{L}}{\partial x[p,q,c_i]} = \sum_{c_o=0}^{C_{\text{out}}-1} \left( \frac{\partial \mathcal{L}}{\partial y[\cdot,\cdot,c_o]} * h^{\text{rot180}}[\cdot,\cdot,c_i,c_o] \right)[p,q]\]
Weight gradient (correlation structure): \[\frac{\partial \mathcal{L}}{\partial h[m,n,c_i,c_o]} = \sum_{i,j} \frac{\partial \mathcal{L}}{\partial y[i,j,c_o]} \cdot x[i+m,j+n,c_i]\]
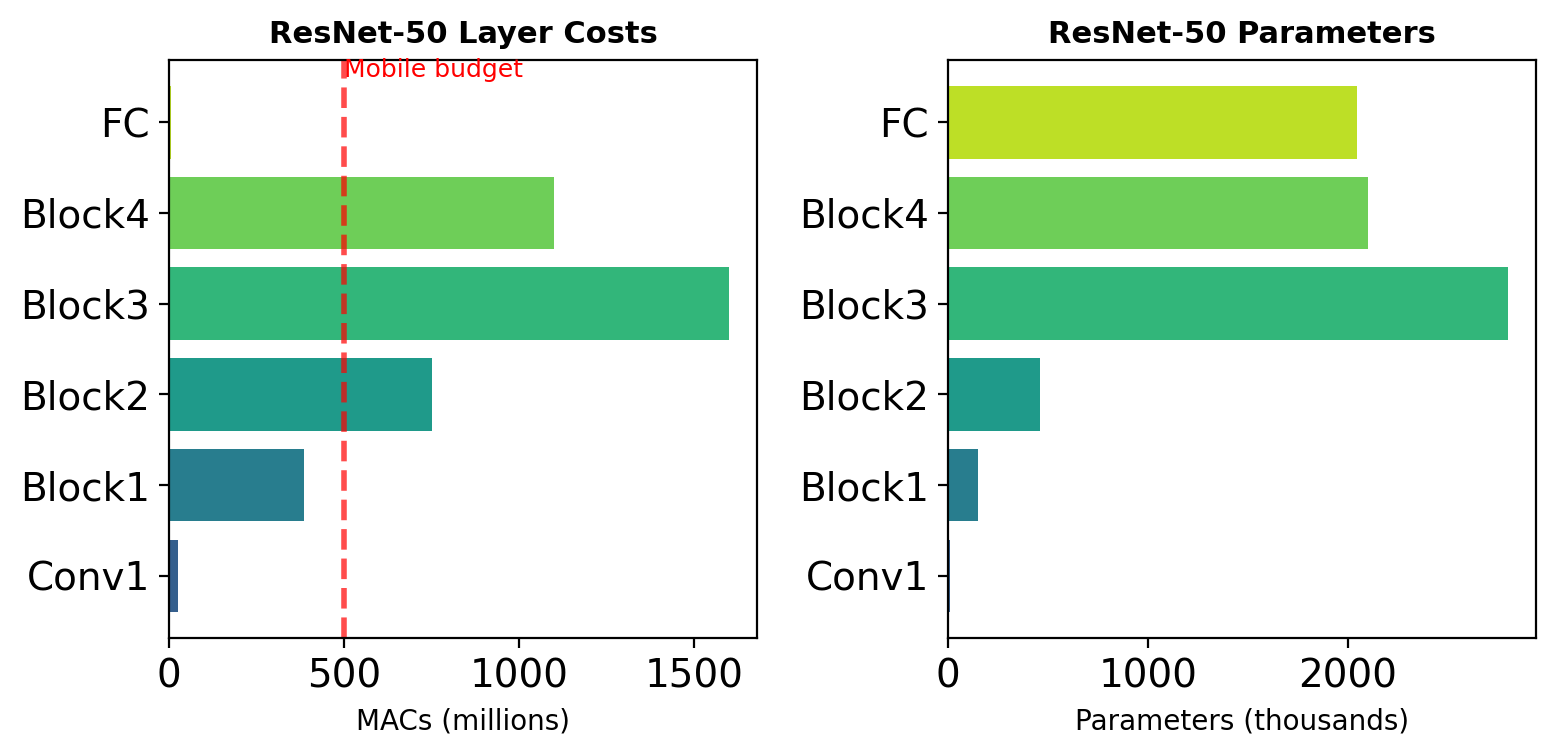
The Computational Bottleneck
Standard convolution complexity: \[O(K^2 \cdot C_{\text{in}} \cdot C_{\text{out}} \cdot H_{\text{out}} \cdot W_{\text{out}})\]
Example: Single ResNet-50 layer
- Input: 56×56×256
- 3×3 conv → 56×56×256
- Operations: 1.85 × 10⁸ MACs
- Parameters: 590K
Mobile constraint: <500M MACs total
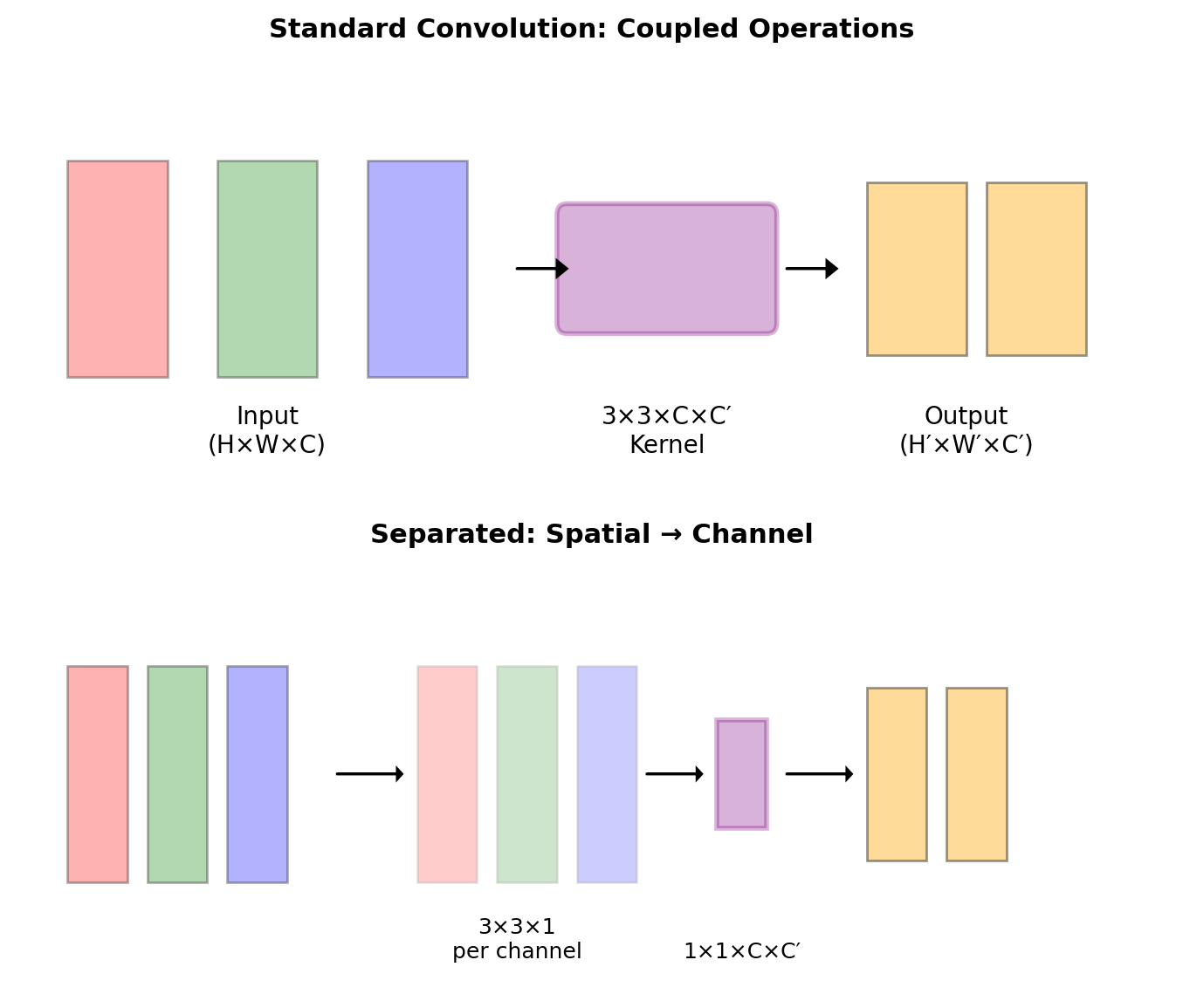
Decomposing the Convolution Operation
Standard convolution combines two operations:
- Spatial filtering: Aggregate spatial neighbors
- Channel projection: Combine channel information
\[y[i,j,c_o] = \sum_{c_i} \sum_{m,n} h[m,n,c_i,c_o] \cdot x[i+m,j+n,c_i]\]
These operations can be separated for efficiency.
\[y[i,j,c_o] = \sum_{c_i} w[c_i,c_o] \cdot \left(\sum_{m,n} h'[m,n,c_i] \cdot x[i+m,j+n,c_i]\right)\]
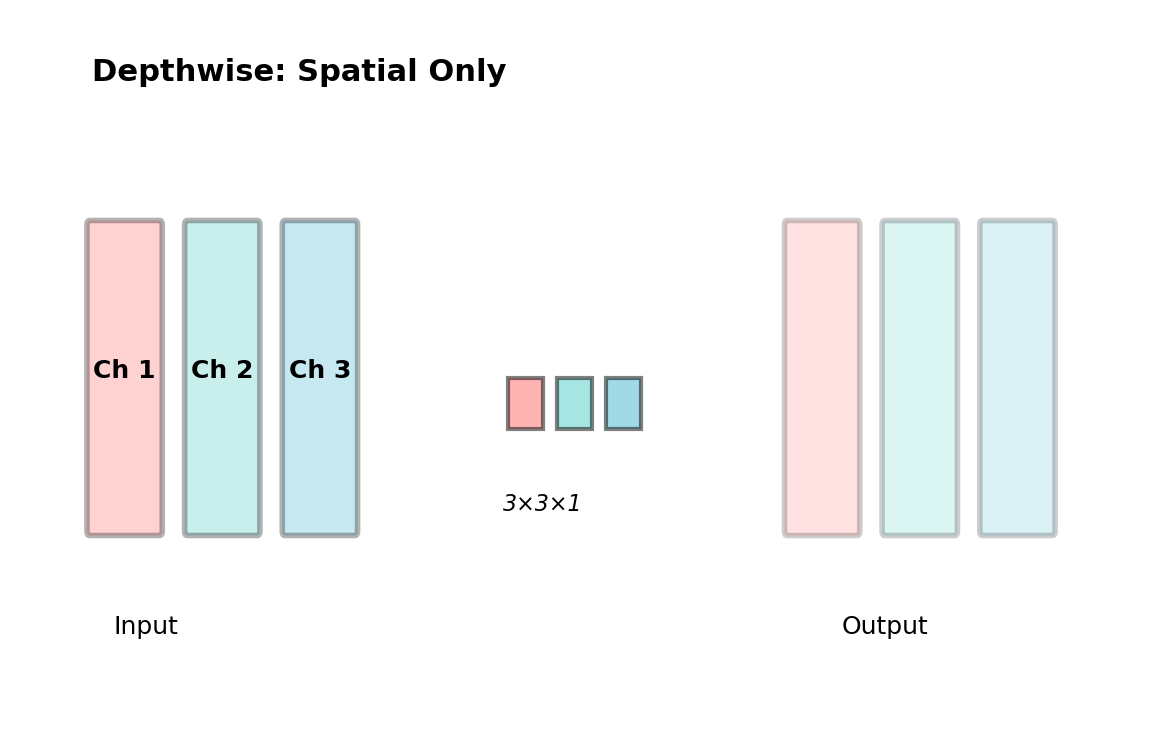
Depthwise Convolution
Key Concept: Each input channel is convolved with its own kernel
- No cross-channel mixing
- Spatial filtering only
- Dramatically reduces parameters
Parameters: \(K^2 \times C_{in}\) (vs \(K^2 \times C_{in} \times C_{out}\) for standard)
Example:
- 3×3 kernel, 16 channels
- Standard: 3×3×16×16 = 2,304 params
- Depthwise: 3×3×16 = 144 params
- 16× reduction
Pointwise (1×1) Convolution
Key Concept: Mix channels without spatial filtering
- Cross-channel information flow
- No spatial context (1×1 window)
- Linear combination of channels
Parameters: \(C_{in} \times C_{out}\)
Use Cases:
- Dimension reduction/expansion
- Feature combination
- Bottleneck layers
Example:
- 256 → 64 channels
- Only 256×64 = 16,384 params
- Preserves spatial resolution
Depthwise Separable = Best of Both
Grouped Convolution
Key Concept: Divide channels into groups
- Each group processed independently
- No cross-group communication
- Originally for AlexNet (GPU memory)
Parameters: \(\frac{K^2 \times C_{in} \times C_{out}}{g}\)
Trade-offs:
- Reduces parameters by factor of \(g\)
- Parallelizable
- Limited feature interaction (drawback)
ShuffleNet Solution:
- Add channel shuffling between grouped convolutions
- Enables cross-group information flow
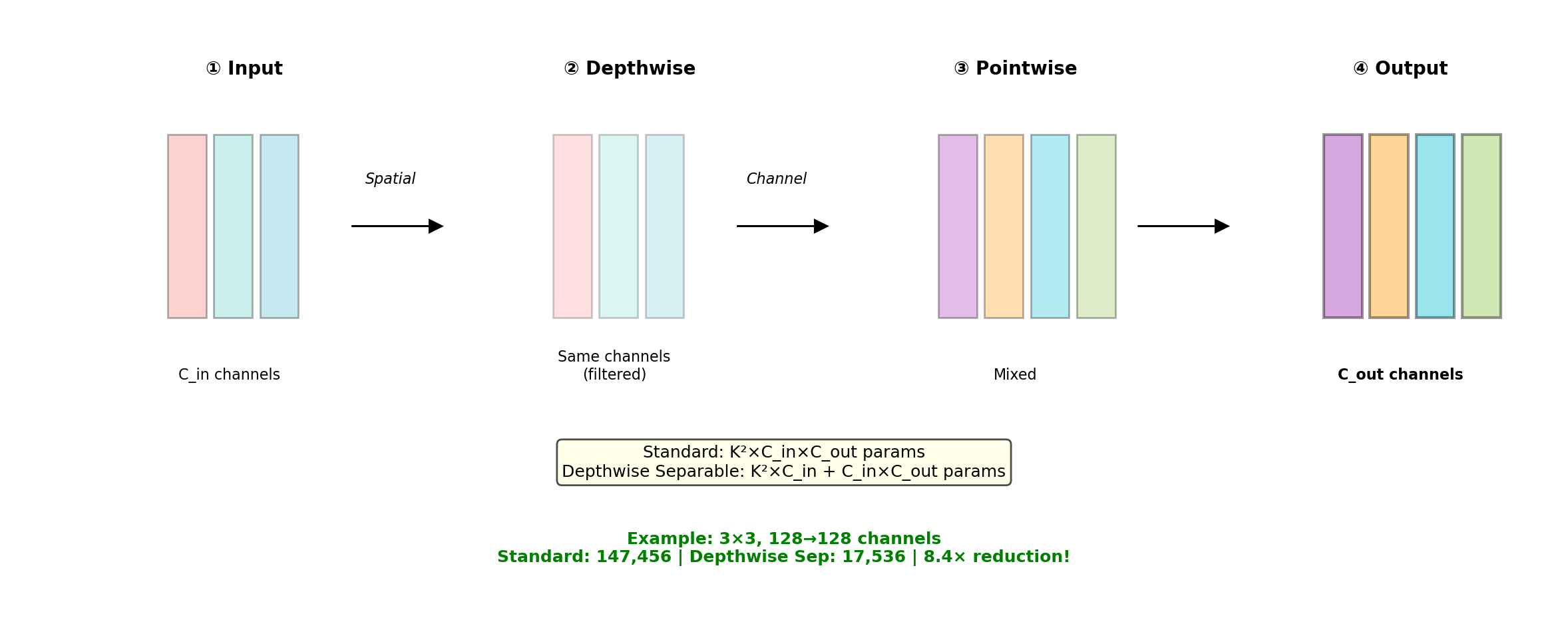
Depthwise Separable Convolution
Depthwise Convolution
Apply K×K filter to each channel independently: \[\hat{x}[i,j,c] = \sum_{m,n} h_{\text{dw}}[m,n,c] \cdot x[i+m,j+n,c]\]
Parameters: \(K^2 \cdot C_{\text{in}}\)
Pointwise Convolution
Mix channels with 1×1 convolution: \[y[i,j,c_o] = \sum_{c_i} h_{\text{pw}}[c_i,c_o] \cdot \hat{x}[i,j,c_i]\]
Parameters: \(C_{\text{in}} \cdot C_{\text{out}}\)
Reduction Factor
\[\frac{\text{Depthwise Separable}}{\text{Standard}} = \frac{K^2 C + CC'}{K^2 CC'} = \frac{1}{C'} + \frac{1}{K^2}\]

MobileNet V1 Architecture
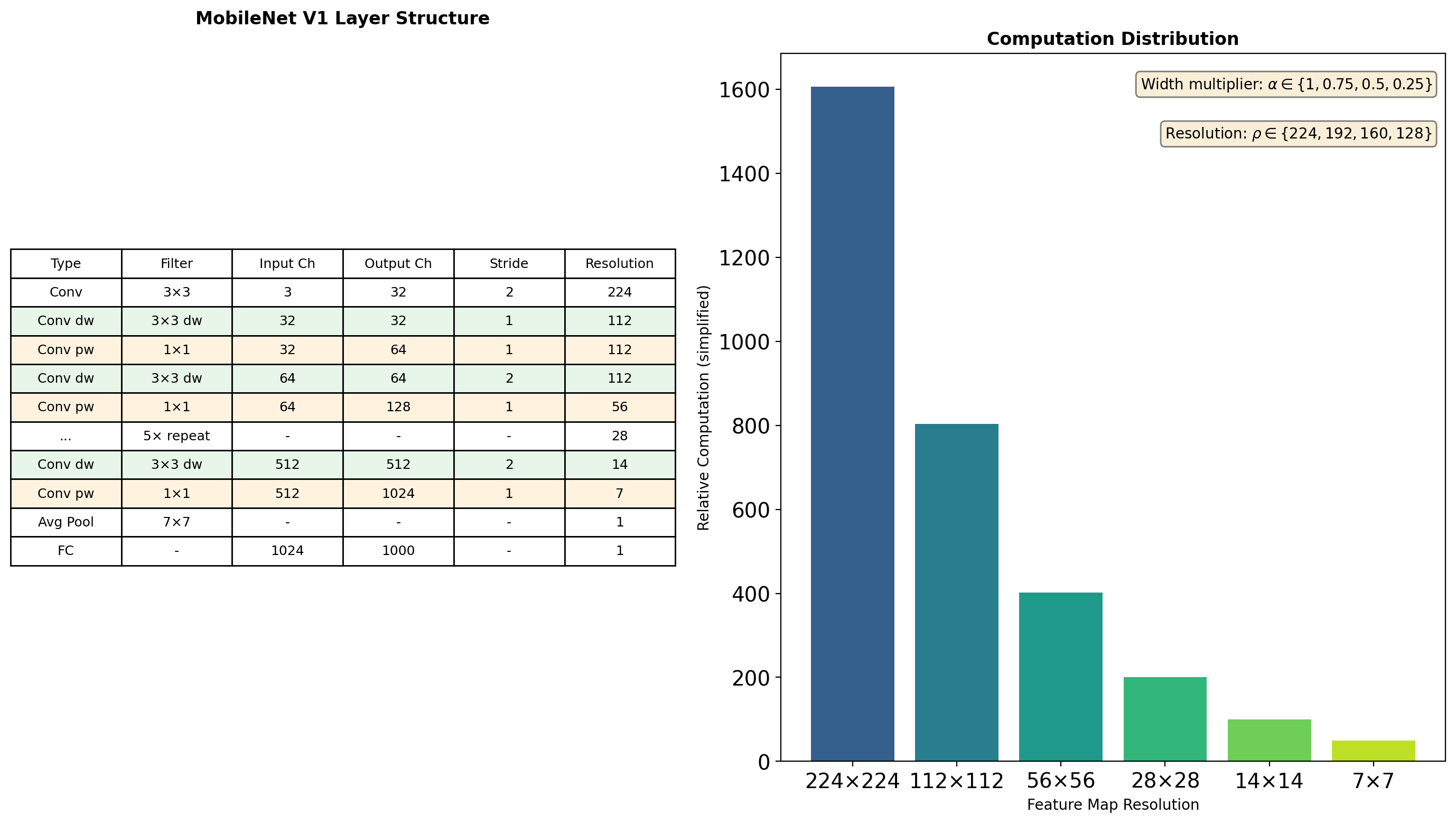
Total: 569M MACs, 4.2M parameters (vs VGG16: 15.3B MACs, 138M parameters)
MobileNet V2: Information Flow Problem
ReLU-induced Collapse
Low-dimensional ReLU causes information loss:
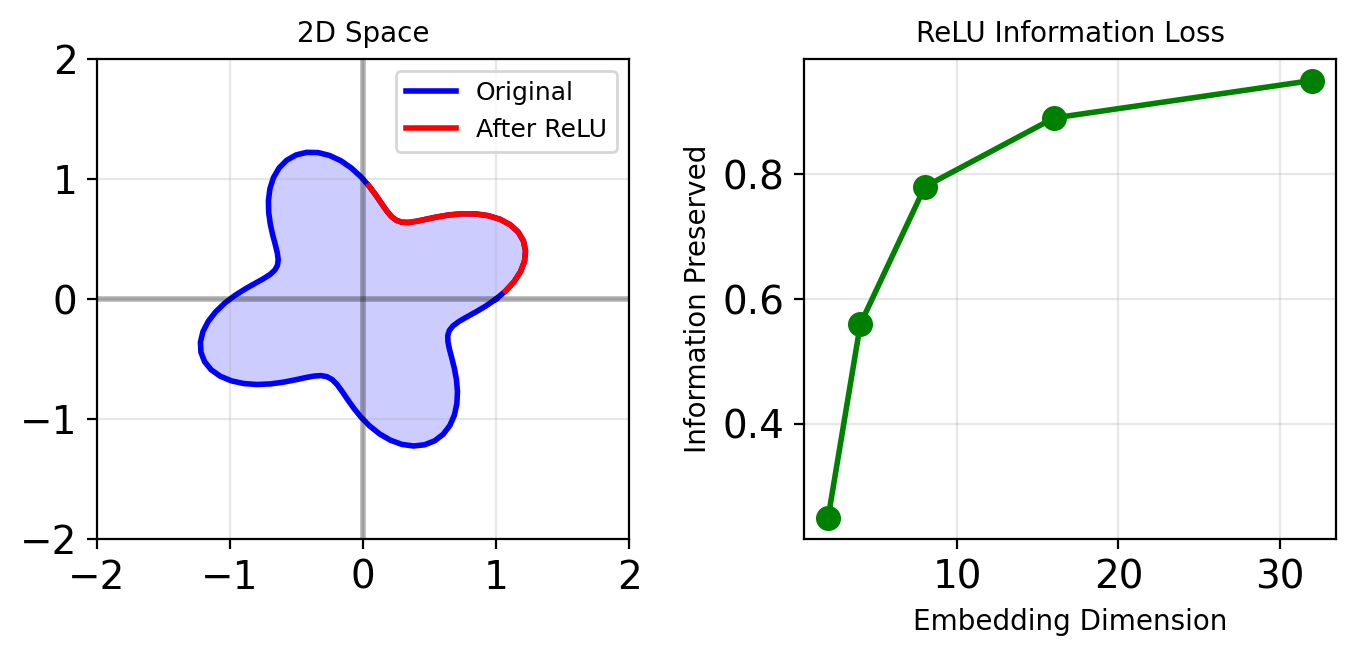
Solution
Linear bottleneck: no activation after projection
Inverted Residual Block
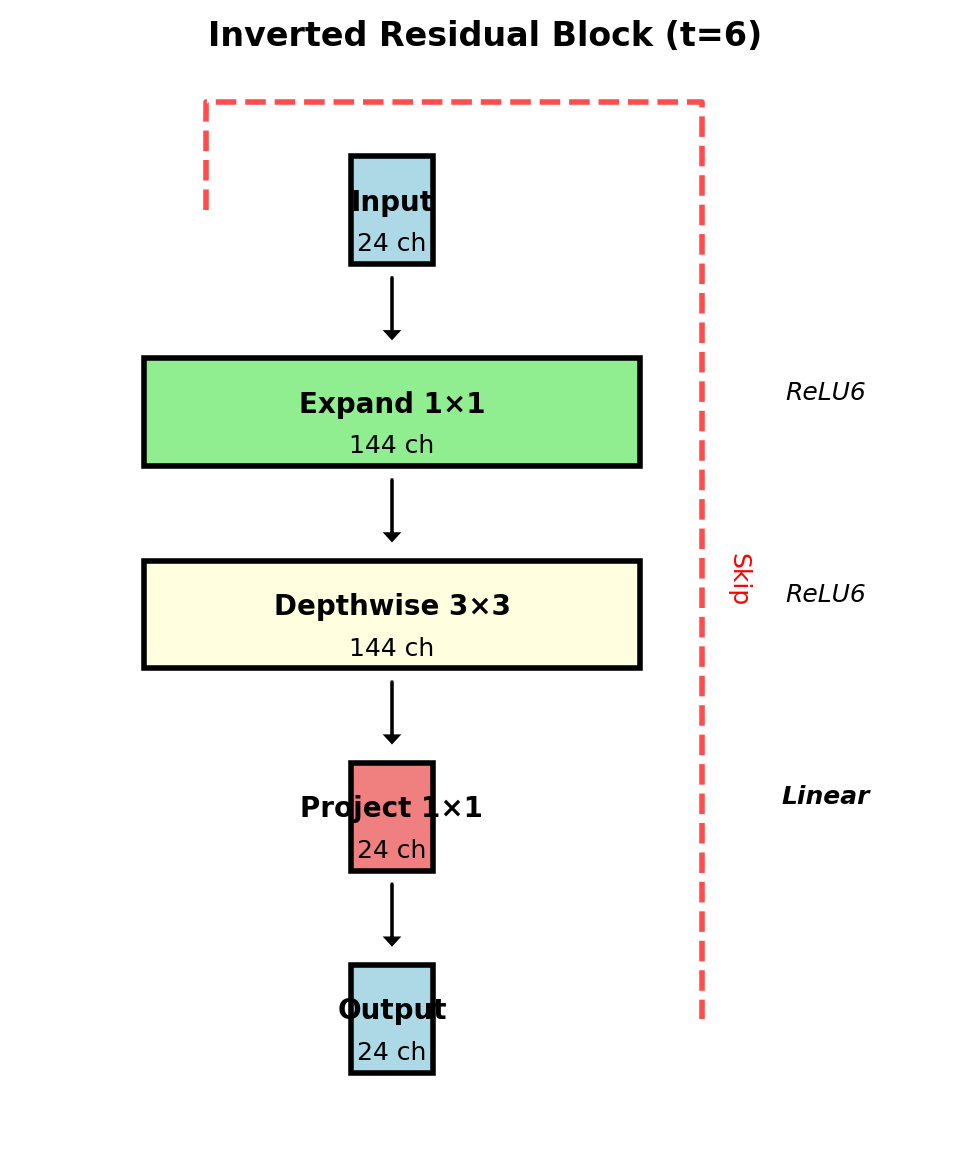
Expansion factor \(t=6\) typical
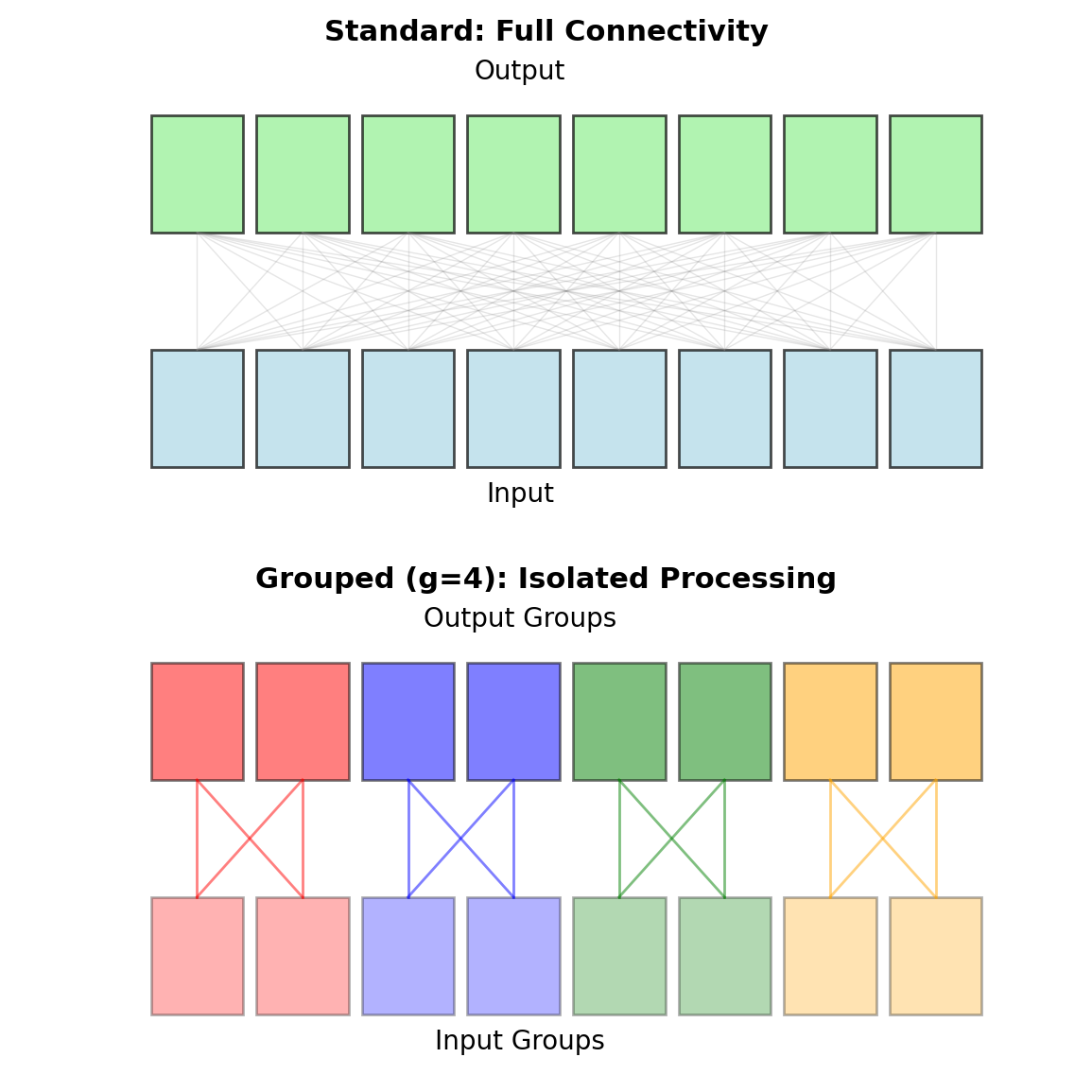
Group Convolution: Parallel Processing
Divide channels into \(g\) groups:
\[y[i,j,c_o] = \sum_{c_i \in \mathcal{G}(c_o)} \sum_{m,n} h[m,n,c_i,c_o] \cdot x[i+m,j+n,c_i]\]
where \(\mathcal{G}(c_o)\) is the input group for output \(c_o\).
# PyTorch implementation
conv_grouped = nn.Conv2d(
in_channels=128,
out_channels=128,
kernel_size=3,
groups=8 # 16 ch per group
)
# Parameters: 3×3×16×16×8 = 18,432
# Standard: 3×3×128×128 = 147,456Reduction factor = \(g\) (here: 8×)
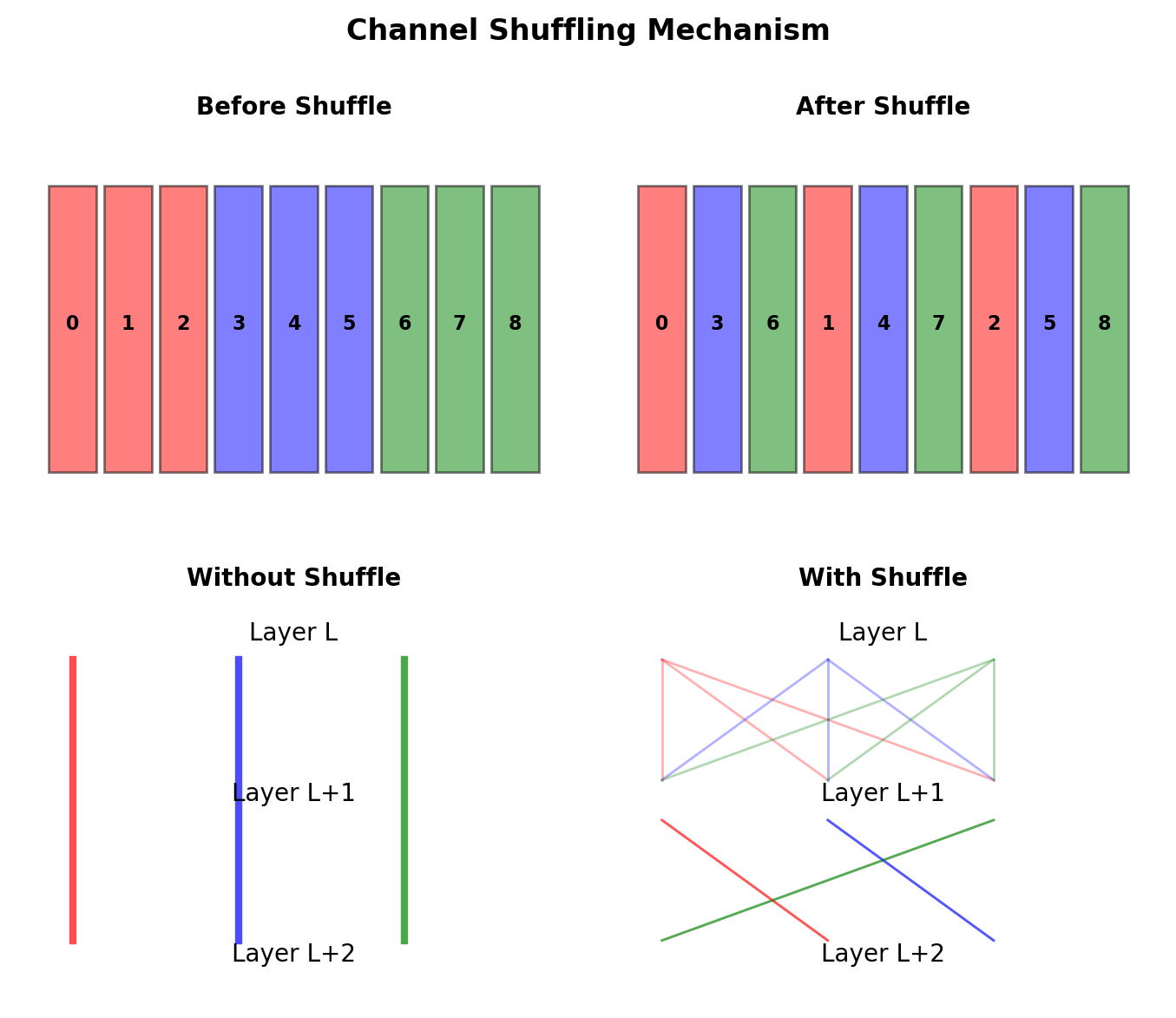
ShuffleNet: Channel Shuffling
The Problem
Groups don’t communicate → limited representation
The Solution
Deterministic channel permutation:
- Reshape: \((g, n) \rightarrow (g, n)\)
- Transpose: \((g, n) \rightarrow (n, g)\)
- Flatten: \((n, g) \rightarrow (g \cdot n)\)
ShuffleNet Architecture
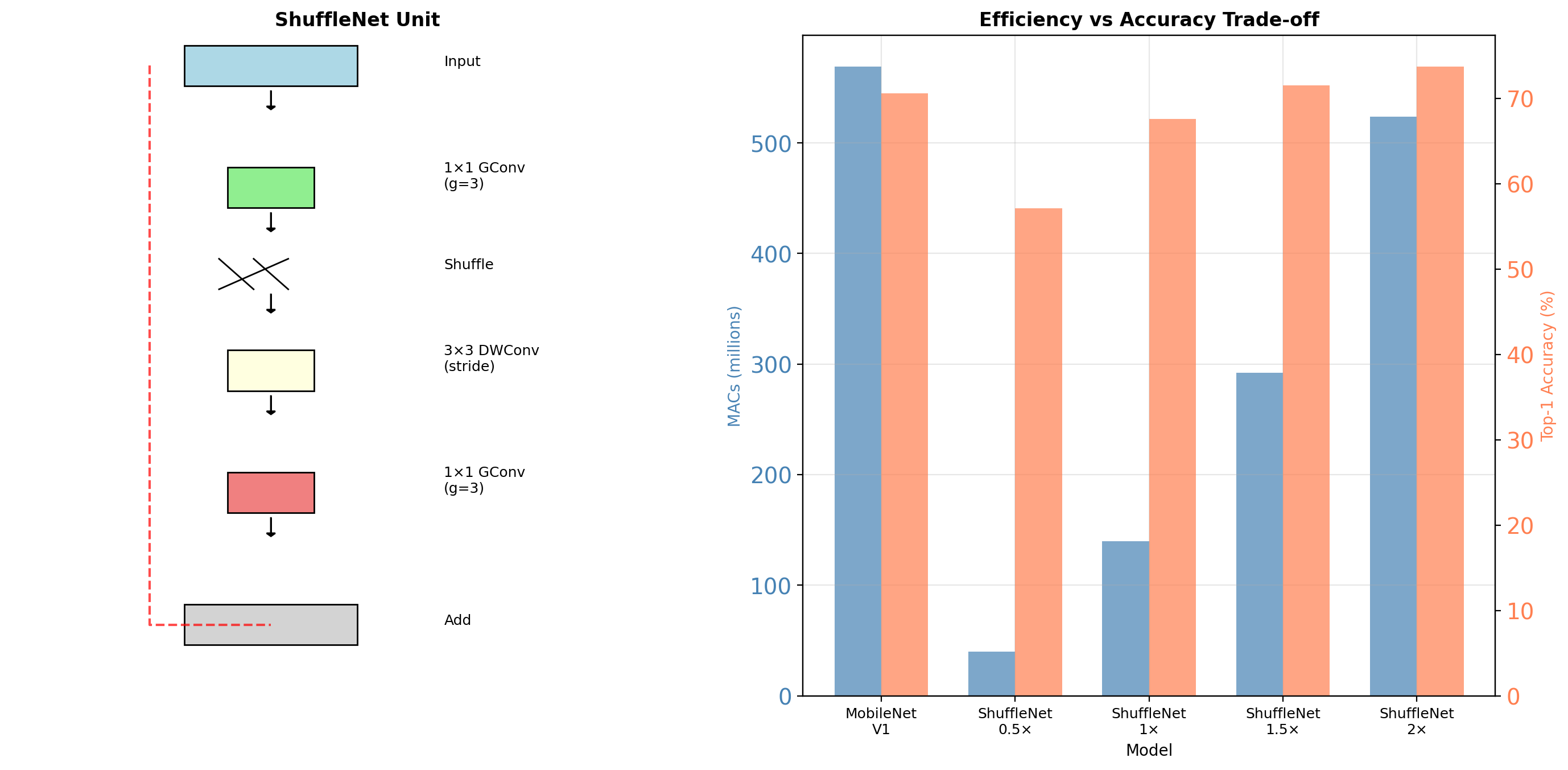
ShuffleNet 1.5× matches MobileNet accuracy with 2× fewer operations
EfficientNet: Compound Scaling
Scaling Dimensions
- Width (w): number of channels
- Depth (d): number of layers
- Resolution (r): input image size
Compound Scaling Rule
Given compound coefficient \(\phi\):
\[\begin{align} \text{depth}: \quad d &= \alpha^\phi \\ \text{width}: \quad w &= \beta^\phi \\ \text{resolution}: \quad r &= \gamma^\phi \end{align}\]
Constraint: \(\alpha \cdot \beta^2 \cdot \gamma^2 \approx 2\)
(FLOPS \(\propto\) width² × resolution²)
For EfficientNet: \(\alpha = 1.2\), \(\beta = 1.1\), \(\gamma = 1.15\)
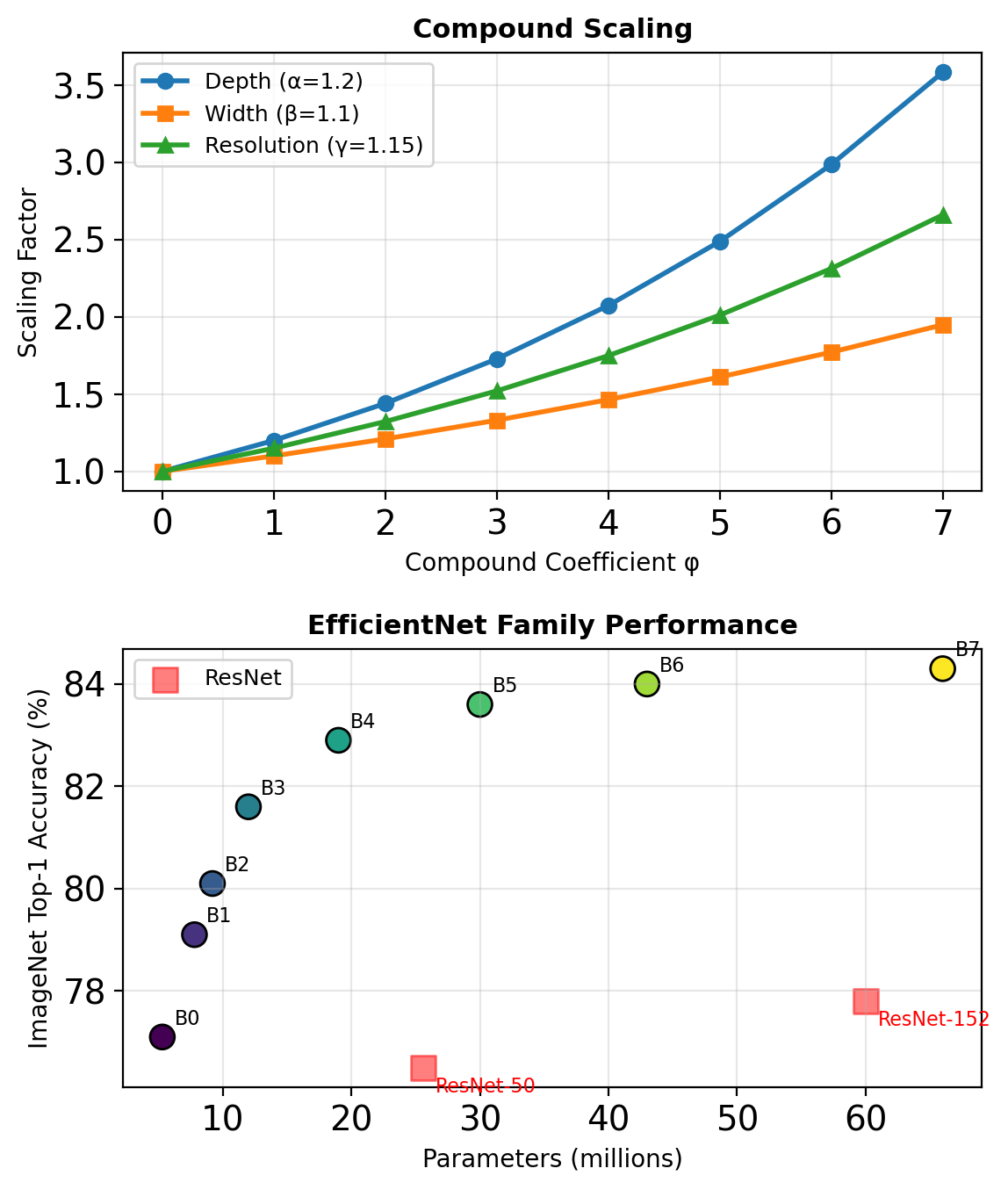
Hardware-Aware Architecture Design
MobileNetV3: Platform-Specific Optimization
Discovered through hardware-aware NAS:
- Redesigned expensive layers
- SE blocks where beneficial
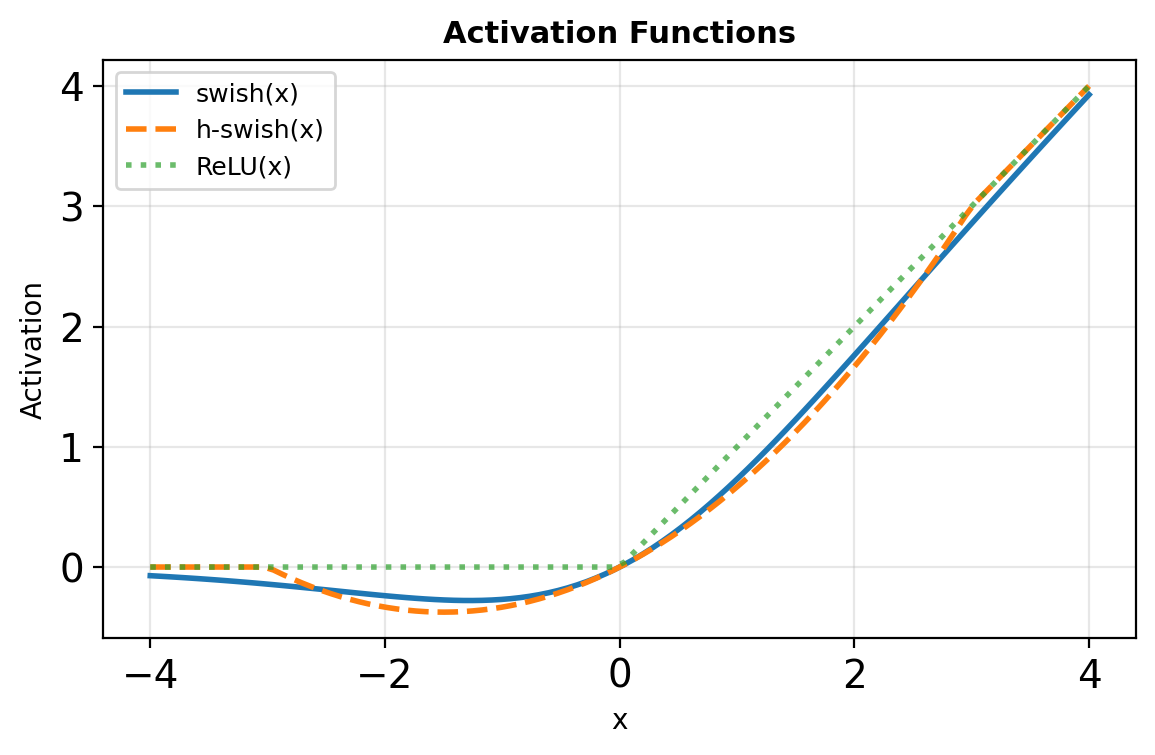
- Hard-swish activation
\[h\text{-}swish(x) = x \cdot \frac{\text{ReLU6}(x+3)}{6}\]
Approximates swish but cheaper:
- No exponential operations
- Bounded output range
- Piecewise linear
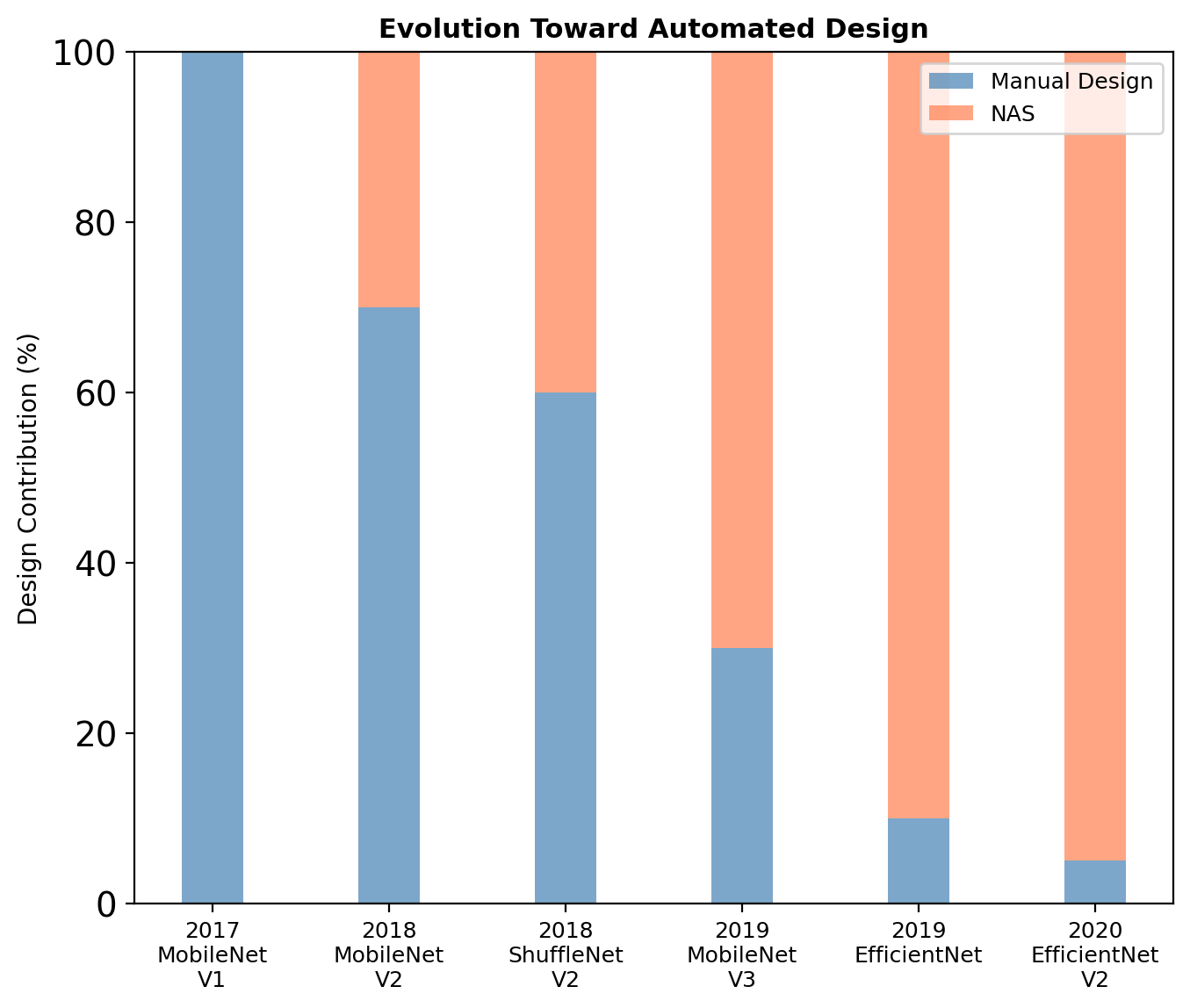
Architecture Search Space Evolution
Latest Architectures
ConvNeXt (2022): “Modernized” ResNet with depthwise conv, larger kernels (7×7), and transformer-inspired designs. Achieves 87.8% ImageNet with standard convolutions.
EfficientNetV2 (2021): Progressive training with Fused-MBConv blocks. Trains 5-11× faster than V1.
Measuring Efficiency: Beyond FLOPs
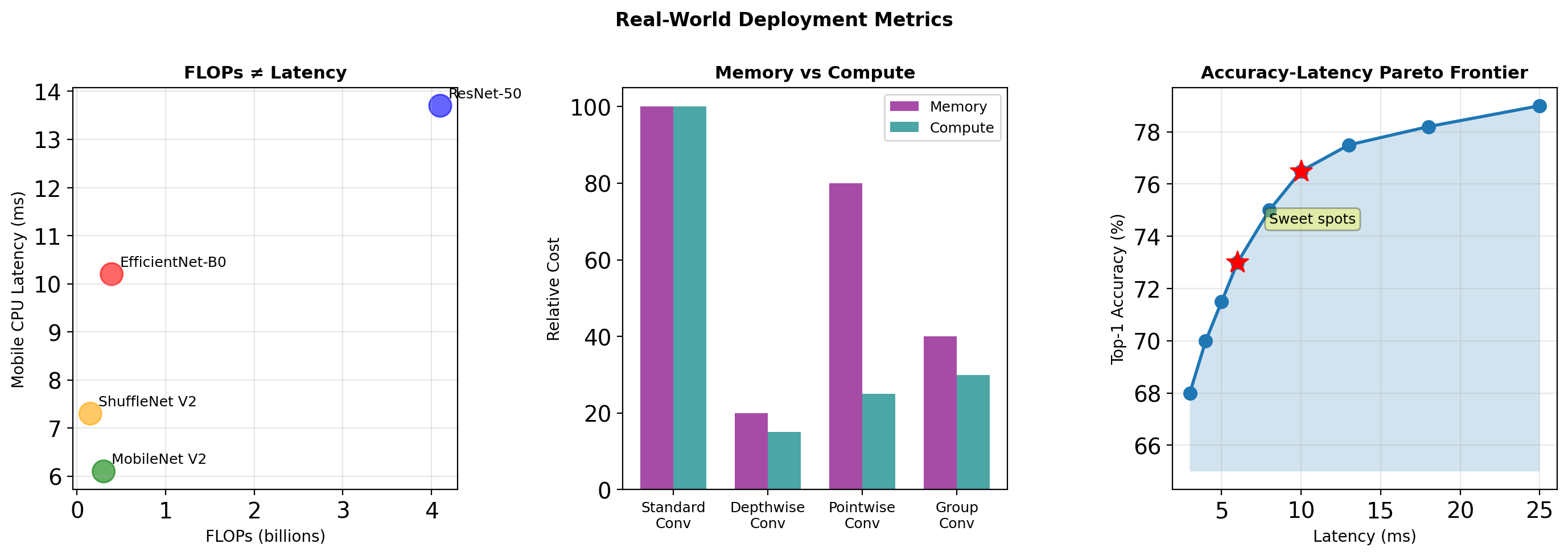
Memory bandwidth often dominates latency on edge devices, not arithmetic operations
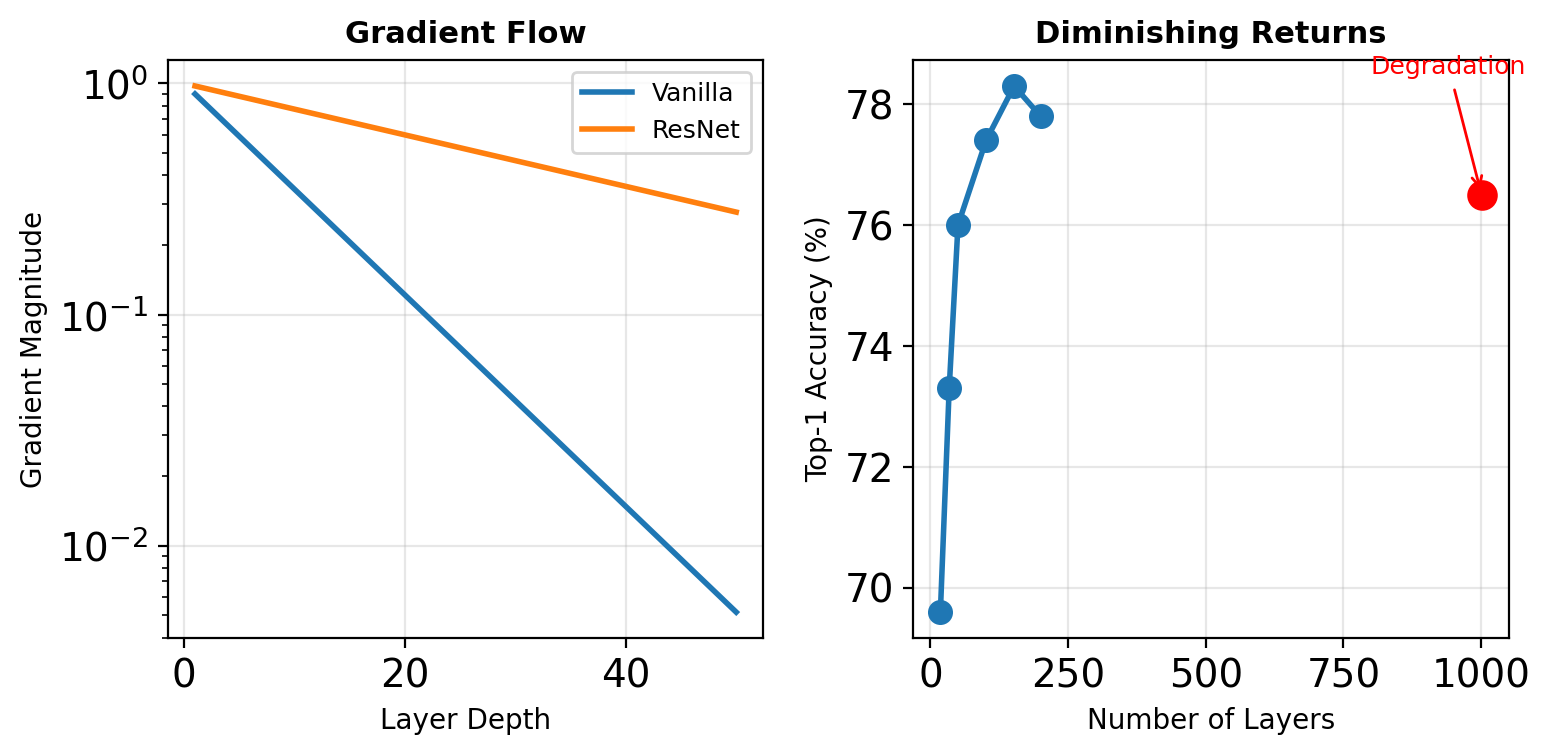
The Vanishing Gradient Problem Revisited
Gradient Magnitude Decay
For a network with \(L\) layers: \[\frac{\partial \mathcal{L}}{\partial x_1} = \prod_{\ell=1}^{L} \frac{\partial f_\ell}{\partial x_{\ell-1}}\]
If \(\left|\frac{\partial f_\ell}{\partial x_{\ell-1}}\right| < 1\): \[\left|\frac{\partial \mathcal{L}}{\partial x_1}\right| \approx \gamma^L \rightarrow 0\]
ResNet Solution
Skip connections: \(x_\ell = \mathcal{F}_\ell(x_{\ell-1}) + x_{\ell-1}\)
However, ResNet-1001 performs worse than ResNet-101.
ResNet Information Flow Analysis
Additive Identity Mapping
Forward: \[x_\ell = \mathcal{F}_\ell(x_{\ell-1}) + x_{\ell-1}\]
Backward: \[\frac{\partial \mathcal{L}}{\partial x_{\ell-1}} = \frac{\partial \mathcal{L}}{\partial x_\ell} \left(1 + \frac{\partial \mathcal{F}_\ell}{\partial x_{\ell-1}}\right)\]
During training:
- Gradients split between paths
- Information “competition”
- Many paths contribute little
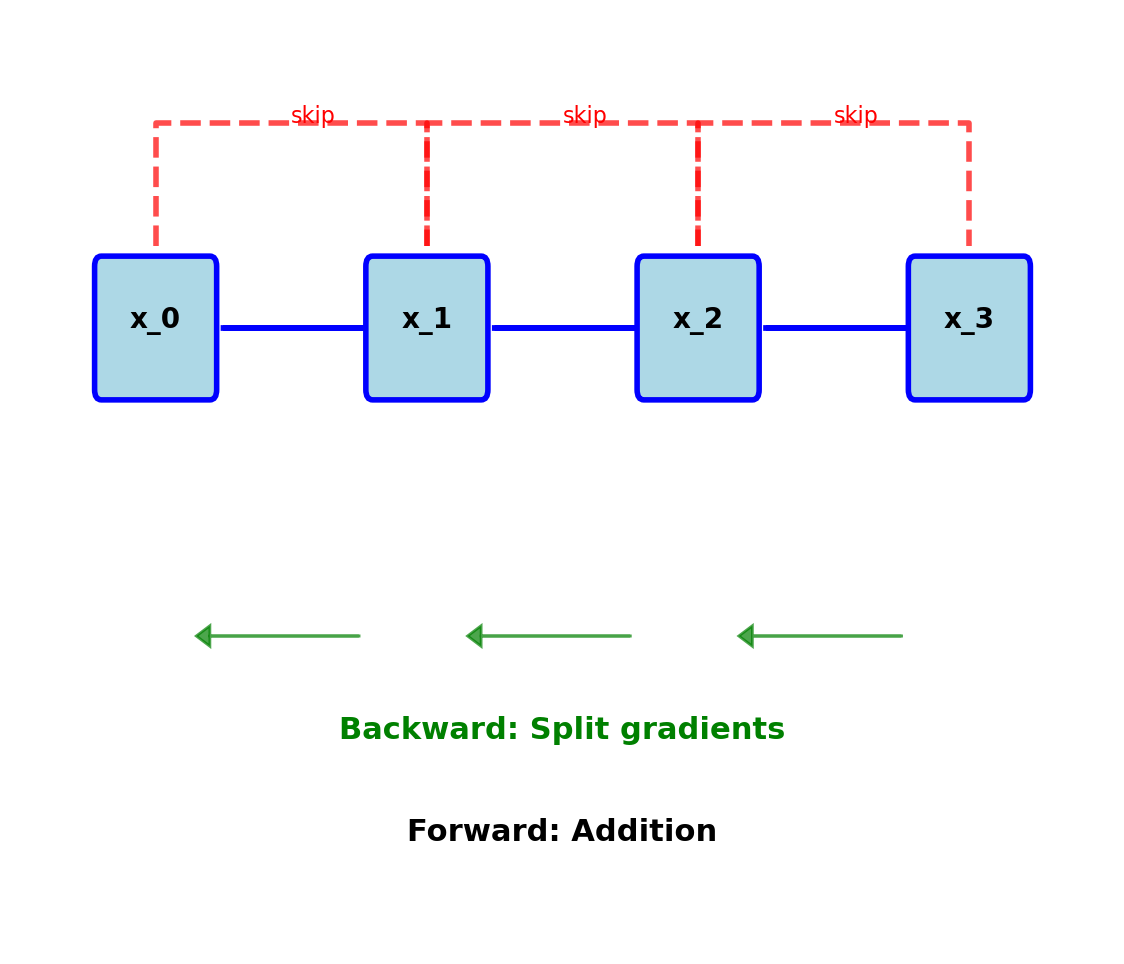
Addition can wash out earlier features
DenseNet Core Insight
Concatenative Connections
Instead of addition: \[x_\ell = H_\ell([x_0, x_1, ..., x_{\ell-1}])\]
where \([\cdot]\) denotes concatenation.
Direct connections: Layer \(\ell\) receives feature maps from all preceding layers
Gradient flow: \[\frac{\partial \mathcal{L}}{\partial x_i} = \frac{\partial \mathcal{L}}{\partial x_L} \frac{\partial x_L}{\partial x_i} + \sum_{j=i+1}^{L-1} \frac{\partial \mathcal{L}}{\partial x_j} \frac{\partial x_j}{\partial x_i}\]
\(L(L+1)/2\) connections in an \(L\)-layer network
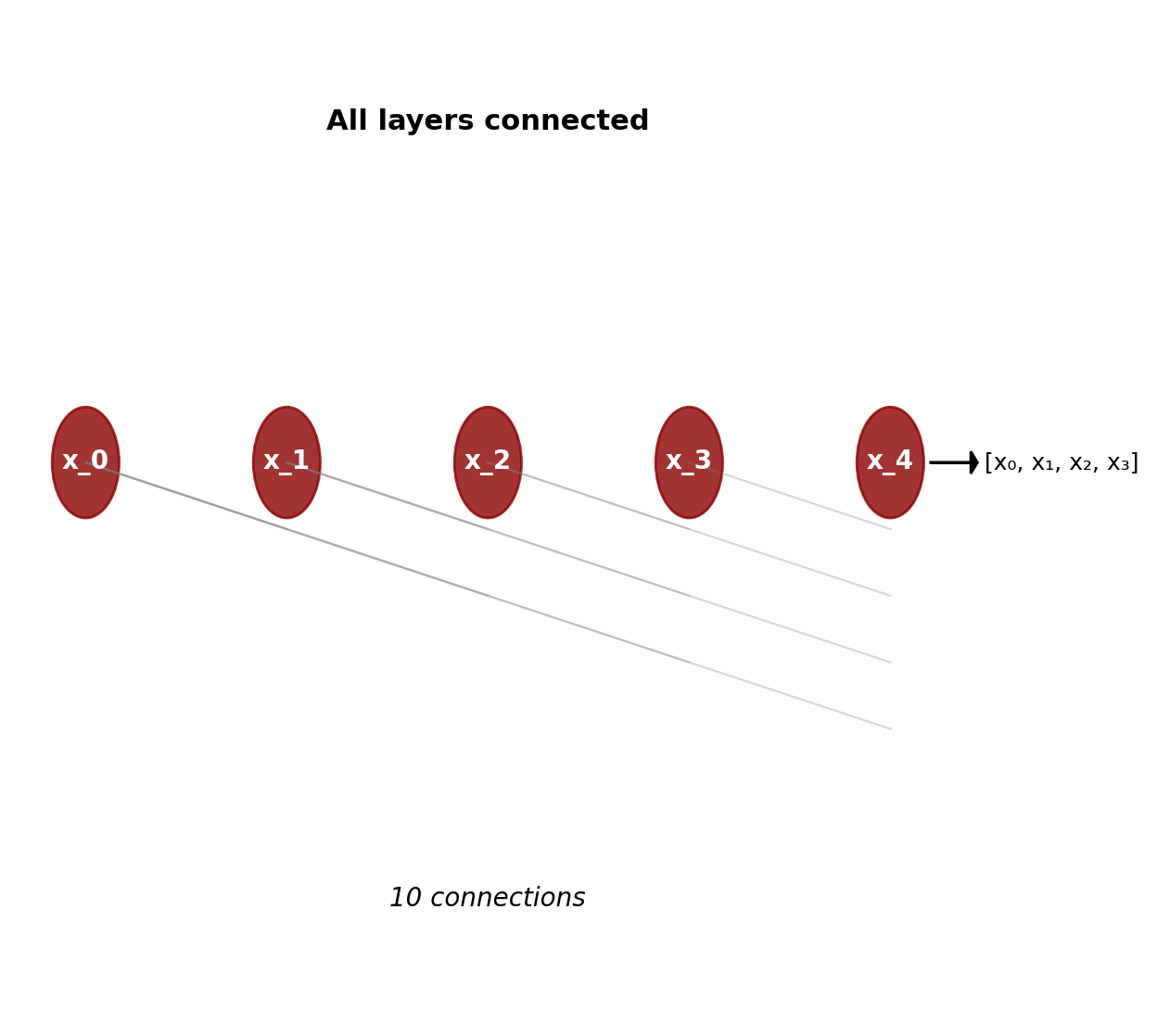
Dense Block Architecture
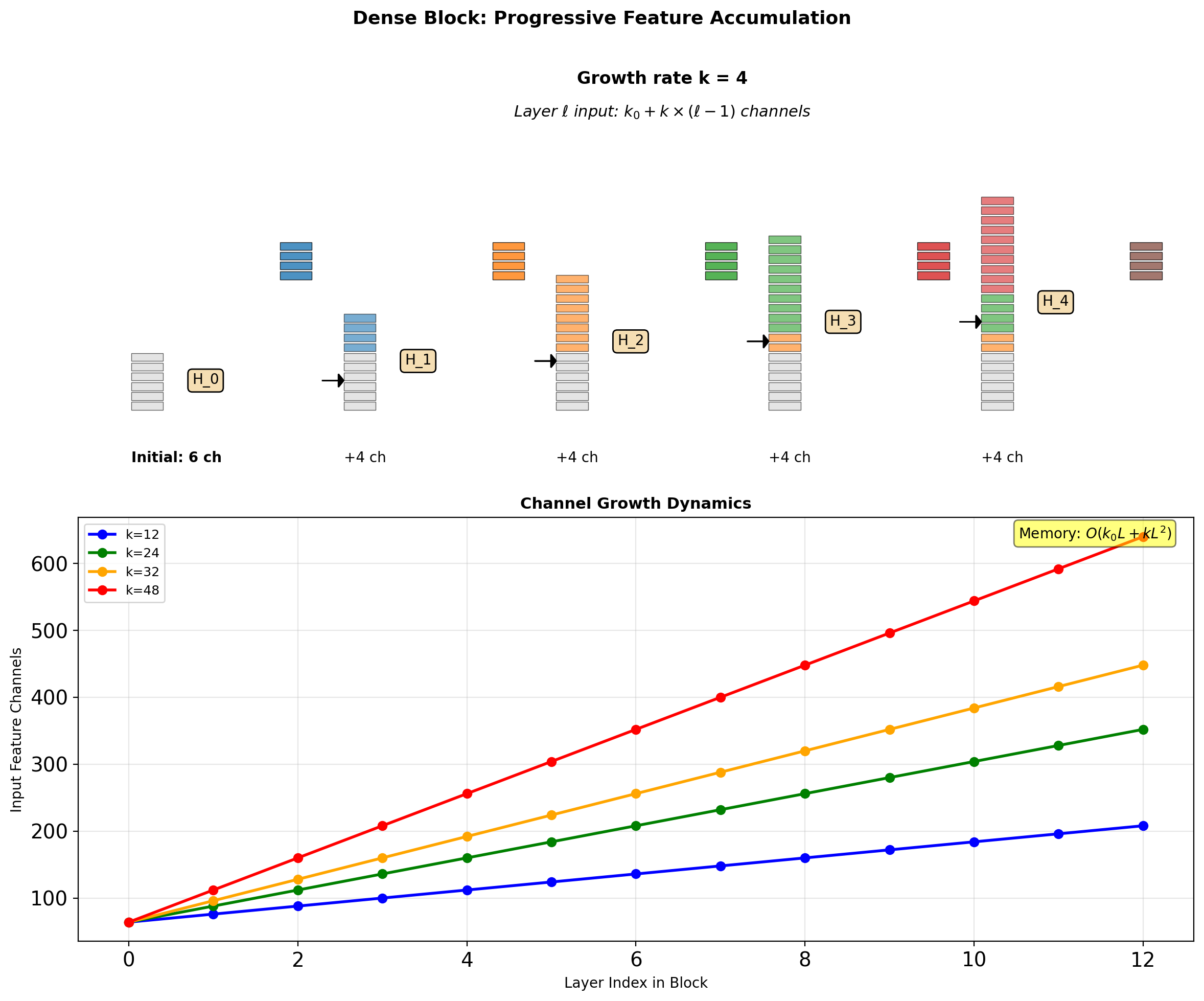
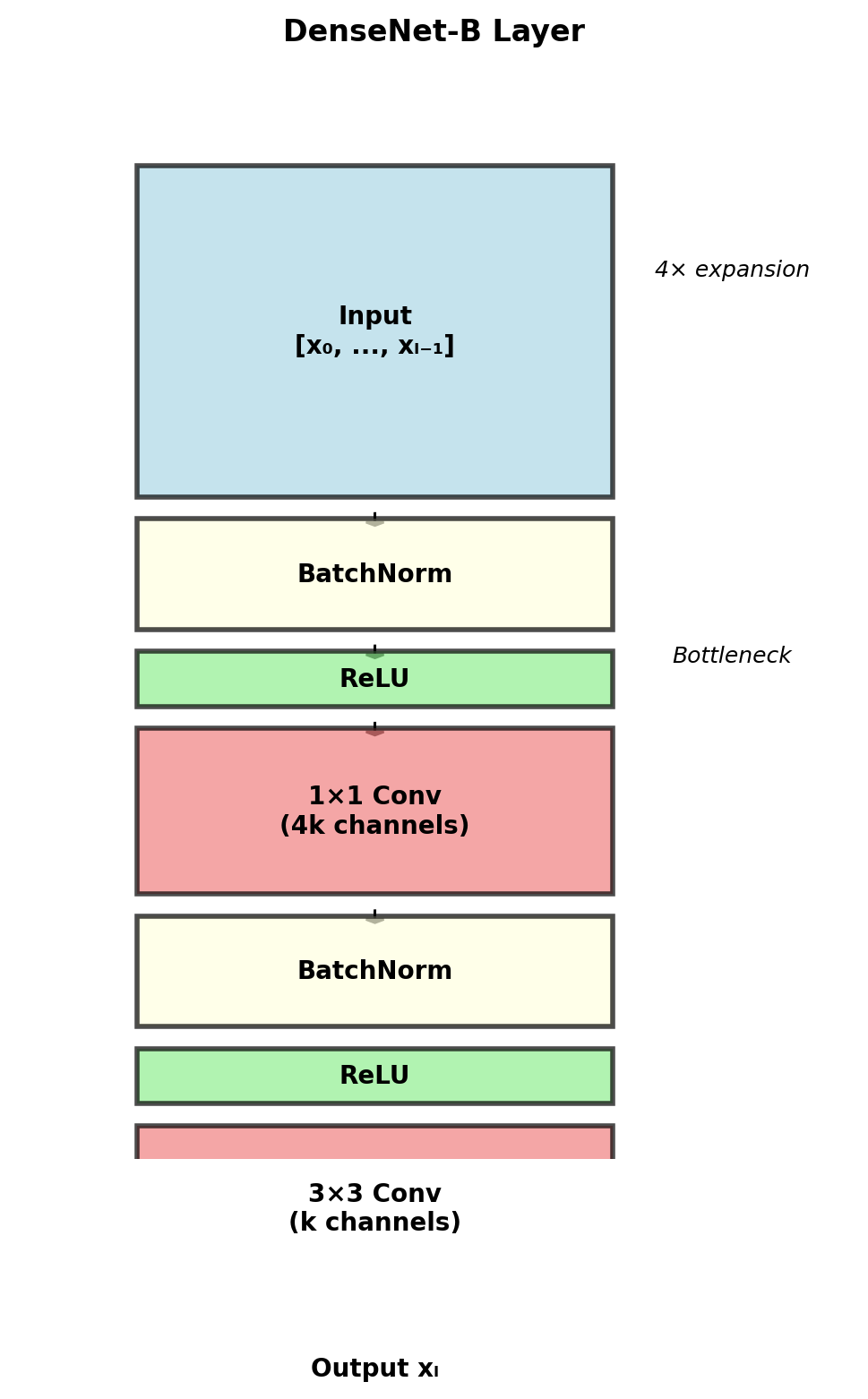
Composite Function \(H_\ell\)
Pre-activation Design
Standard DenseNet-B (Bottleneck):
- Batch Normalization
- ReLU
- 1×1 Convolution (4k channels)
- Batch Normalization
- ReLU
- 3×3 Convolution (k channels)
Pre-activation design rationale:
- Clean gradient path
- No need for careful initialization
- Identity mappings when needed
Growth Rate Math
Channel Progression
Layer \(\ell\) in a dense block:
- Input channels: \(k_0 + k \times (\ell - 1)\)
- Output channels: \(k\) (growth rate)
- After concatenation: \(k_0 + k \times \ell\)
For an \(L\)-layer block: \[\text{Total channels} = k_0 + k \times L\]
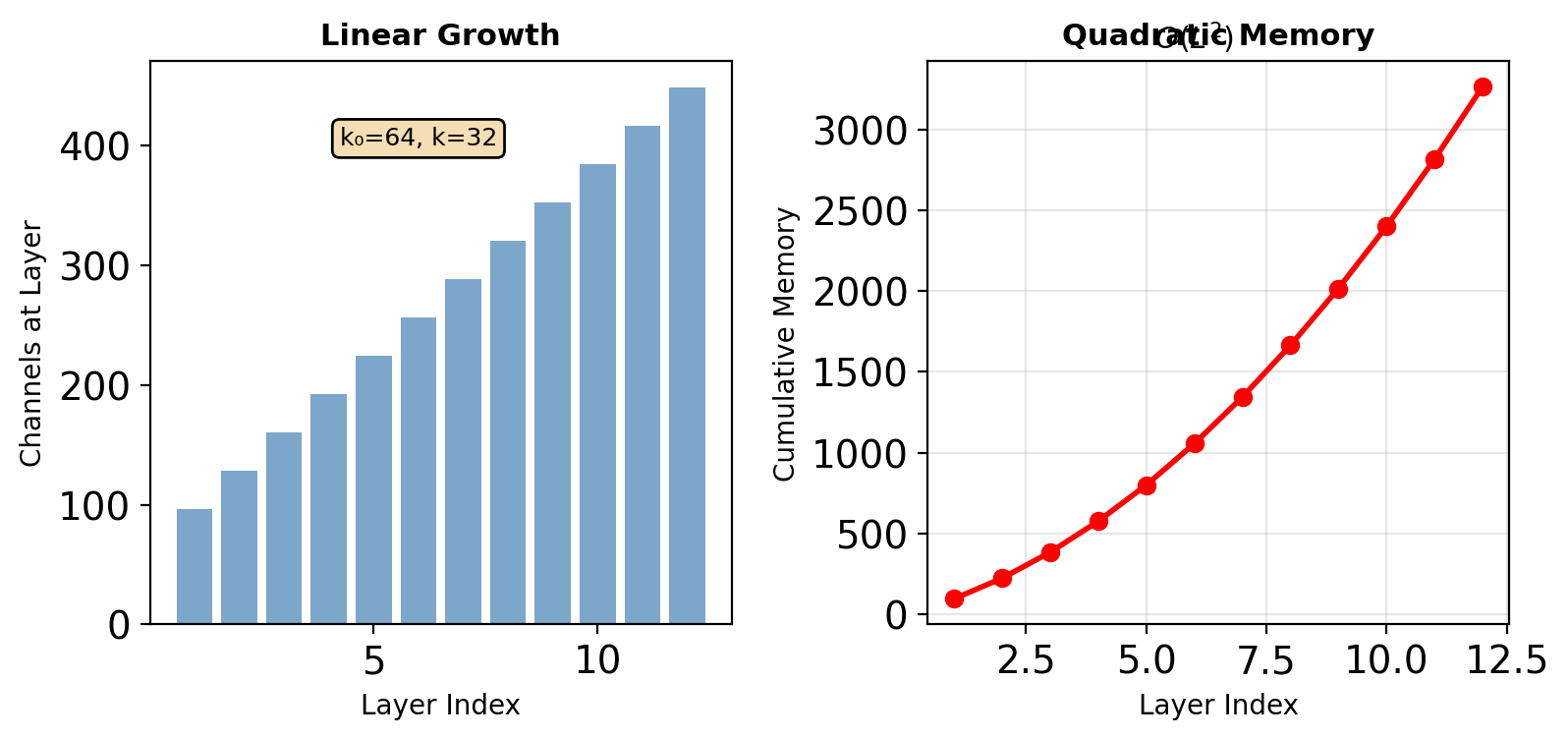
Quadratic Memory Growth
Feature maps stored for concatenation: \[\text{Memory} \propto \sum_{\ell=1}^{L} (k_0 + k\ell) = k_0 L + \frac{kL(L+1)}{2}\]
Transition Layers
Between Dense Blocks
Purpose: Control model complexity
- Batch Normalization
- ReLU activation
- 1×1 Convolution
- 2×2 Average Pooling
Compression Factor \(\theta\)
If block outputs \(m\) feature maps:
- Transition reduces to \(\lfloor \theta m \rfloor\)
- DenseNet-C: \(\theta = 0.5\)
- DenseNet-BC: Bottleneck + Compression
Compression is critical for deep networks
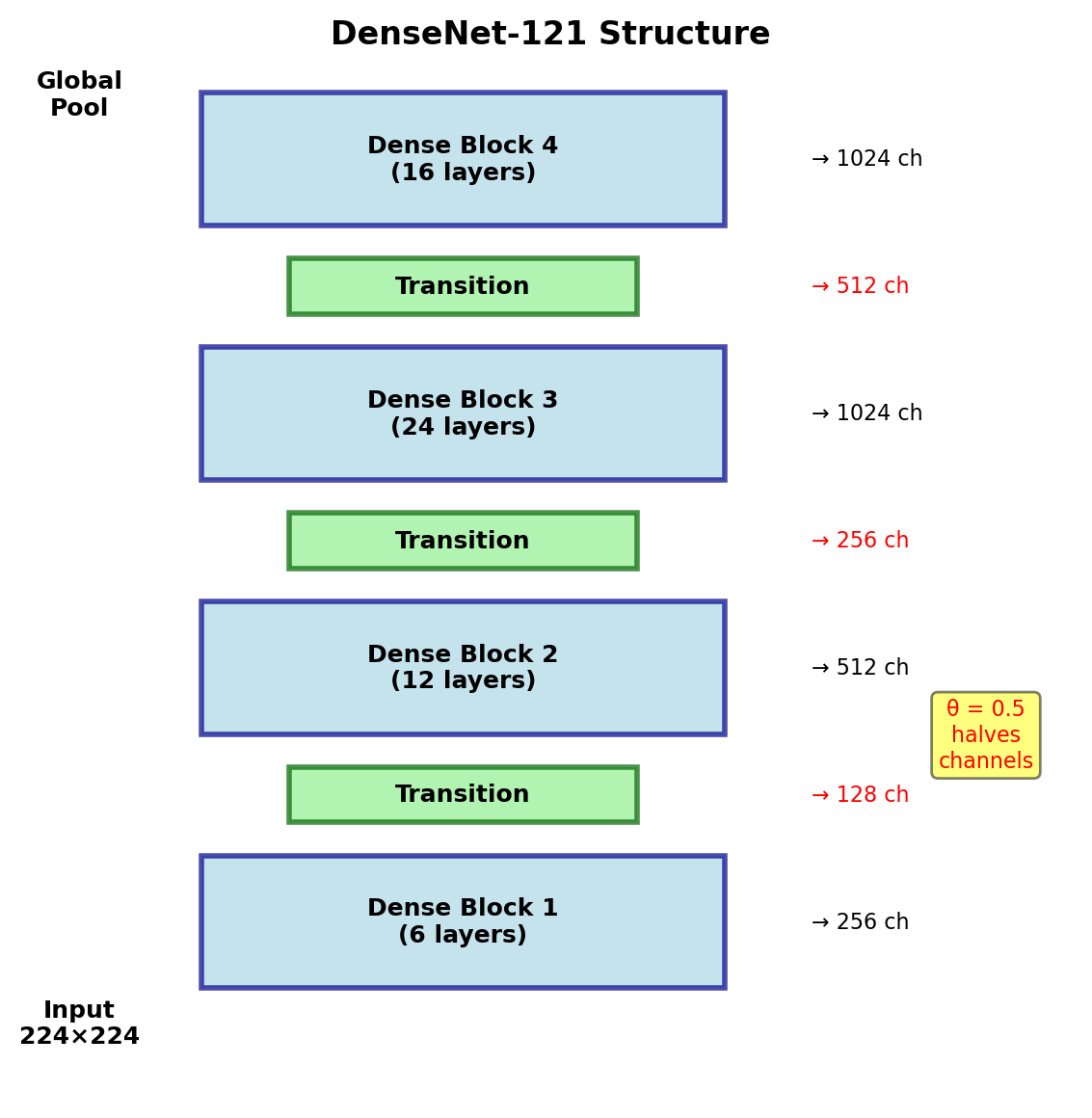
DenseNet Architectures
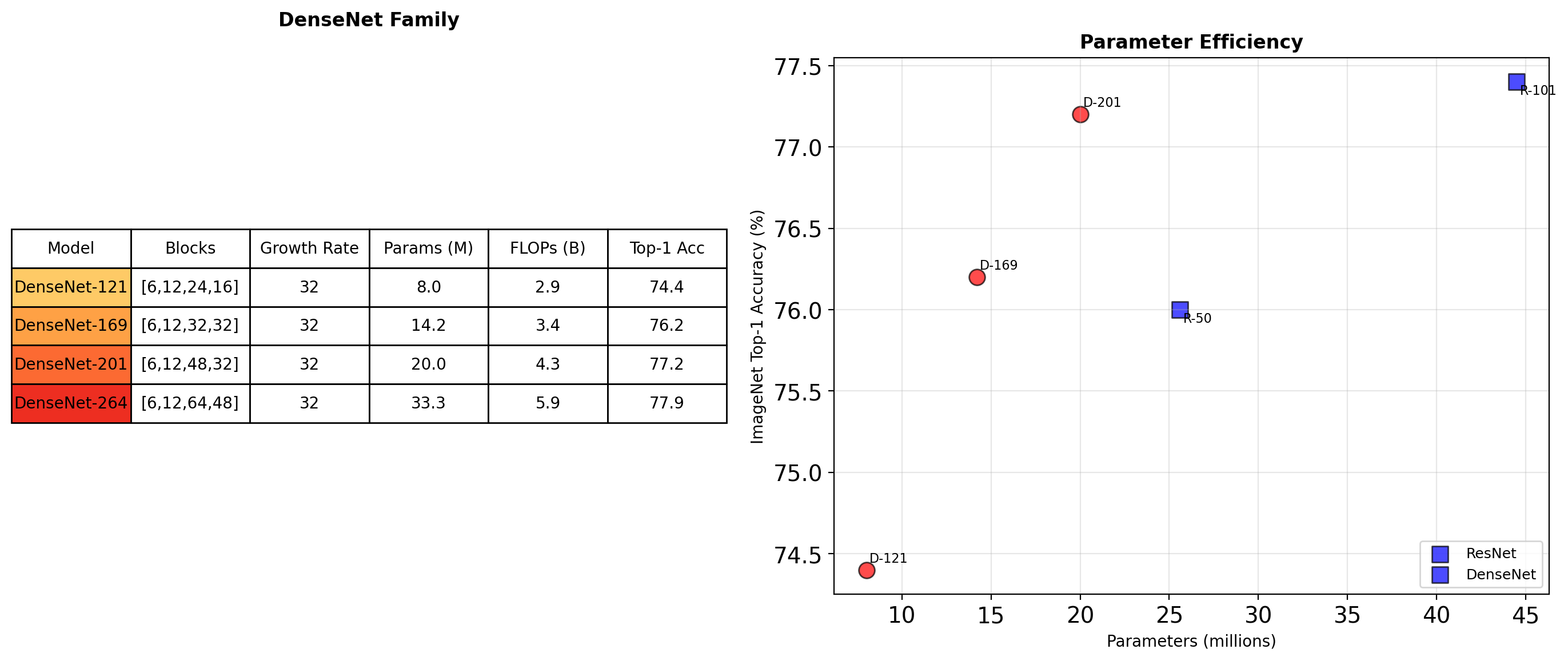
DenseNet achieves comparable accuracy with significantly fewer parameters
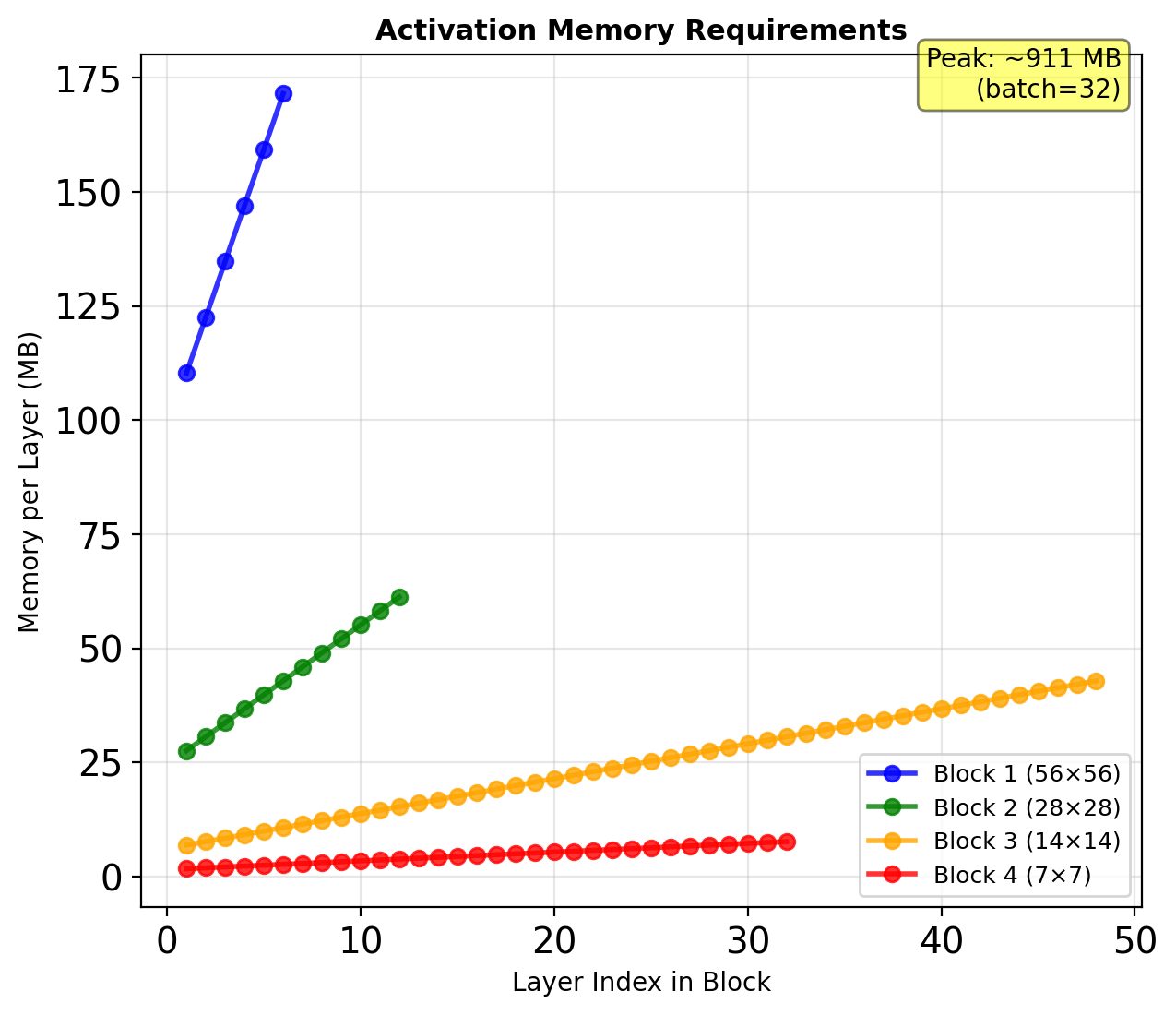
Memory Consumption Analysis
Forward Pass Storage
Must maintain all intermediate features:
- Layer \(\ell\) needs: \([x_0, x_1, ..., x_{\ell-1}]\)
- Cannot free early activations
- Peak memory at block end
Implementation Strategy
Shared memory allocations:
# Concatenate in-place
features = [x0]
for layer in dense_block:
new_features = layer(torch.cat(features, 1))
features.append(new_features)
return torch.cat(features, 1)Memory-efficient variant: Recompute activations during backward pass (trading compute for memory)
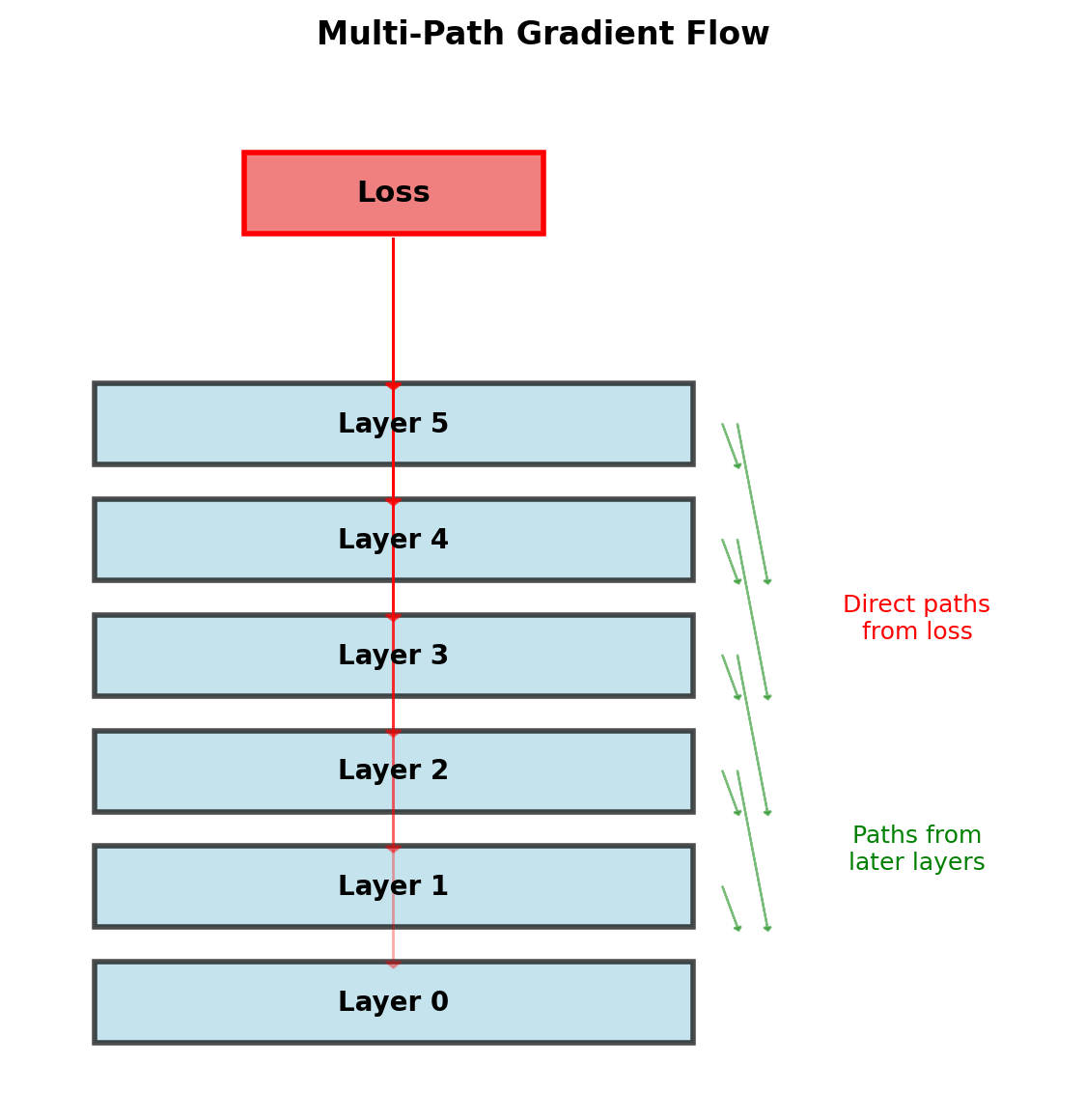
Gradient Flow in DenseNet
Direct Gradient Paths
Loss gradient to layer \(\ell\): \[\frac{\partial \mathcal{L}}{\partial x_\ell} = \frac{\partial \mathcal{L}}{\partial x_L} \frac{\partial x_L}{\partial x_\ell} + \sum_{s=\ell+1}^{L-1} \frac{\partial \mathcal{L}}{\partial H_s} \frac{\partial H_s}{\partial x_\ell}\]
Each layer receives:
- Direct supervision from loss
- Gradient from all subsequent layers
- No transformation through intermediate layers
Implicit Deep Supervision
Shorter paths to loss function → stronger gradient signal
Average path length: \(\frac{L+1}{2}\) (vs \(L\) in sequential)
Feature Reuse Analysis
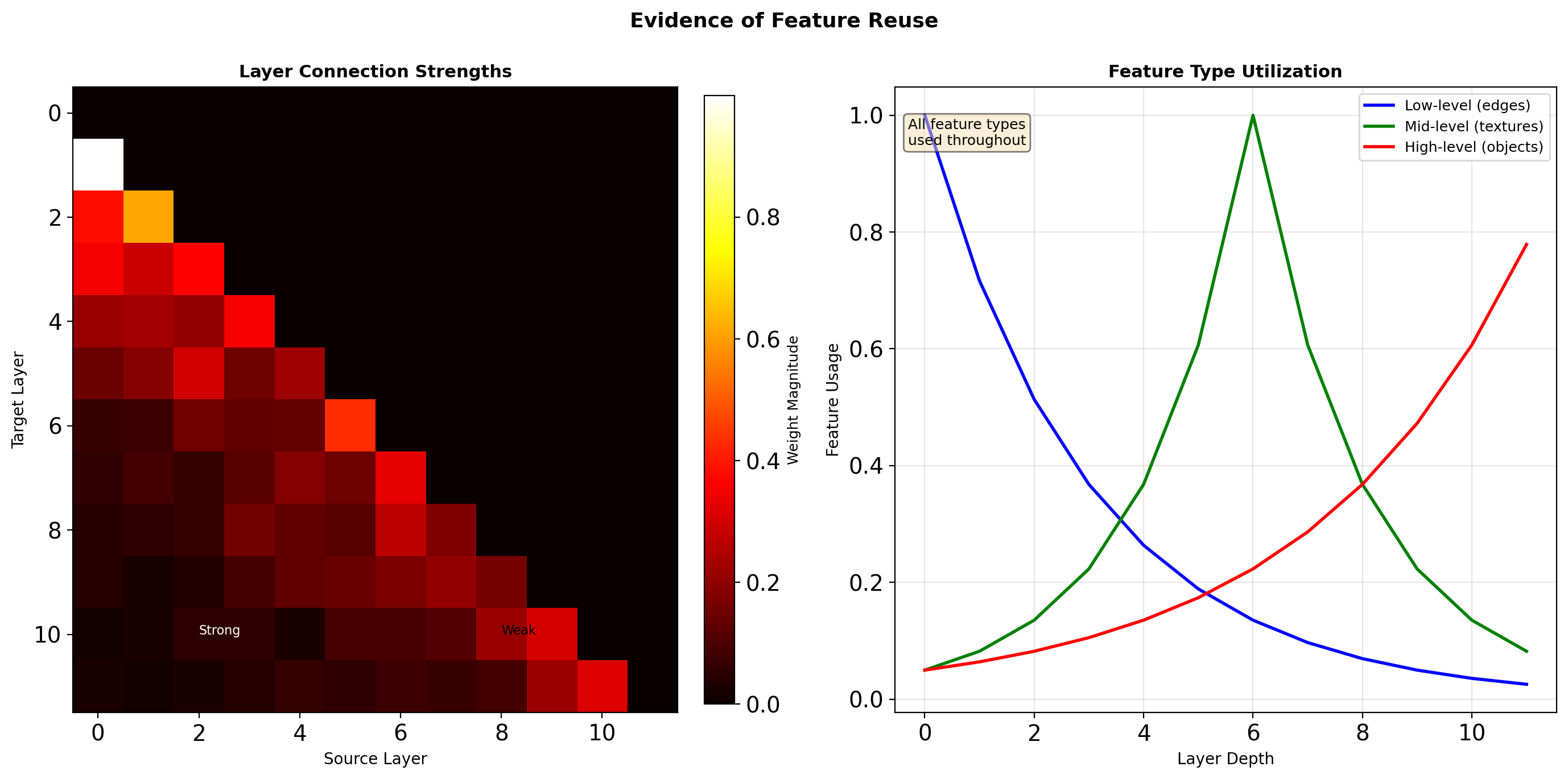
Later layers actively use features from all depths, not just immediate predecessors
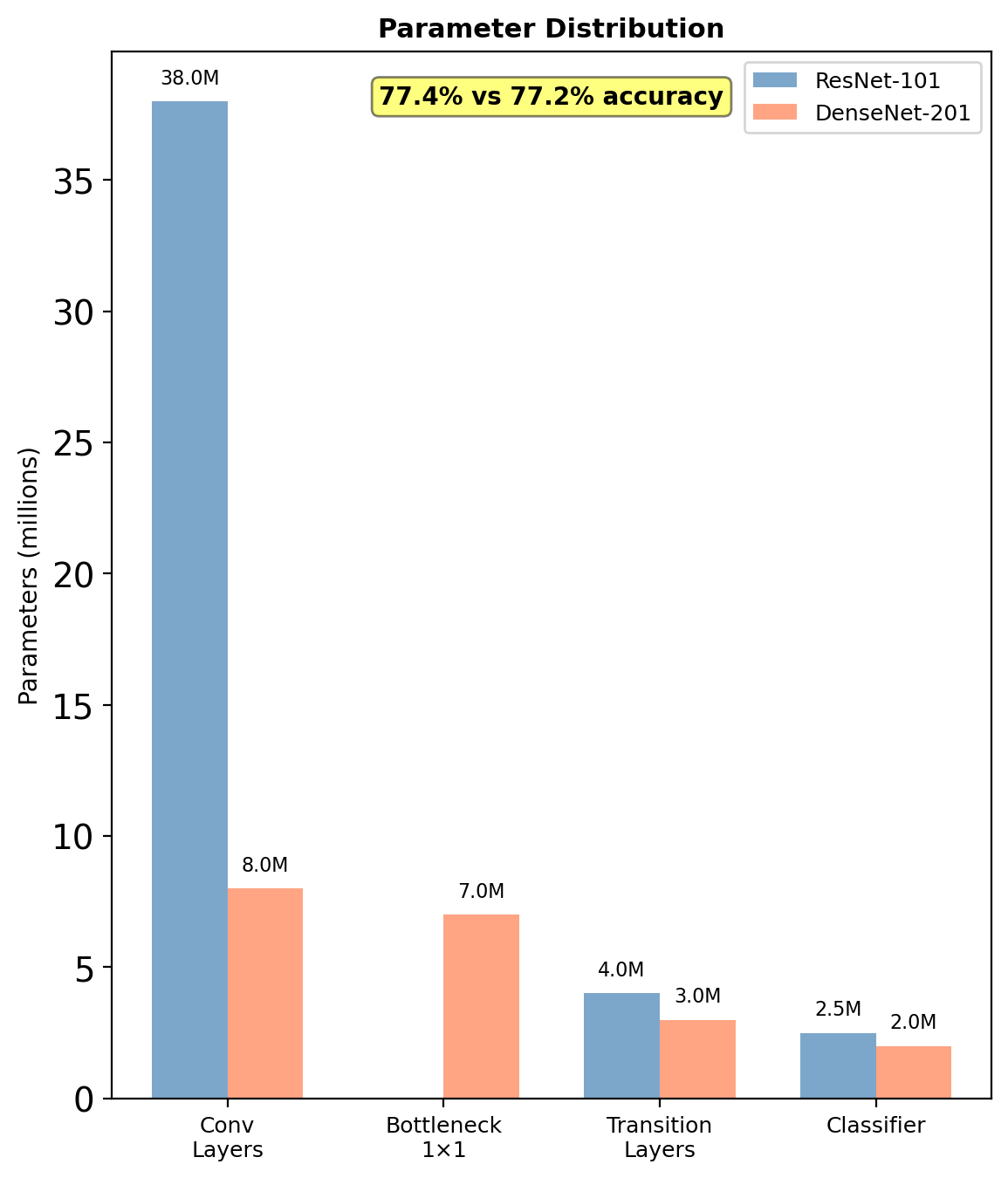
Parameter Efficiency: A Detailed Comparison
Where Parameters Are Saved
ResNet-101 (44.5M params):
- 33 residual blocks × 3 conv layers
- Each: full channel-to-channel mapping
- Example block: 256→256→1024 channels
DenseNet-201 (20M params):
- Feature reuse via concatenation
- Narrow layers (k=32 new channels)
- Bottleneck: 4k intermediate only
The Regularization Effect
Dense connections act as implicit regularization:
- Each layer must work with all previous features
- Forces feature complementarity
- Reduces co-adaptation
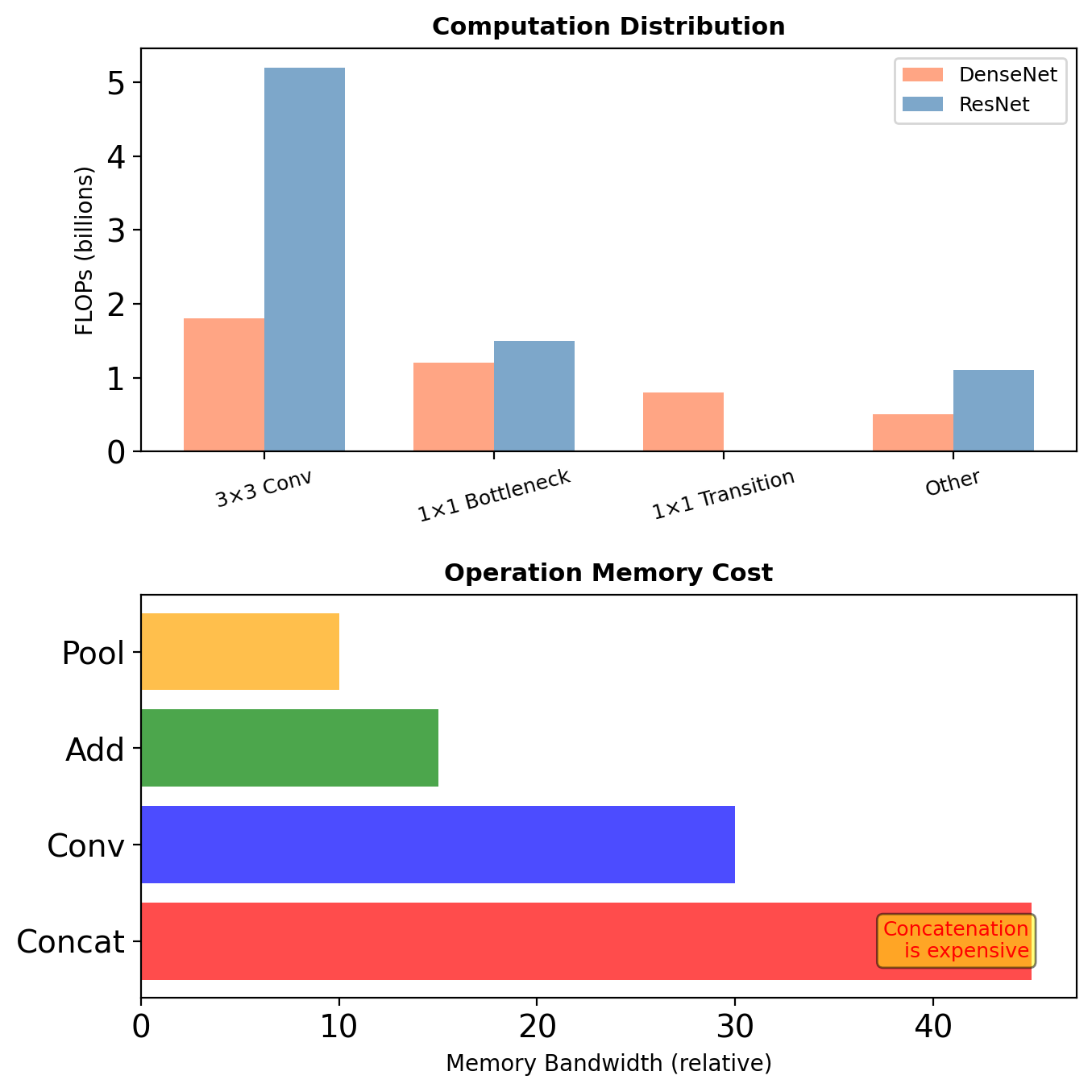
Computational Considerations
FLOPs Analysis
DenseNet-201: 4.3B FLOPs ResNet-101: 7.8B FLOPs
Despite more connections, fewer FLOPs due to:
- Narrow layers (k=32)
- Efficient bottleneck structure
- Feature reuse
Implementation Challenges
Concatenation overhead:
- Memory allocation
- Data movement
- Cache inefficiency
GPU utilization:
- Many small operations
- Limited parallelism within layers
- Memory bandwidth bound
Variants and Extensions
CondenseNet (2018)
- Learned group convolutions
- Prune connections during training
- 10× fewer FLOPs at same accuracy
SparseNet (2018)
- Exponentially spaced connections
- Connect layer \(i\) to \(i-2^k\) for all valid \(k\)
- \(O(L \log L)\) connections vs \(O(L^2)\)
VoVNet (2019)
- One-shot aggregation
- Aggregate once at block end
- Better GPU utilization
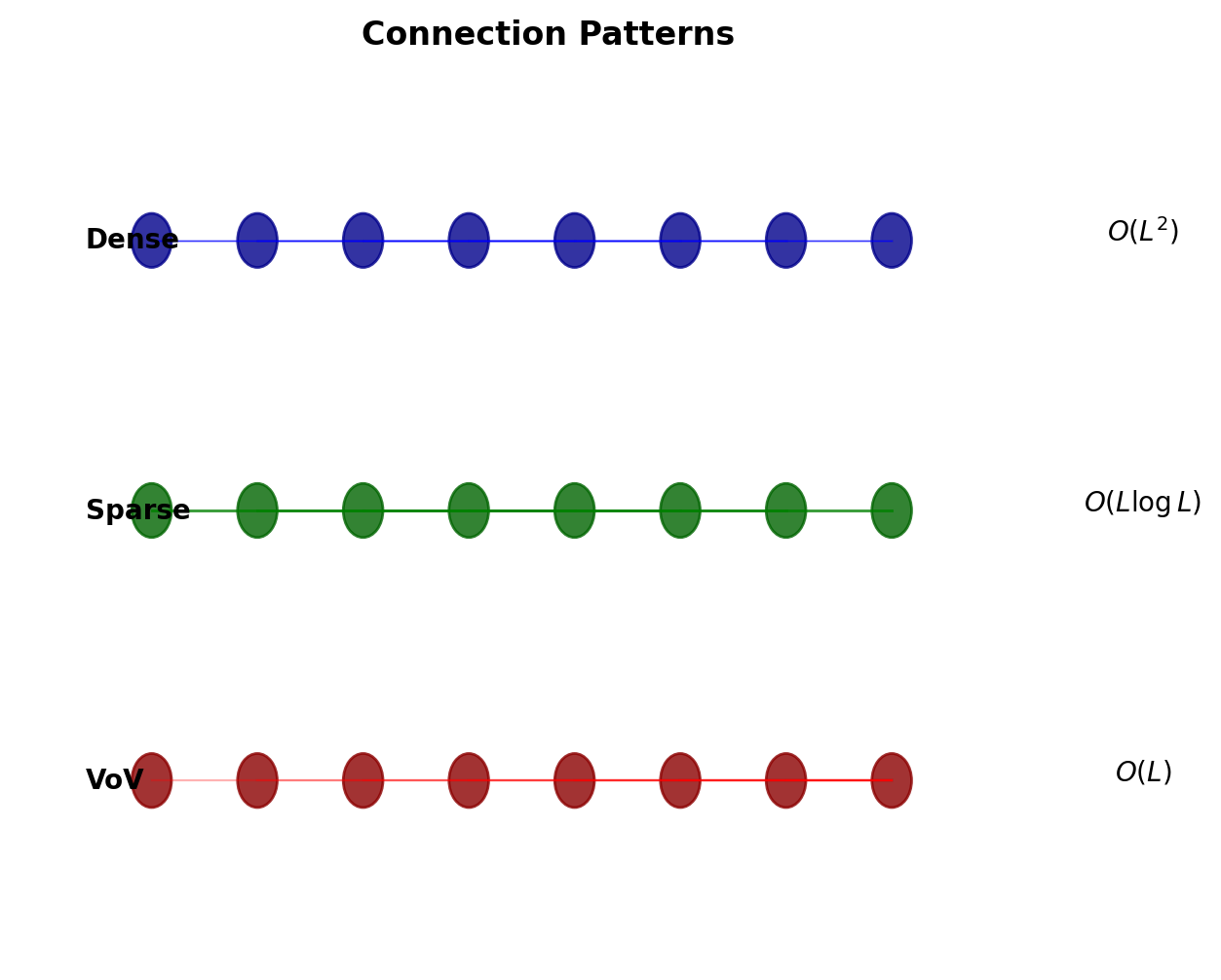
Dense connectivity principle spawned multiple architectural innovations
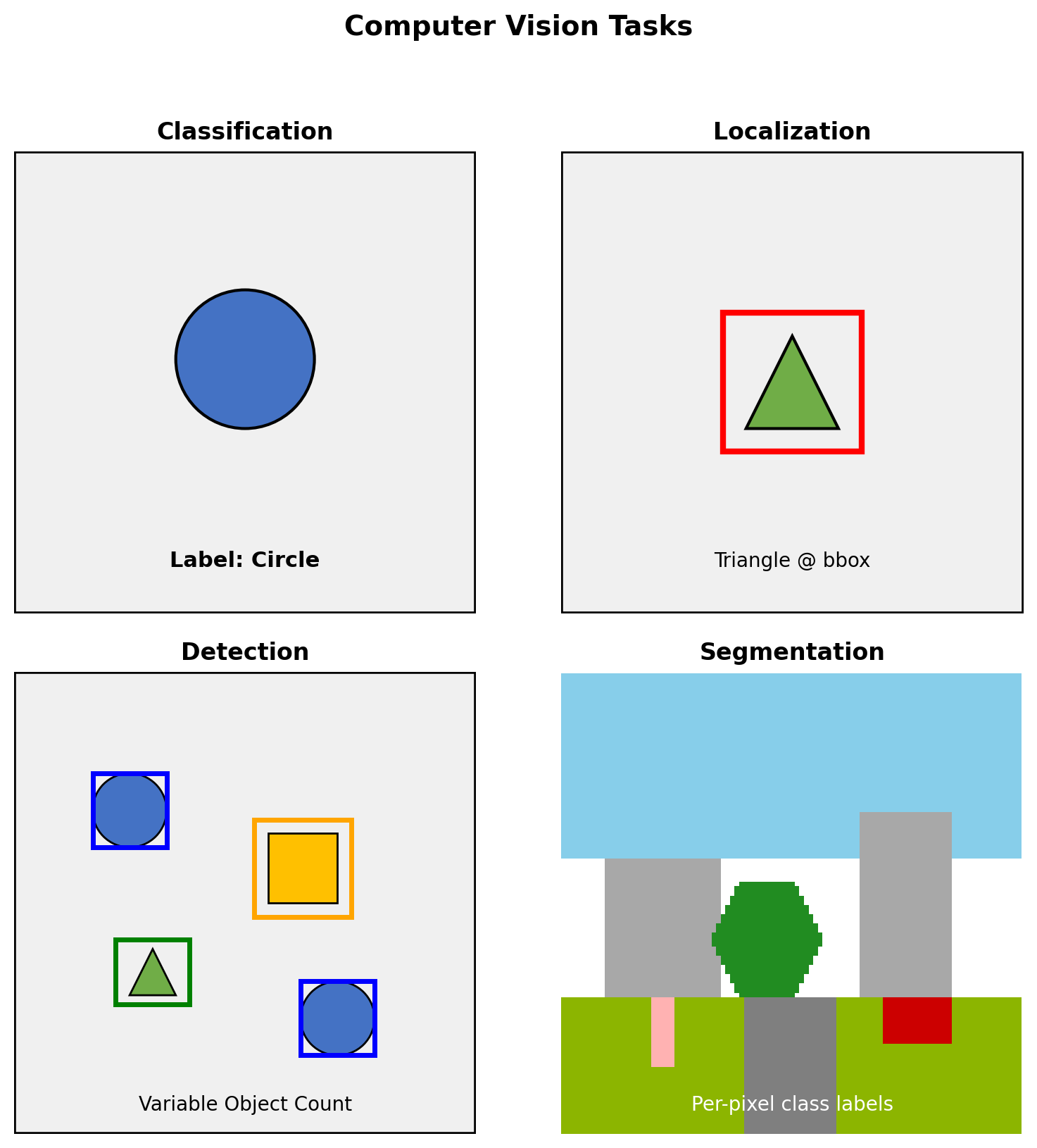
From Classification to Spatial Tasks
Task Hierarchy
Classification: \(f: \mathbb{R}^{H \times W \times 3} \rightarrow \{1, ..., C\}\)
Classification + Localization: \[f: \mathbb{R}^{H \times W \times 3} \rightarrow \{1, ..., C\} \times \mathbb{R}^4\]
Object Detection: \[f: \mathbb{R}^{H \times W \times 3} \rightarrow \mathcal{P}(\{1, ..., C\} \times \mathbb{R}^4)\]
Segmentation: \[f: \mathbb{R}^{H \times W \times 3} \rightarrow \{1, ..., C\}^{H' \times W'}\]
where \(\mathcal{P}\) denotes power set (variable number of outputs)
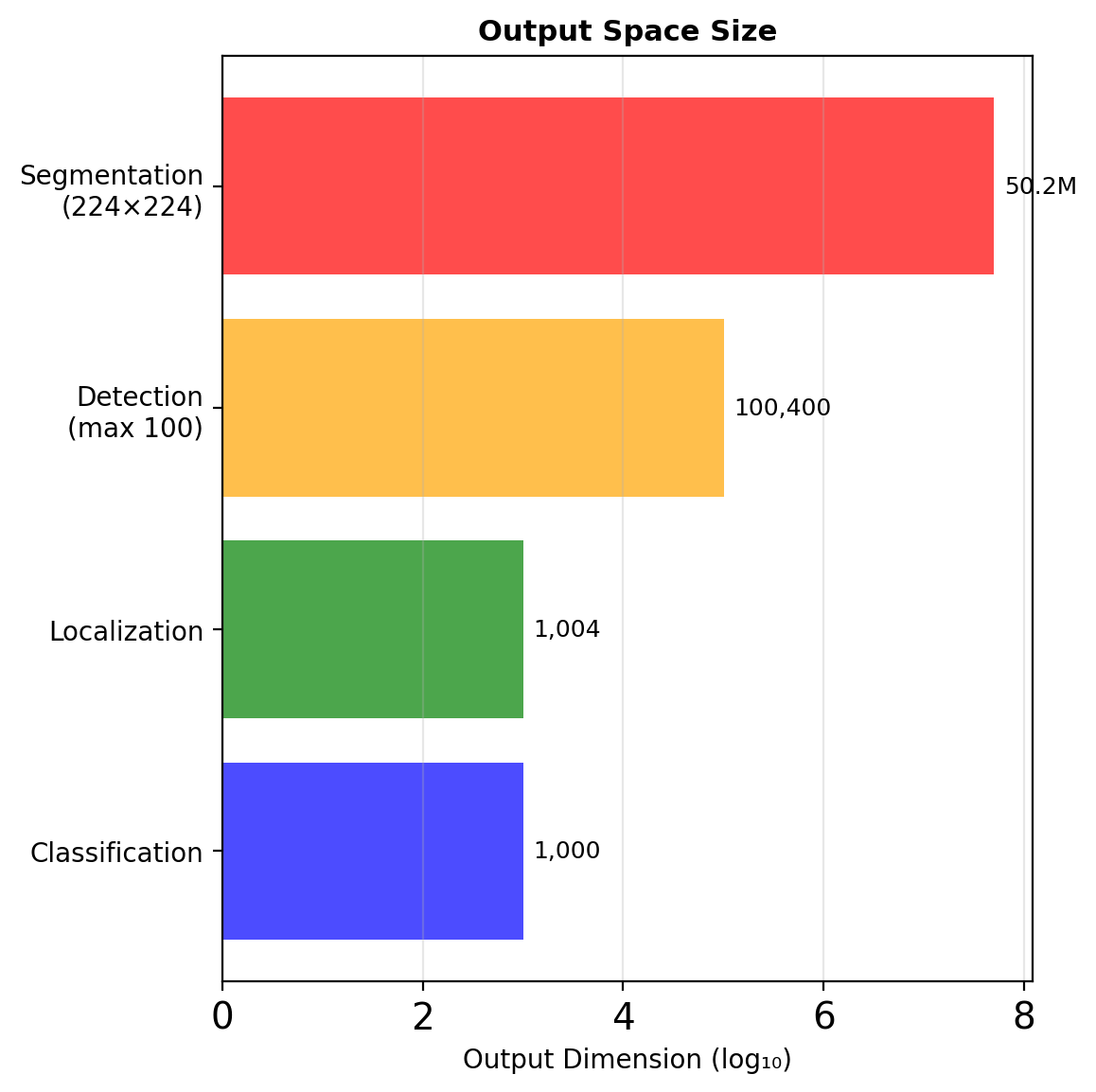
Output Space Complexity
Dimensionality Analysis
| Task | Output Space | Dimension |
|---|---|---|
| Classification | \(\{1, ..., C\}\) | \(C\) |
| Localization | \(\{1, ..., C\} \times \mathbb{R}^4\) | \(C + 4\) |
| Detection | \(\bigcup_{n=0}^{N_{max}} (\{1, ..., C\} \times \mathbb{R}^4)^n\) | Variable |
| Segmentation | \(\{1, ..., C\}^{H \times W}\) | \(C \times H \times W\) |
| Instance Seg. | \(\{0, ..., N\}^{H \times W}\) | \((N+1) \times H \times W\) |
Detection is uniquely challenging: unknown cardinality
Localization as Regression
Bounding Box Parameterization
Direct coordinates: \((x_{min}, y_{min}, x_{max}, y_{max})\)
Center + size: \((x_c, y_c, w, h)\)
Multi-task Loss
\[\mathcal{L} = \mathcal{L}_{cls}(c, \hat{c}) + \lambda \cdot \mathbb{1}_{c > 0} \cdot \mathcal{L}_{loc}(b, \hat{b})\]
where \(\mathbb{1}_{c > 0}\) indicates object presence
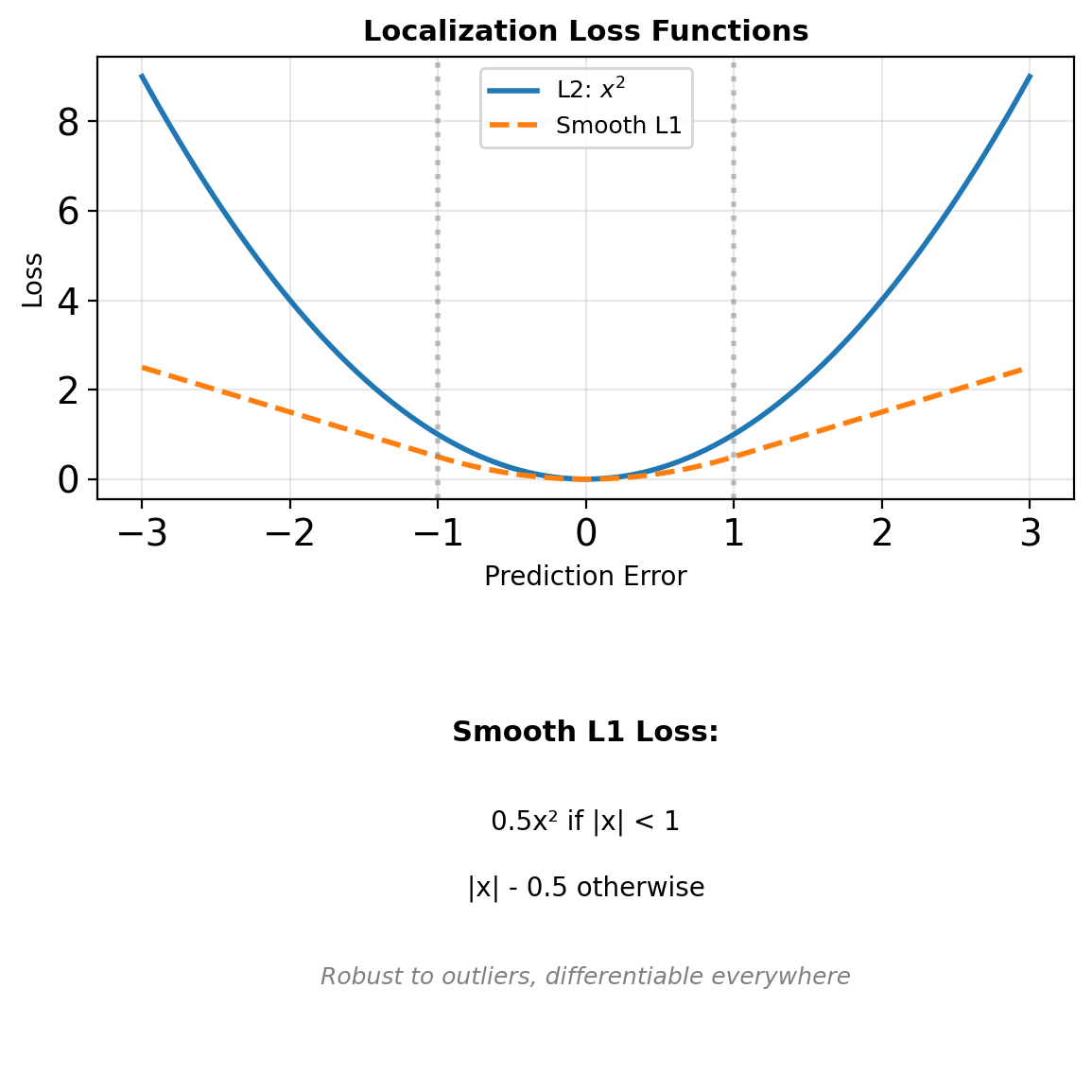
Limitations of L2 Loss
\[\mathcal{L}_{L2} = ||b - \hat{b}||^2\]
Scale dependent: large boxes dominate loss
The Detection Problem
Main Challenges
- Variable output count: \(N \in [0, N_{max}]\)
- Localization + classification: Joint optimization
- Duplicate predictions: Same object detected multiple times
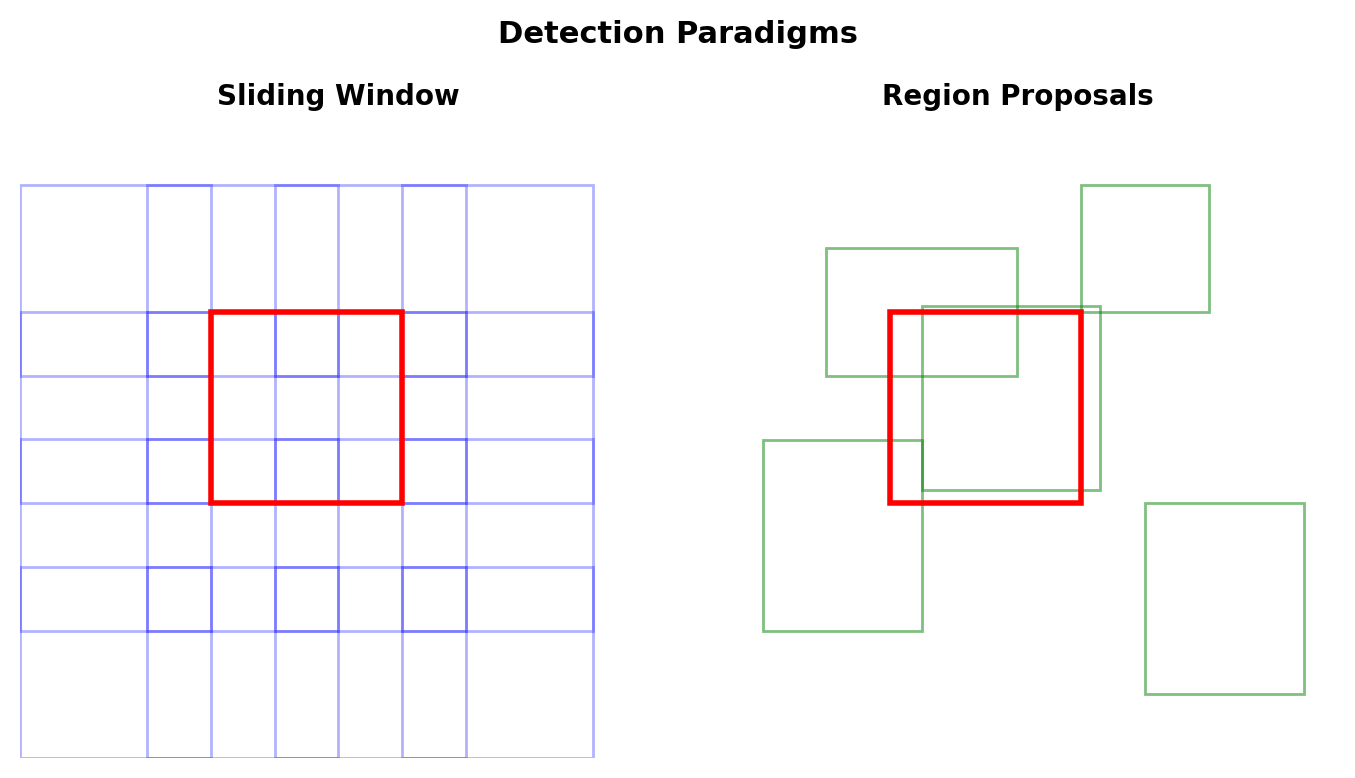
Two Paradigms
Sliding Window:
- Dense predictions at all locations
- Fixed computational cost
- Many negative windows
Region Proposals:
- Selective search or learned proposals
- Variable computational cost
- Higher precision candidates
The Variable Object Count Problem
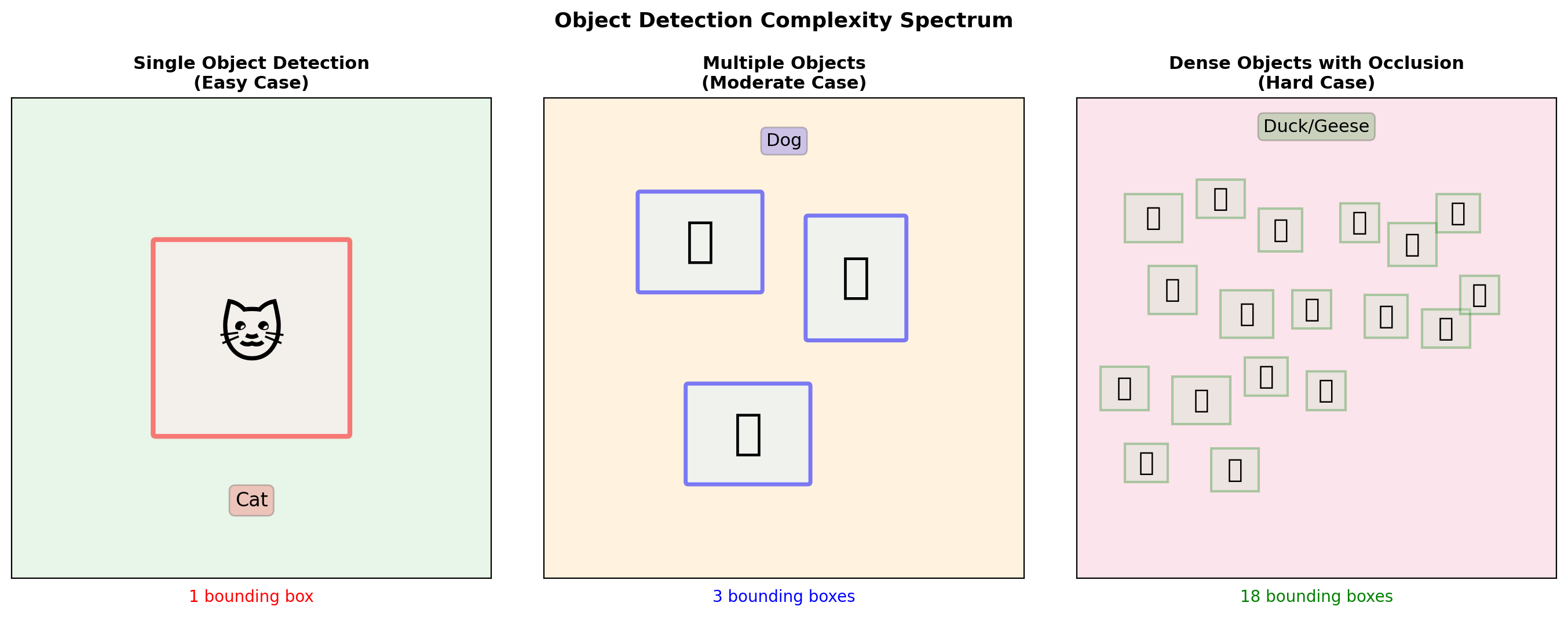
Key Challenges:
- Variable count: Cannot use fixed-size output
- Multiple scales: Objects vary in size
- Occlusion: Objects overlap
- Class imbalance: Many more background regions than objects
Sliding Window vs Region Proposals
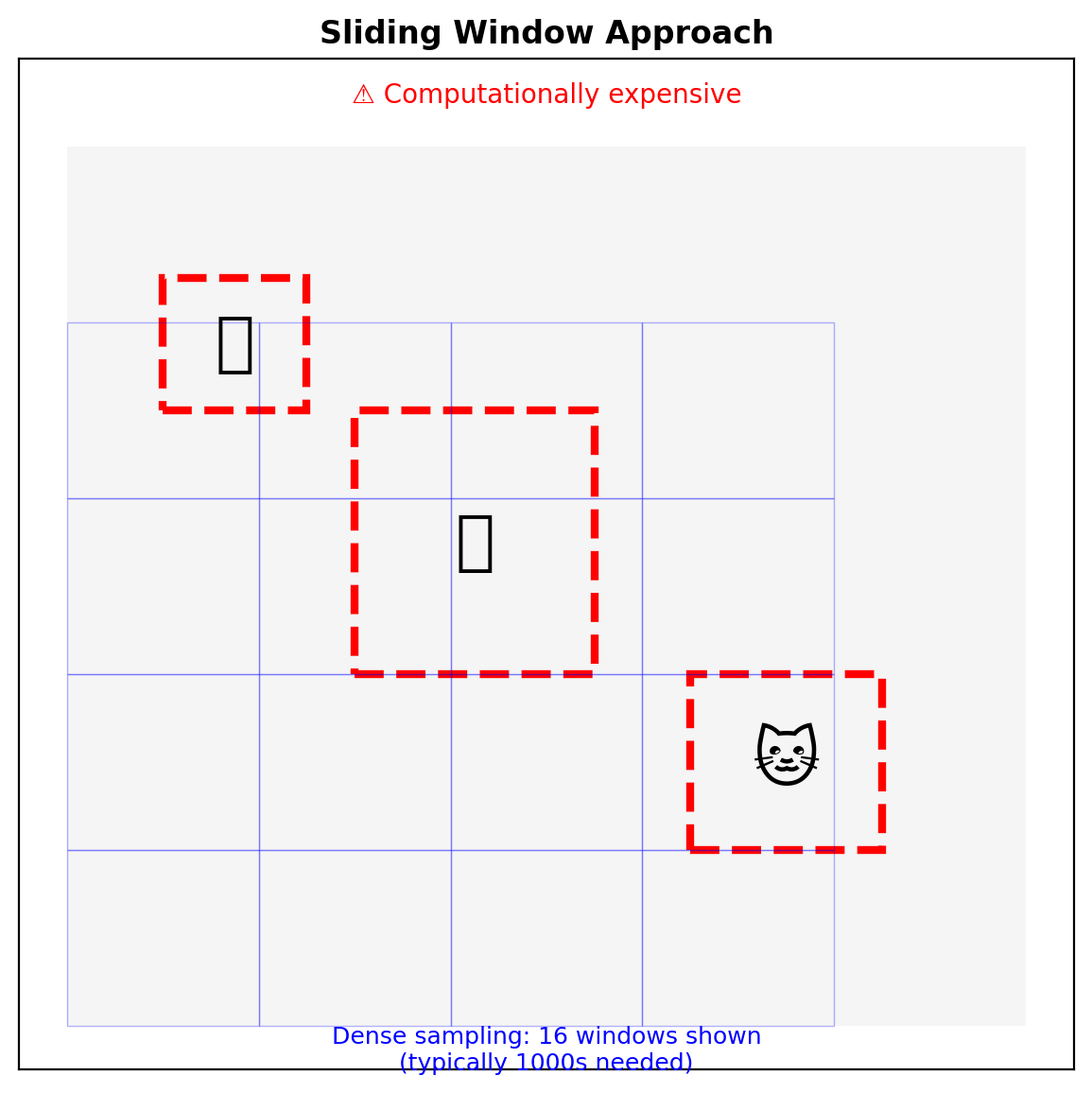
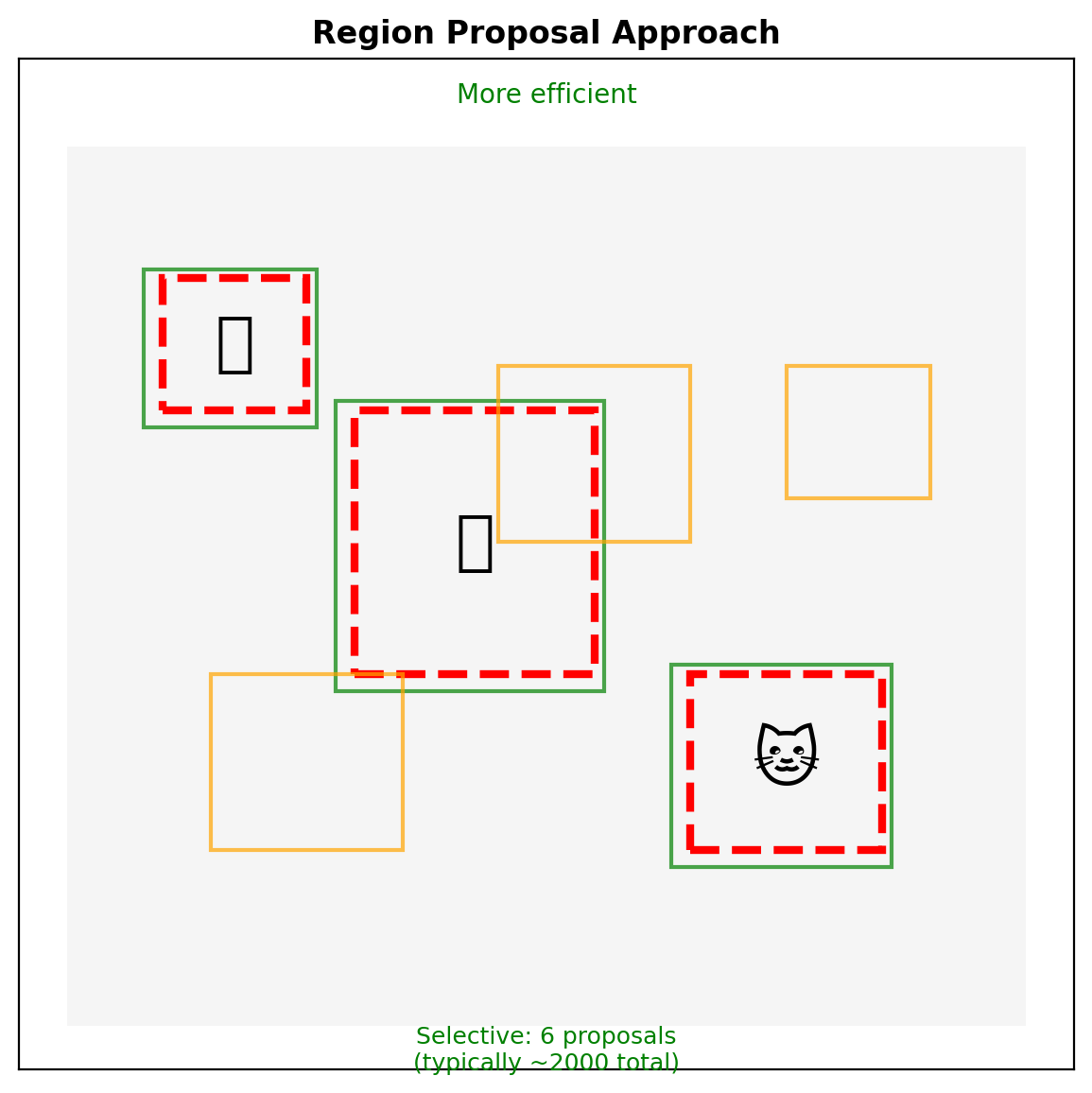
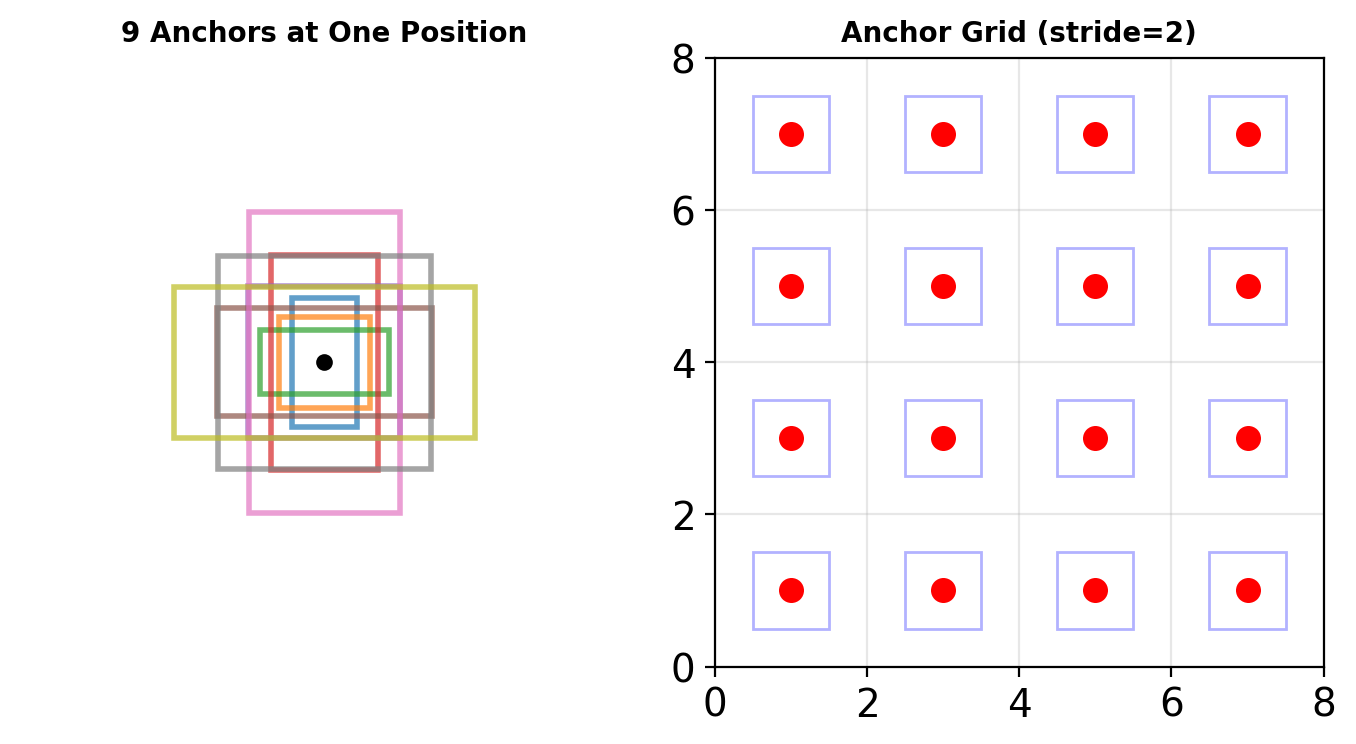
Anchor Boxes: Discretizing Detection Space
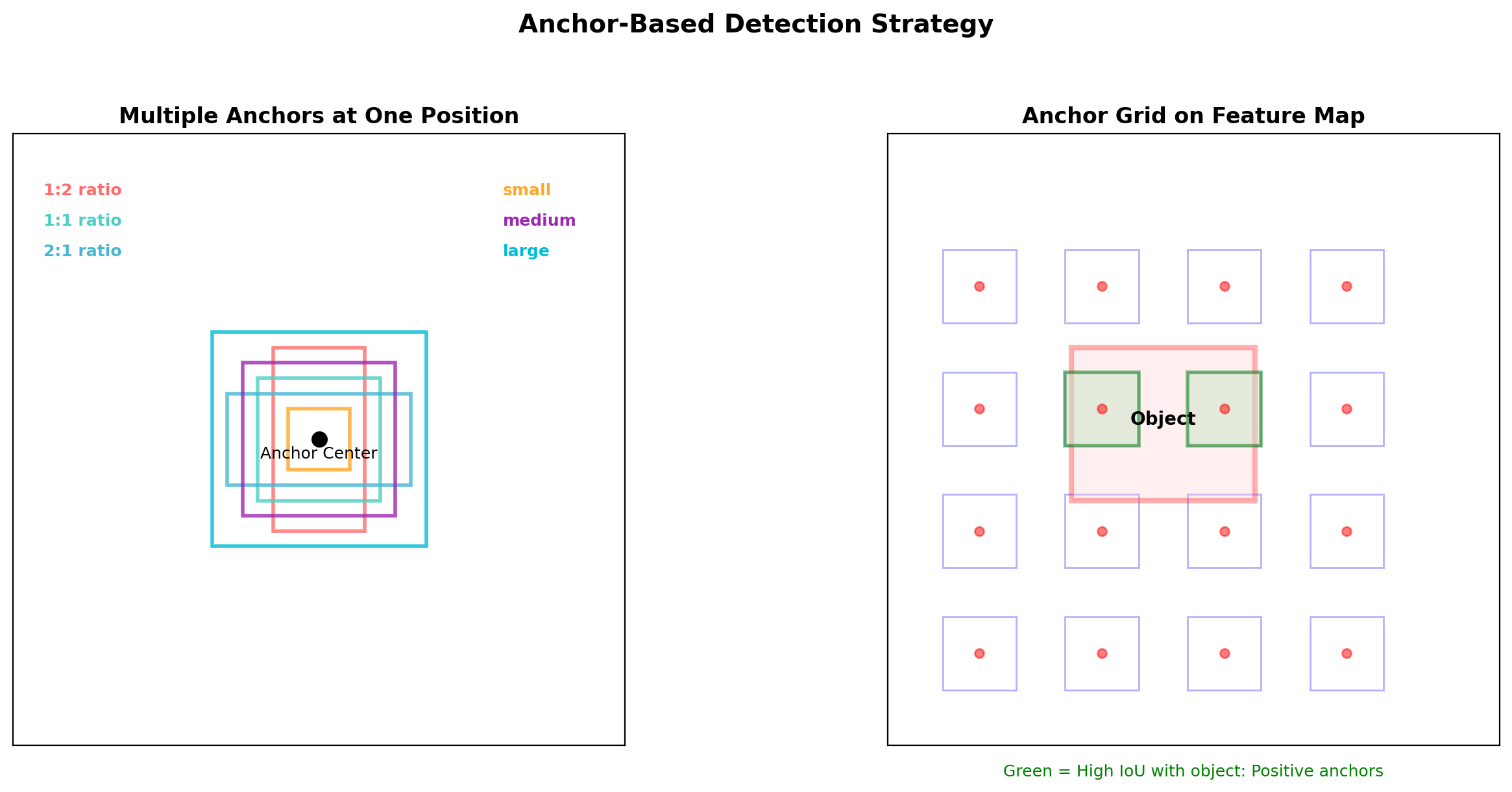
Anchor Box Strategy:
- Pre-define boxes at multiple scales and ratios
- Typical: 9 anchors per position (3 scales × 3 ratios)
- Network predicts:
- Offsets to refine anchor to final box
- Classification scores per anchor
- Trade-off: More anchors = better recall but more computation
Intersection over Union (IoU)
Definition
\[\text{IoU}(B_1, B_2) = \frac{|B_1 \cap B_2|}{|B_1 \cup B_2|}\]
Properties
- Scale invariant: \(\text{IoU}(B, B') = \text{IoU}(\alpha B, \alpha B')\)
- Range: \([0, 1]\)
- IoU = 1 iff boxes identical
- IoU = 0 iff no overlap
Thresholds
- Positive: IoU > 0.5 (typically)
- Negative: IoU < 0.3
- Ignore: 0.3 ≤ IoU ≤ 0.5
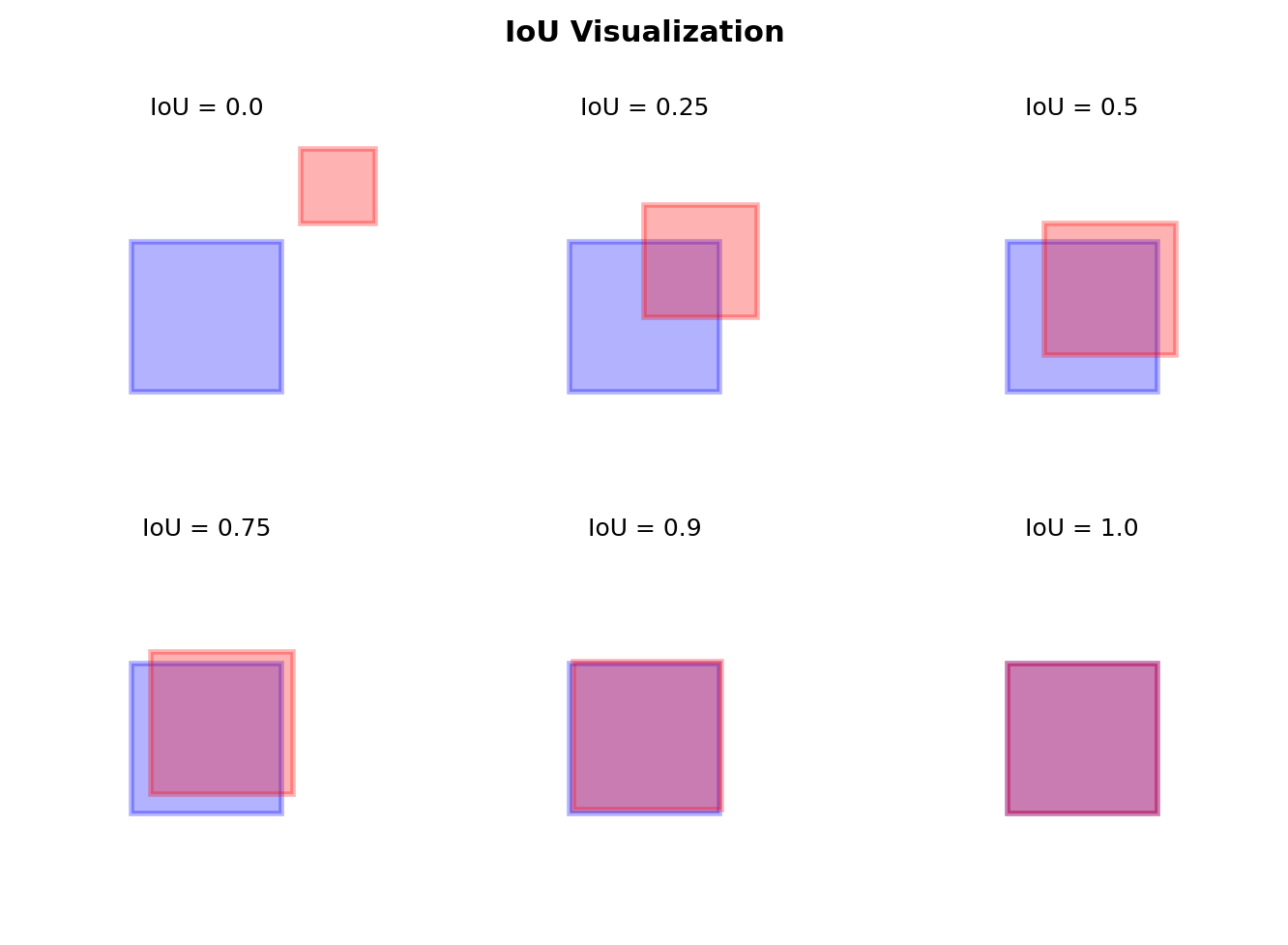
Anchor Boxes
Discretizing Box Space
Anchor parameters:
- Scales: \(s \in \{128, 256, 512\}\)
- Ratios: \(r \in \{0.5, 1, 2\}\)
- Positions: every \(k\) pixels in feature map
Total anchors = \(|S| \times |R| \times \frac{H}{k} \times \frac{W}{k}\)
Relative Parameterization
Given anchor \((x_a, y_a, w_a, h_a)\):
\[\begin{align} t_x &= (x - x_a) / w_a \\ t_y &= (y - y_a) / h_a \\ t_w &= \log(w / w_a) \\ t_h &= \log(h / h_a) \end{align}\]
Network predicts \((t_x, t_y, t_w, t_h)\)
Detection Loss Functions
Multi-task Loss
\[\mathcal{L} = \frac{1}{N_{cls}} \sum_i \mathcal{L}_{cls}(p_i, p_i^*) + \lambda \frac{1}{N_{reg}} \sum_i p_i^* \mathcal{L}_{reg}(t_i, t_i^*)\]
where:
- \(p_i^* = 1\) if anchor \(i\) is positive
- \(t_i\) = predicted box offsets
- \(t_i^*\) = ground truth offsets
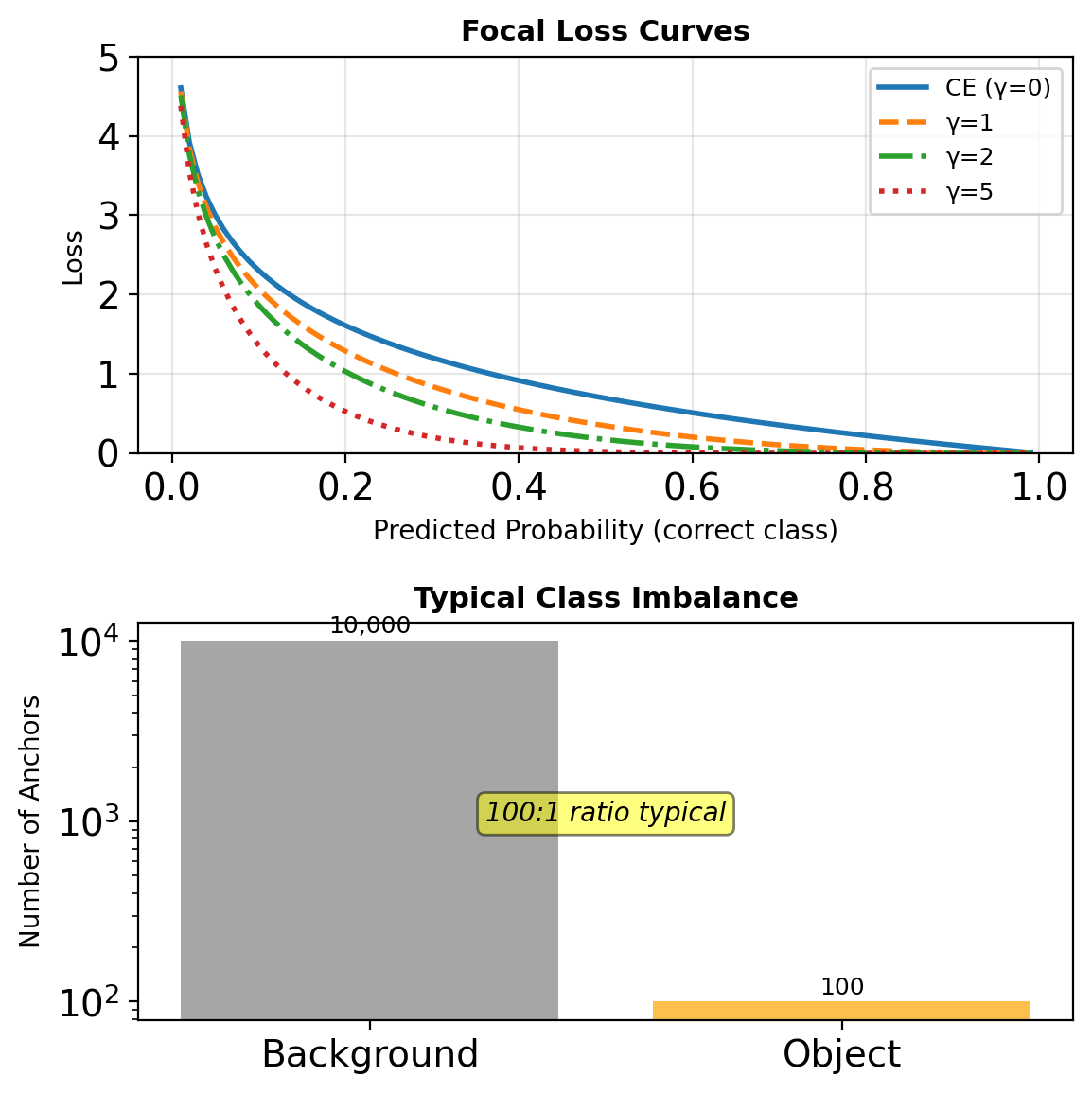
Focal Loss (for class imbalance)
\[\mathcal{L}_{focal} = -\alpha (1-p_t)^\gamma \log(p_t)\]
- \(\gamma = 2\) typically
- Down-weights easy negatives
- Critical for single-stage detectors
Segmentation Output Representations
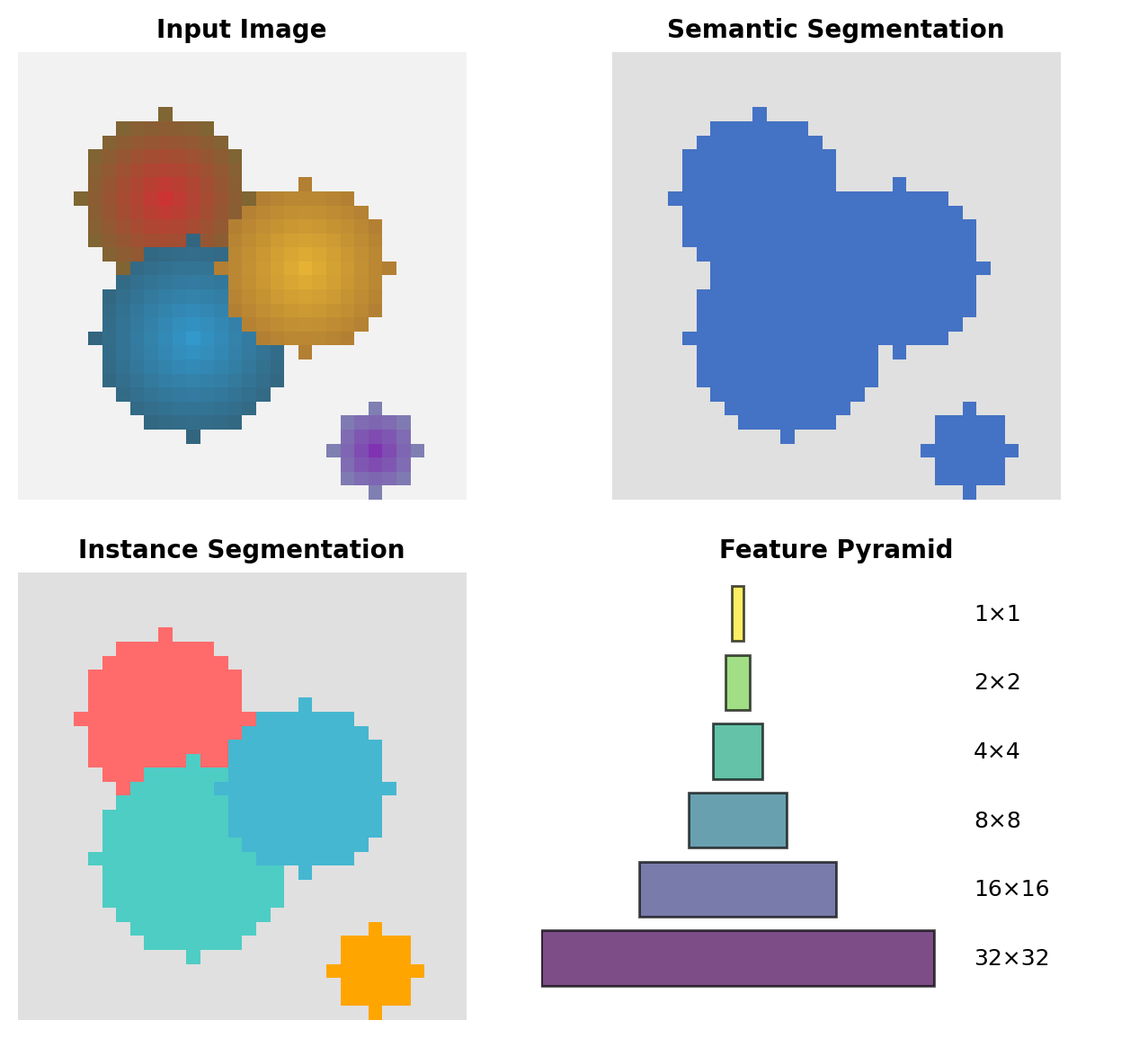
Per-pixel Classification
Semantic: Each pixel → class label \[y[i,j] \in \{0, 1, ..., C\}\]
Instance: Each pixel → object ID \[y[i,j] \in \{0, 1, ..., N\}\]
Resolution Considerations
- Input: \(H \times W \times 3\)
- Encoder output: \(\frac{H}{32} \times \frac{W}{32} \times D\)
- Required output: \(H \times W \times C\)
Requires 32× upsampling.
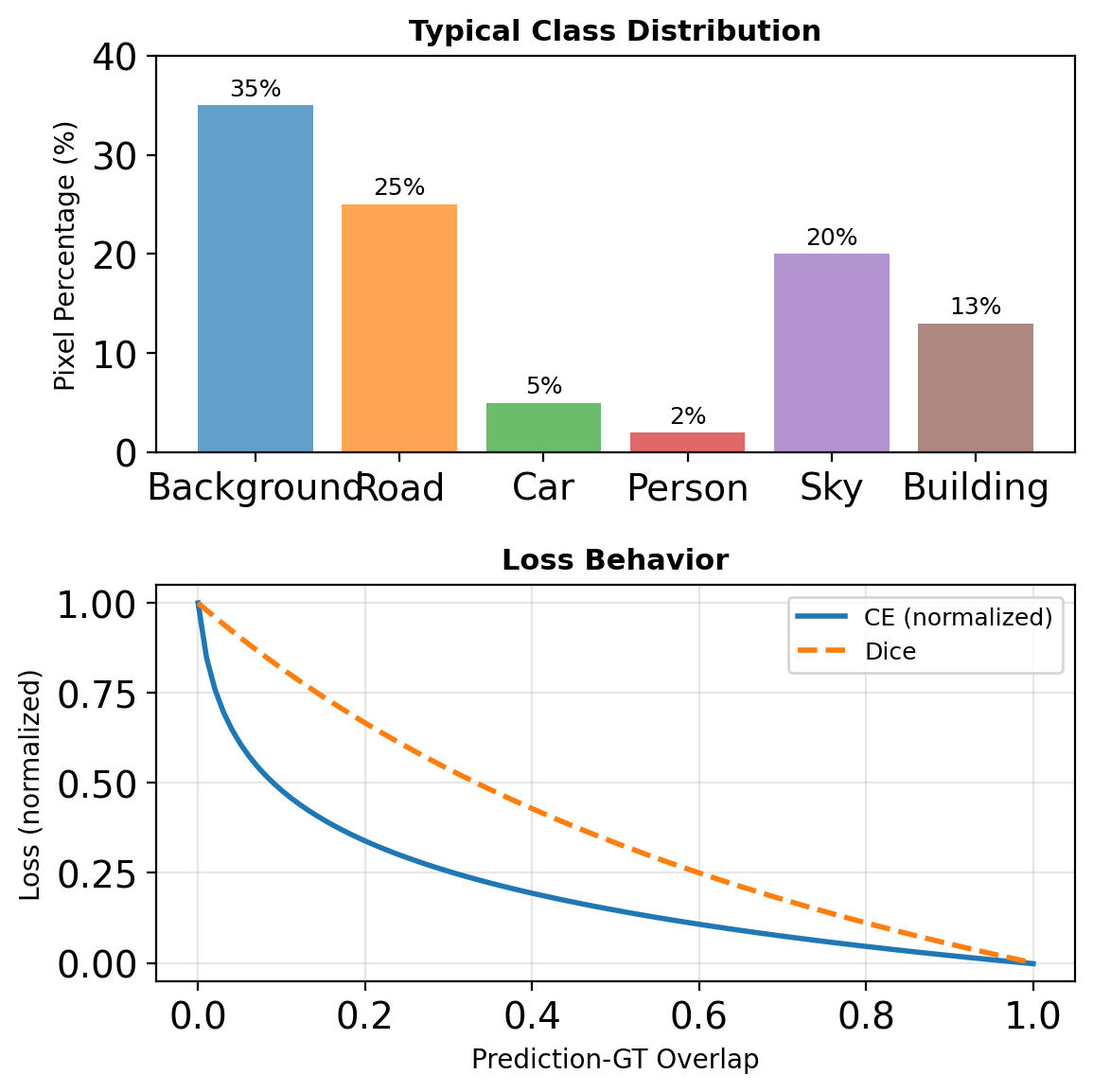
Segmentation Loss Functions
Cross-Entropy (per-pixel)
\[\mathcal{L}_{CE} = -\frac{1}{HW} \sum_{i,j} \sum_{c} y_{ijc} \log \hat{y}_{ijc}\]
Dice Loss (overlap-based)
\[\mathcal{L}_{Dice} = 1 - \frac{2|Y \cap \hat{Y}|}{|Y| + |\hat{Y}|}\]
Approximated as: \[\mathcal{L}_{Dice} = 1 - \frac{2\sum_{ij} y_{ij}\hat{y}_{ij} + \epsilon}{\sum_{ij} y_{ij} + \sum_{ij} \hat{y}_{ij} + \epsilon}\]
Better for imbalanced classes
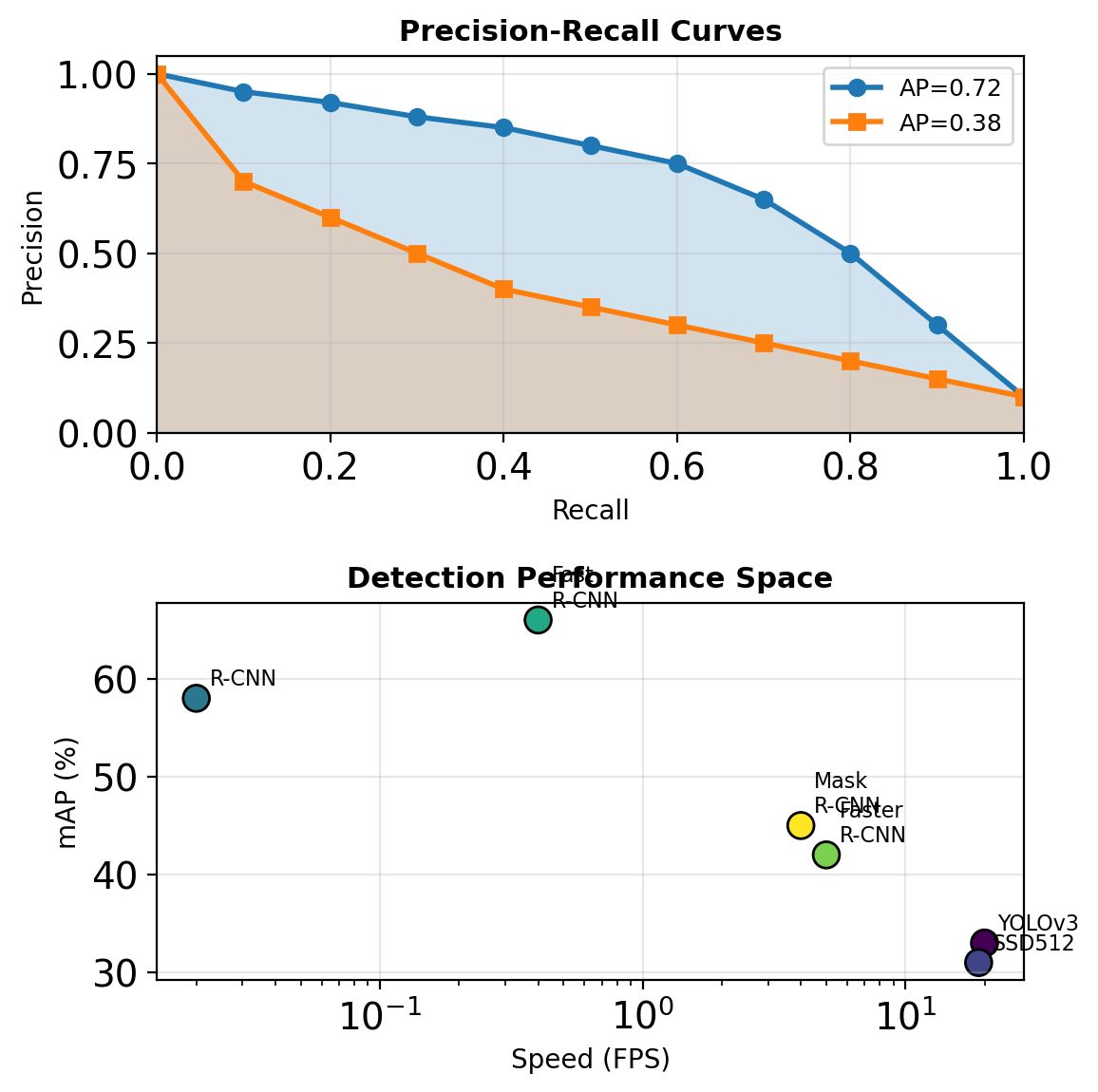
Evaluation Metrics: mAP and mIoU
Mean Average Precision (Detection)
For each class:
- Rank detections by confidence
- Compute precision-recall curve
- AP = area under P-R curve
\[\text{mAP} = \frac{1}{C} \sum_{c=1}^{C} \text{AP}_c\]
Often reported at specific IoU (mAP@0.5, mAP@[.5:.95])
Mean IoU (Segmentation)
\[\text{mIoU} = \frac{1}{C} \sum_{c=1}^{C} \frac{TP_c}{TP_c + FP_c + FN_c}\]
where intersection/union computed per class
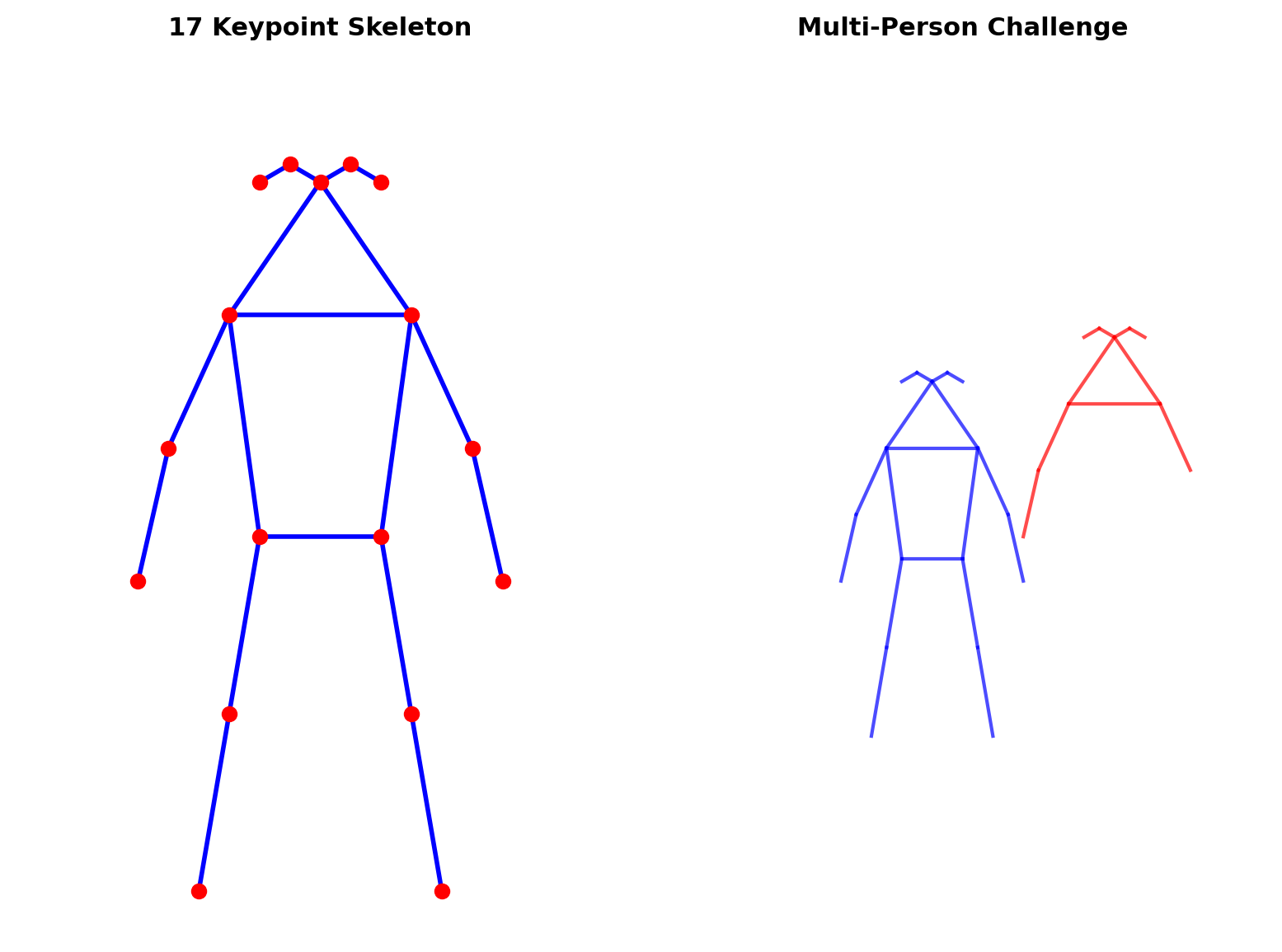
The Pose Estimation Problem
Task Definition
Given image \(I \in \mathbb{R}^{H \times W \times 3}\)
Predict keypoints \(\{p_k\}_{k=1}^K\) where \(p_k = (x_k, y_k)\)
COCO Keypoint Format (K=17)
- 5 facial points (nose, eyes, ears)
- 6 upper body (shoulders, elbows, wrists)
- 6 lower body (hips, knees, ankles)
Complexity Levels
- Single person: \(f: I \rightarrow \mathbb{R}^{K \times 2}\)
- Multi-person: \(f: I \rightarrow \mathcal{P}(\mathbb{R}^{K \times 2})\)
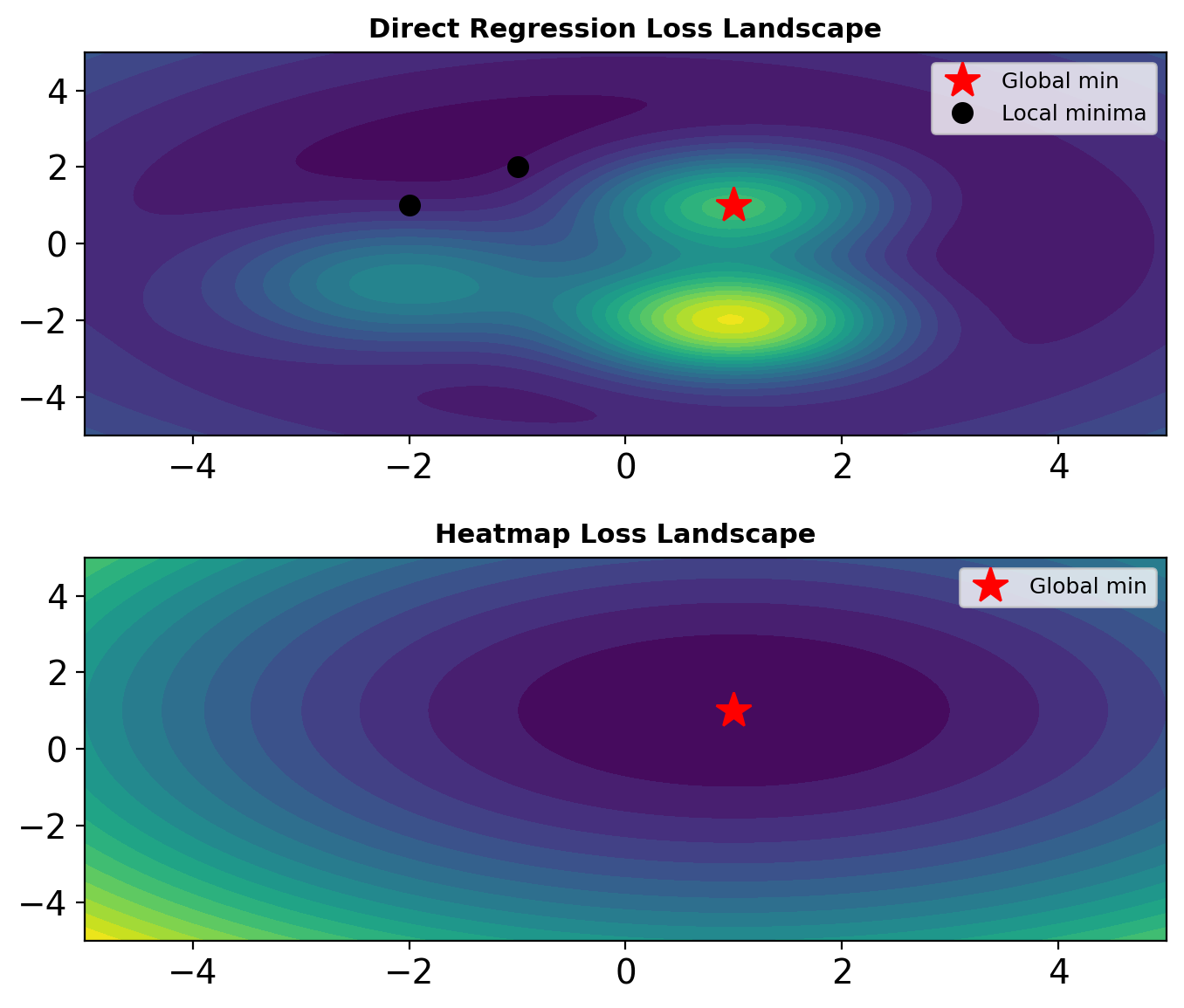
Direct Regression Failure
Regression Approach
Network directly predicts coordinates: \[\hat{p}_k = f_\theta(I) \in \mathbb{R}^2\]
Loss: \(\mathcal{L} = \sum_k ||\hat{p}_k - p_k^*||^2\)
Why It Fails
- Non-convex optimization landscape
- No spatial context preservation
- Arbitrary coordinate system
- Poor gradient flow for distant errors
Empirical result: ~20% lower accuracy than heatmap methods
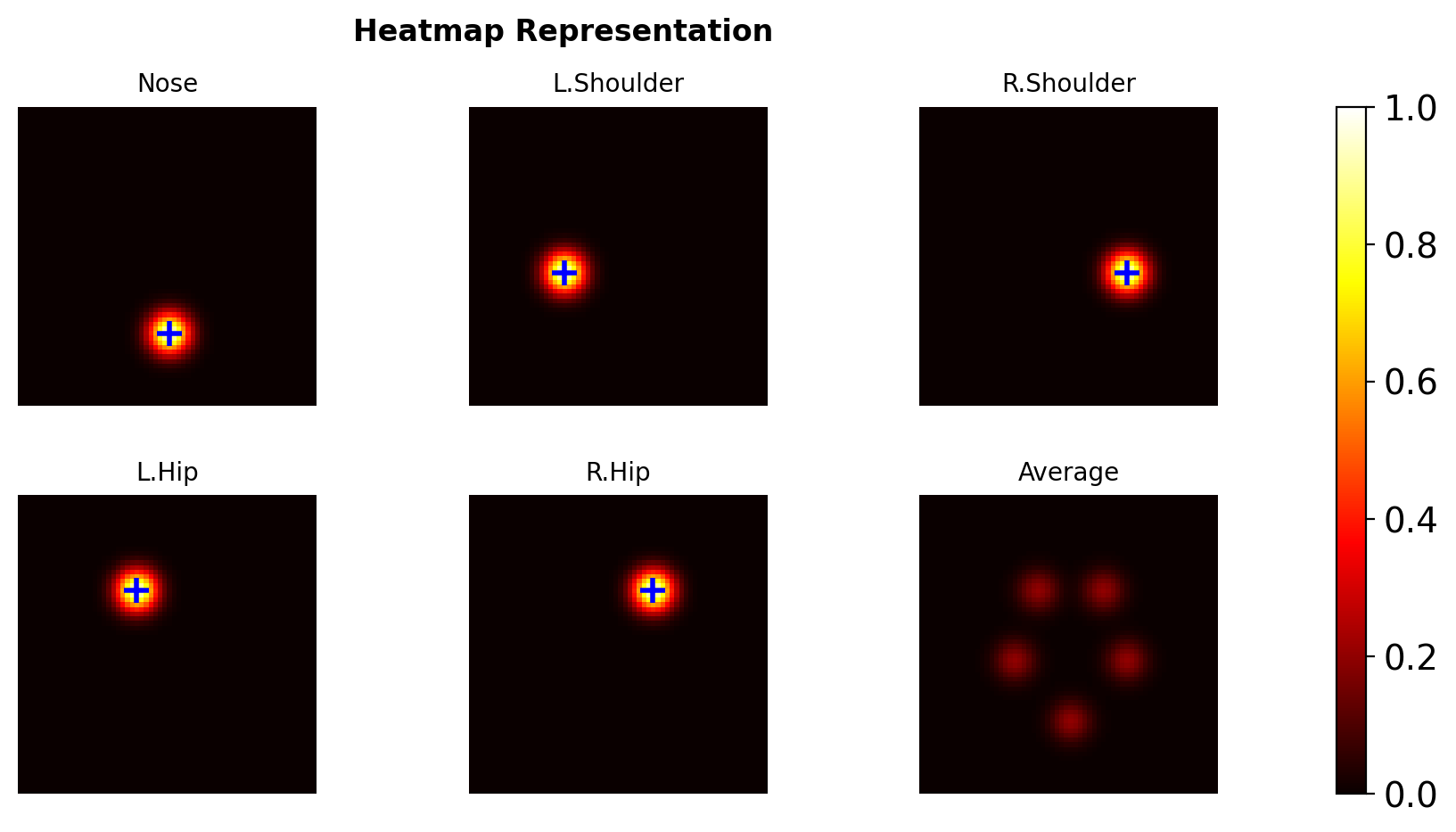
Heatmap Representation
Spatial Probability Maps
Output: \(H \in \mathbb{R}^{H' \times W' \times K}\)
Each channel \(H_k\) represents probability that keypoint \(k\) exists at each location.
Gaussian Targets
Ground truth heatmap for keypoint \(k\) at \(p_k^*\):
\[G_k(p) = \exp\left(-\frac{||p - p_k^*||^2}{2\sigma^2}\right)\]
where \(\sigma\) controls spatial precision
Typical: \(\sigma = 1\) pixel at output resolution
Heatmap Generation and Loss
Training Process
- Generate ground truth heatmaps \(G_k\)
- Network predicts \(\hat{H}_k\)
- Apply MSE loss:
\[\mathcal{L} = \frac{1}{KHW} \sum_{k=1}^K \sum_{i,j} (G_k[i,j] - \hat{H}_k[i,j])^2\]
Inference
Extract keypoint locations: \[\hat{p}_k = \arg\max_{(i,j)} \hat{H}_k[i,j]\]
Sub-pixel refinement:
- Taylor expansion around maximum
- Weighted average in local window
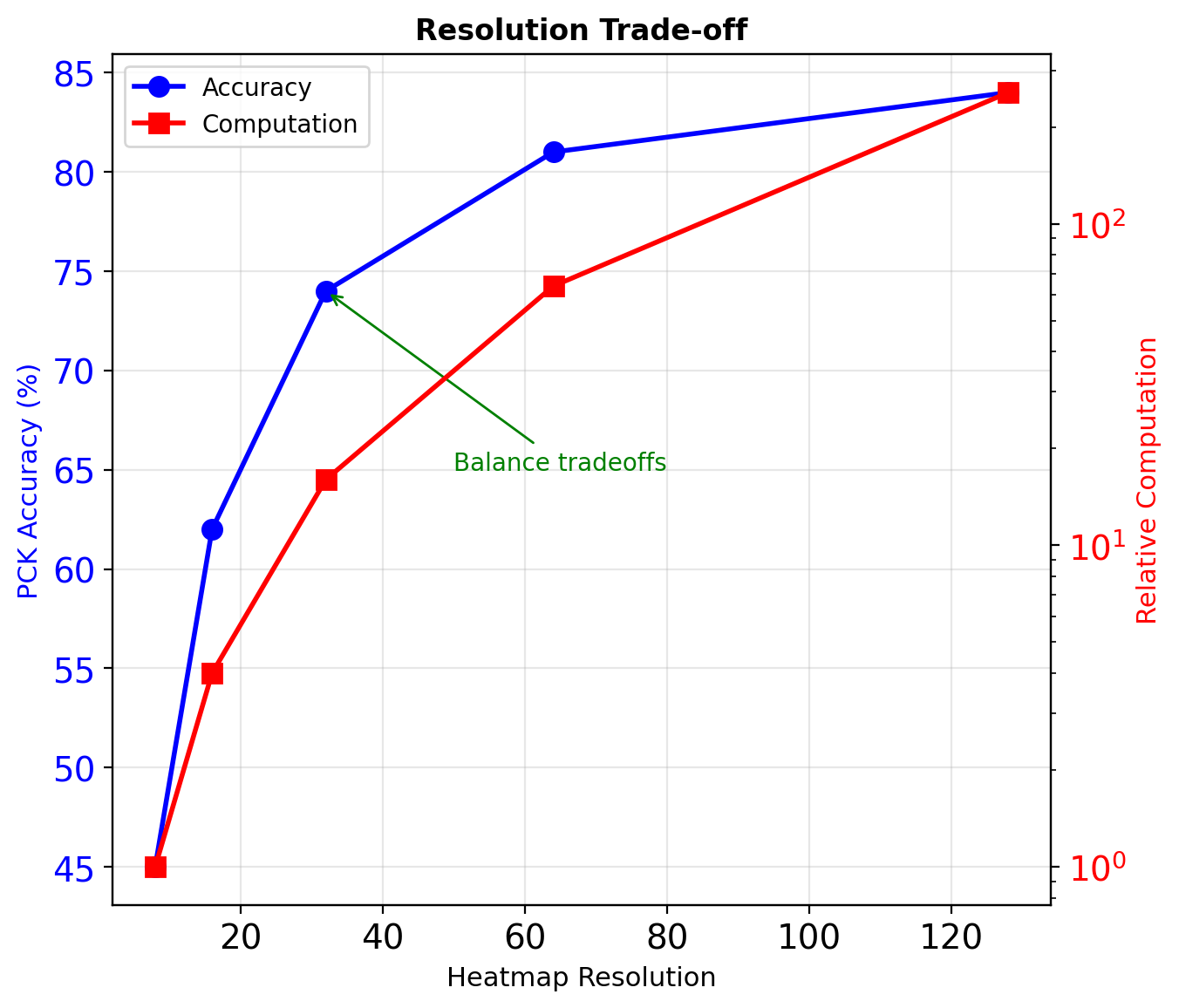
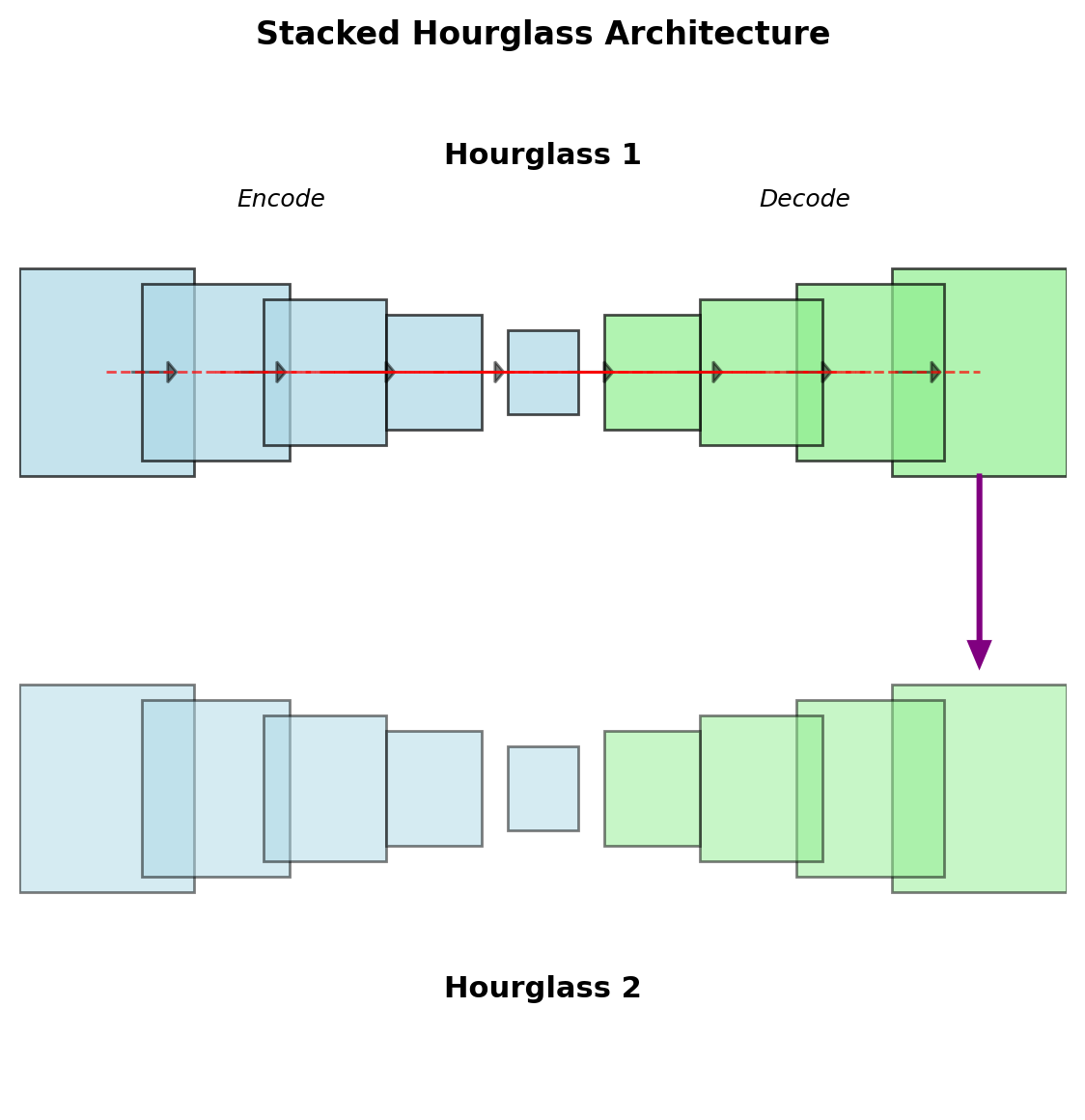
Multi-Scale Processing: Hourglass Networks
Architecture Pattern
Repeated encoding-decoding:
- Downsample to capture context
- Upsample to localize precisely
- Skip connections preserve details
- Stack multiple hourglasses
Intermediate Supervision
Loss at each hourglass output: \[\mathcal{L} = \sum_{t=1}^T \lambda_t \mathcal{L}_t\]
where \(T\) = number of hourglasses
Typical: \(T=2\) to \(T=8\), \(\lambda_t = 1\)
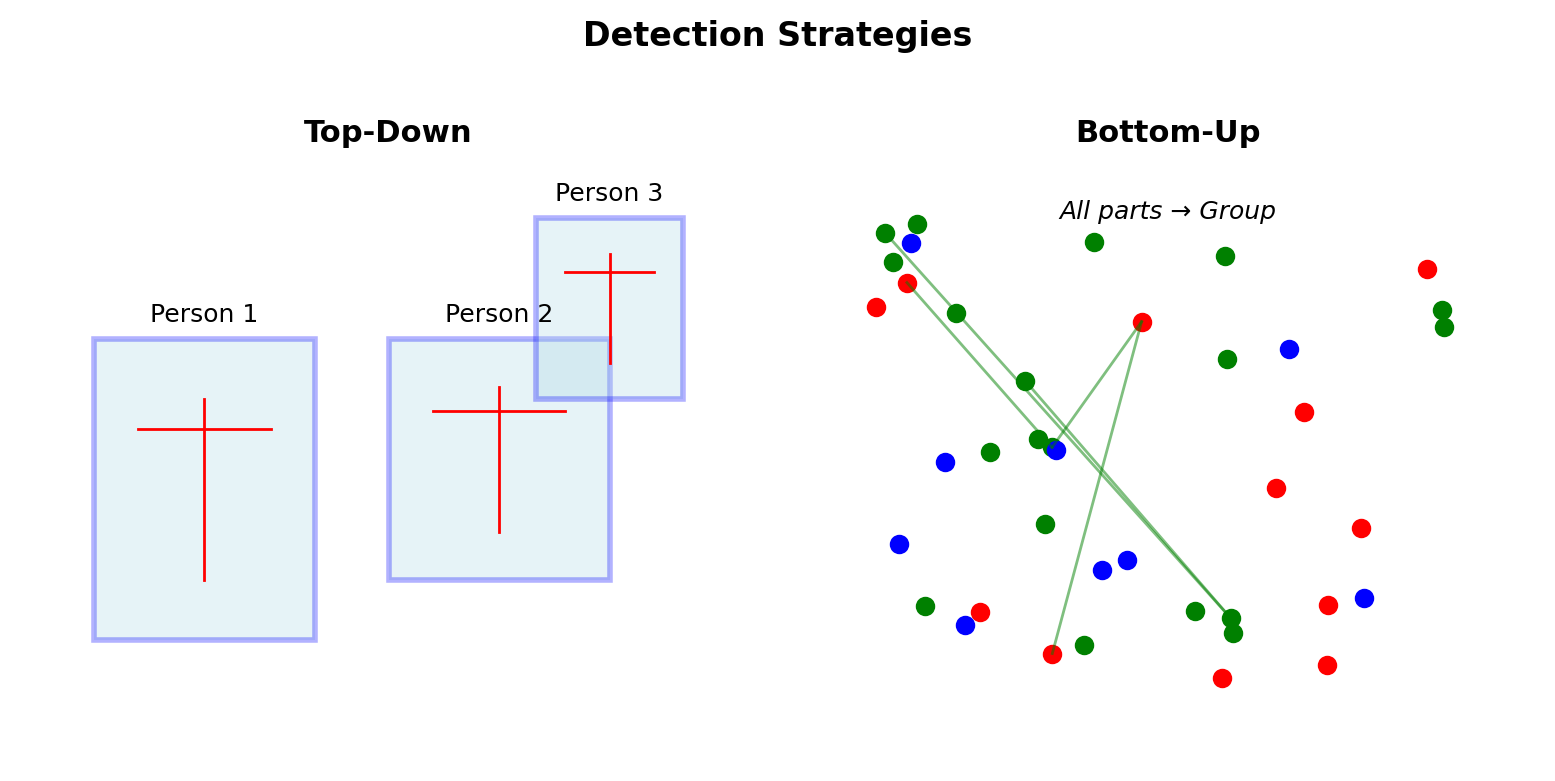
Bottom-Up vs Top-Down Approaches
Top-Down (Person First)
- Detect person bounding boxes
- Crop and resize each person
- Estimate pose per person
- Scale back to image coordinates
Complexity: \(O(N \cdot T_{pose})\)
Bottom-Up (Parts First)
- Detect all keypoints in image
- Learn affinity between parts
- Group keypoints into people
Complexity: \(O(T_{detect} + N^2)\) for association
\(N\) = number of people
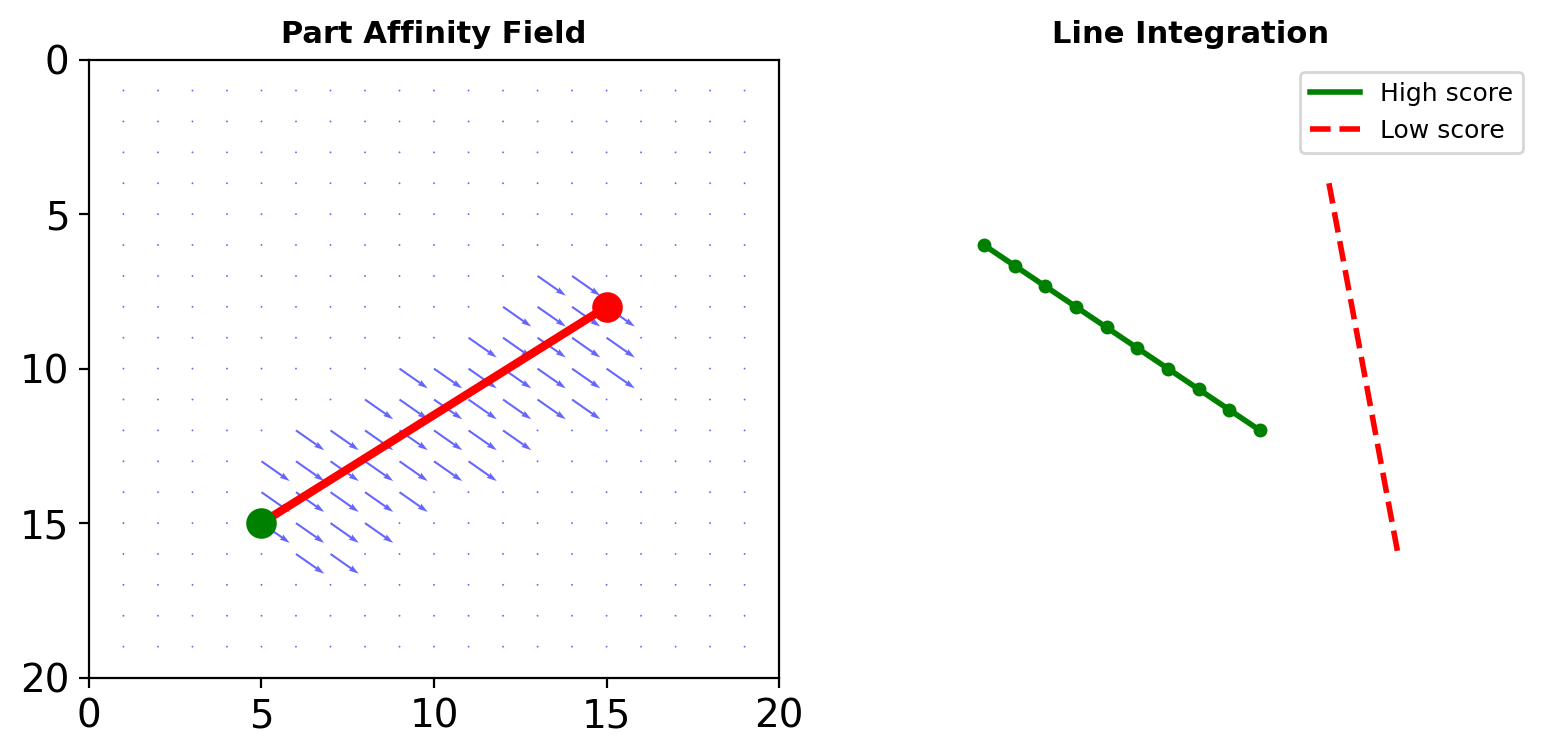
Part Affinity Fields (OpenPose)
Vector Fields for Limbs
Between keypoints \(j_1\) and \(j_2\), define:
\[\mathbf{L}(p) = \begin{cases} \mathbf{v} & \text{if } p \text{ on limb} \\ \mathbf{0} & \text{otherwise} \end{cases}\]
where \(\mathbf{v} = \frac{j_2 - j_1}{||j_2 - j_1||}\) (unit vector)
Association Score
Score for connecting candidates \(d_{j_1}\) and \(d_{j_2}\):
\[E = \int_0^1 \mathbf{L}(p(u)) \cdot \frac{d_{j_2} - d_{j_1}}{||d_{j_2} - d_{j_1}||} du\]
Approximated by sampling along line
Multi-Person Association
Graph Matching Problem
Given detected parts, find optimal grouping:
\[\max \sum_{c \in \mathcal{C}} \sum_{(j_1, j_2) \in c} E_{j_1,j_2}\]
subject to: no part used twice
Solutions
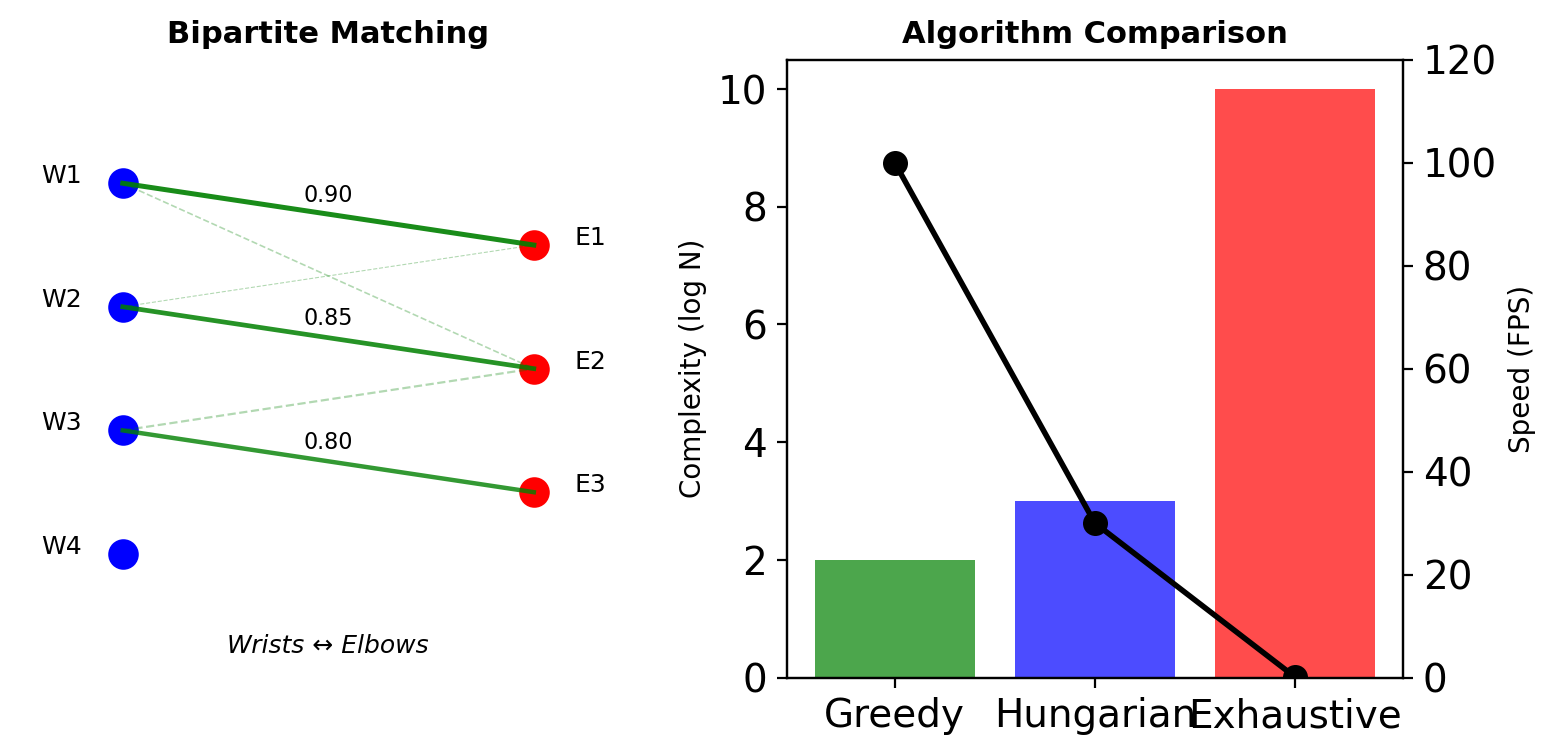
Greedy: Sort by PAF score, assign sequentially
- Fast: \(O(N^2 \log N)\)
- Suboptimal
Hungarian Algorithm: Optimal bipartite matching
- Optimal solution
- \(O(N^3)\) complexity
In practice: Greedy works well (OpenPose)
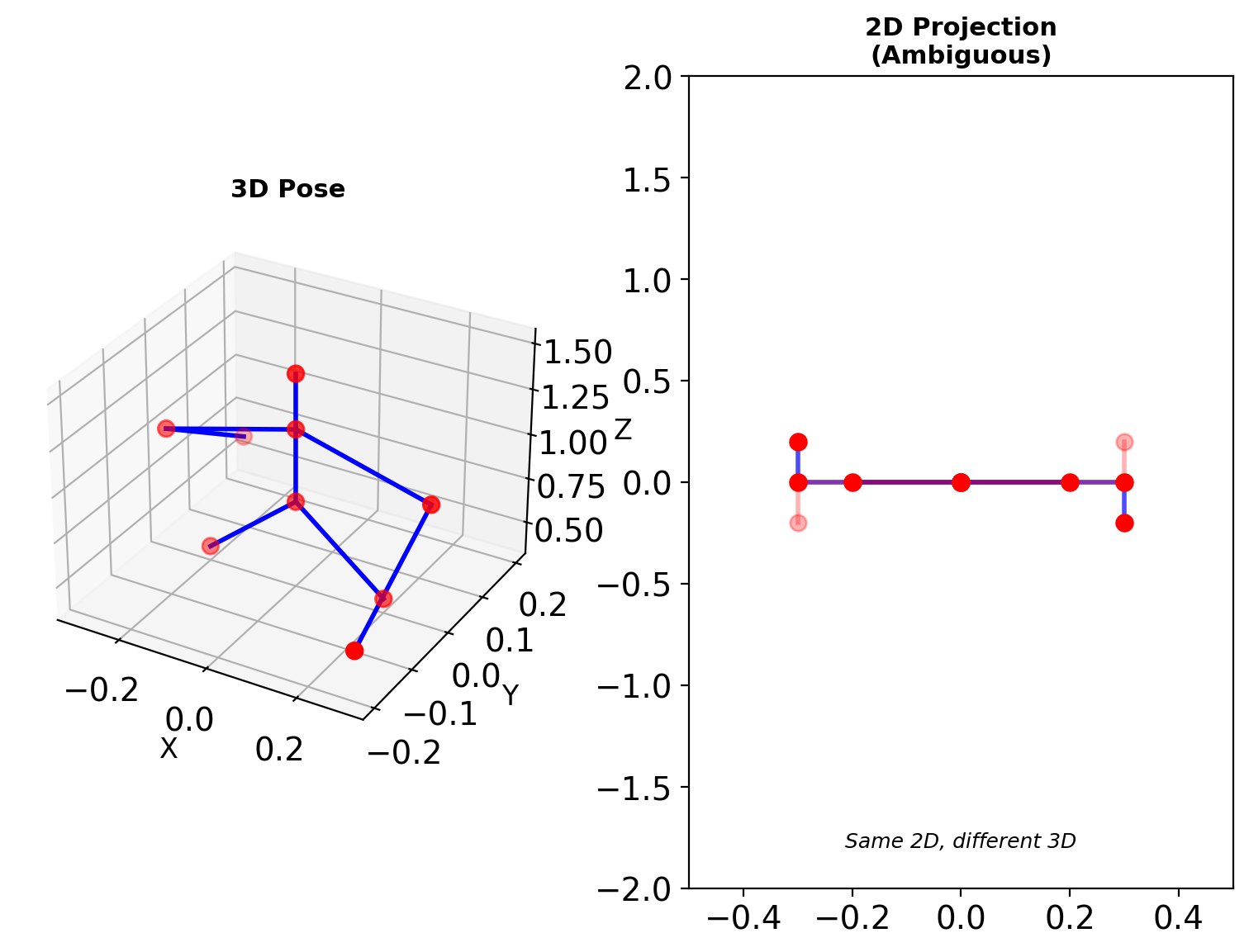
3D Pose Estimation
Approaches
2D → 3D Lifting:
- Detect 2D pose first
- Learn mapping to 3D
- Ambiguity from single view
Direct 3D Prediction:
- Volumetric heatmaps: \(\mathbb{R}^{H \times W \times D \times K}\)
- Massive memory requirements
- Multi-view fusion helps
Depth Ambiguity
Multiple 3D poses project to same 2D: \[\pi(P_{3D}) = p_{2D}\]
Need priors or multiple views
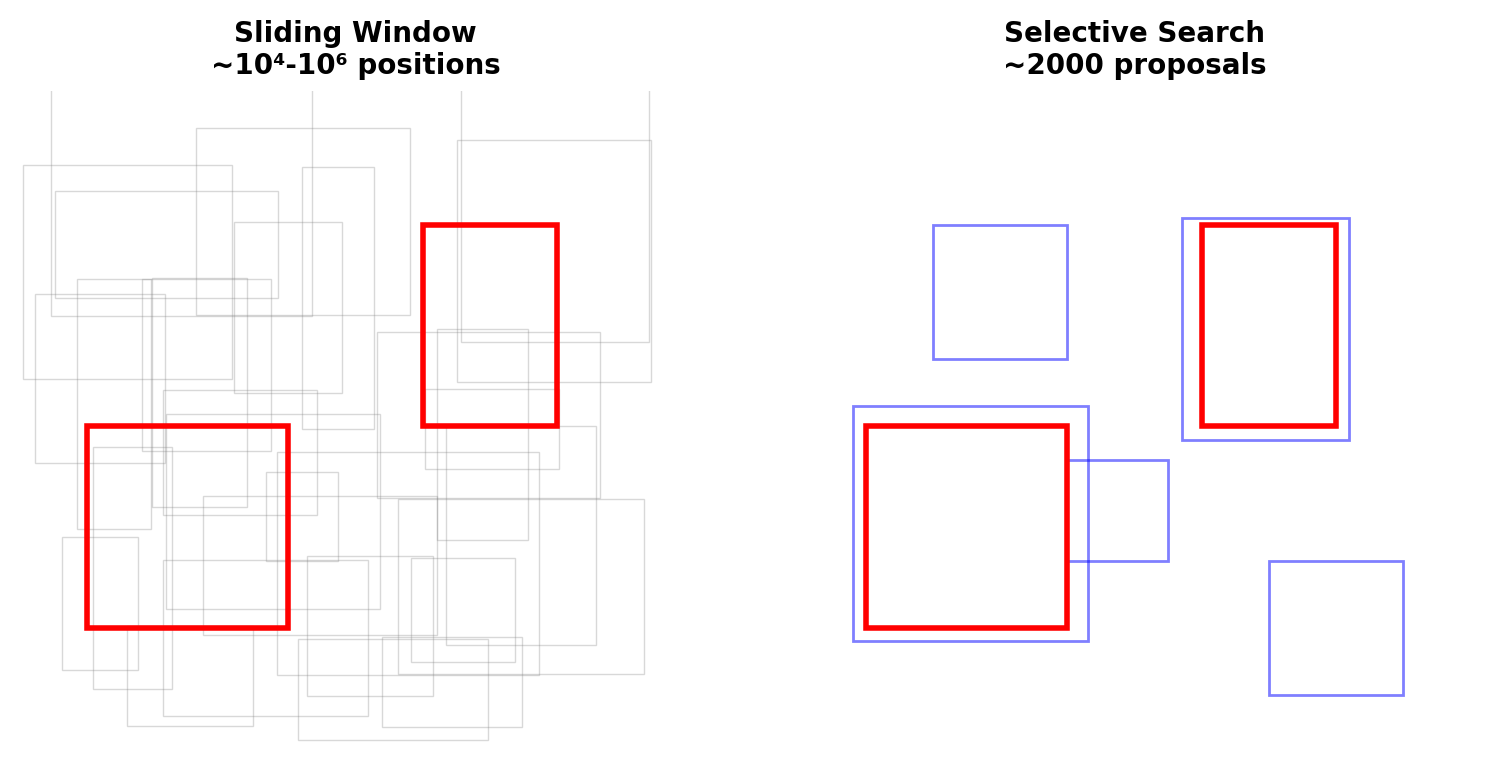
The Detection Pipeline Decomposition
Approach 1: Two-Stages
Stage 1: Where might objects be?
- ~2000 region proposals
- Class-agnostic
- High recall target
Stage 2: What is in each region?
- CNN classification
- Bounding box refinement
- Allows computationally intensive models
Decoupling Rationale
Reduces search space from ~10⁶ sliding windows to ~10³ proposals
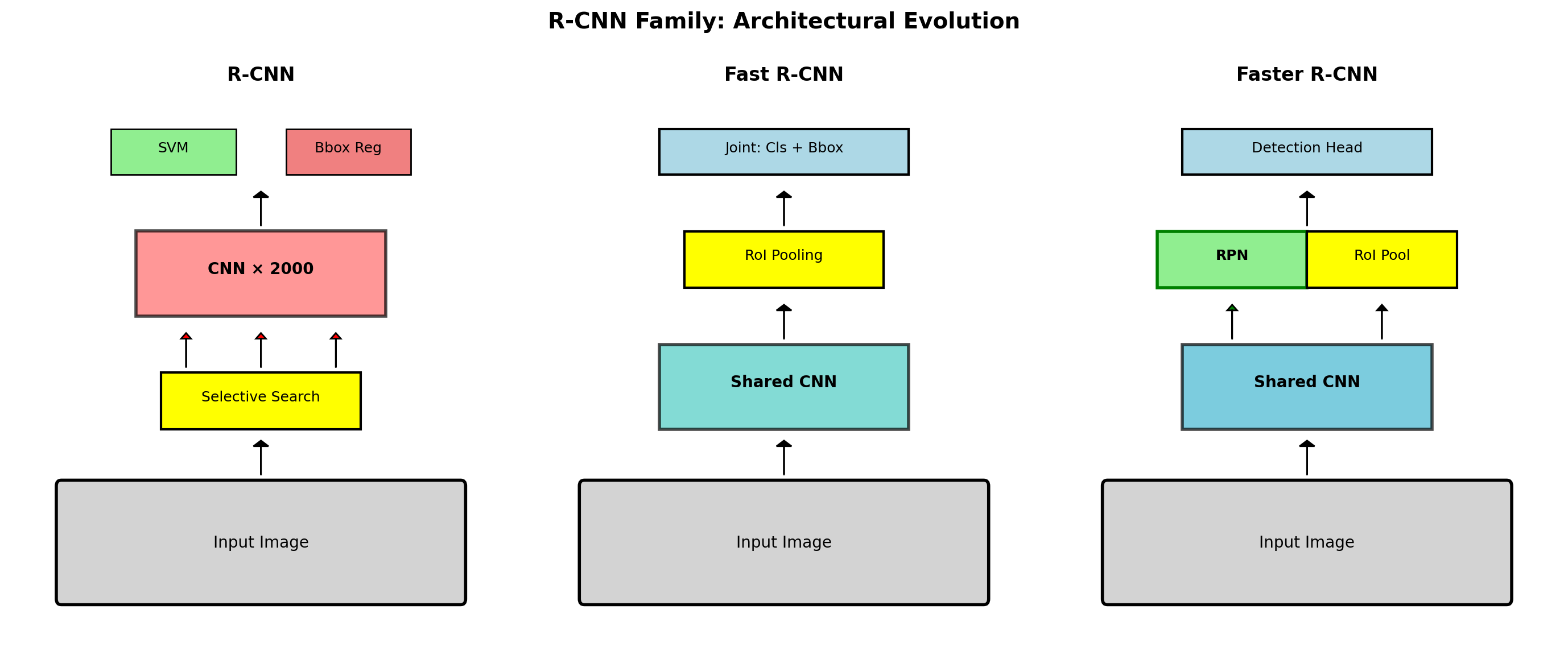
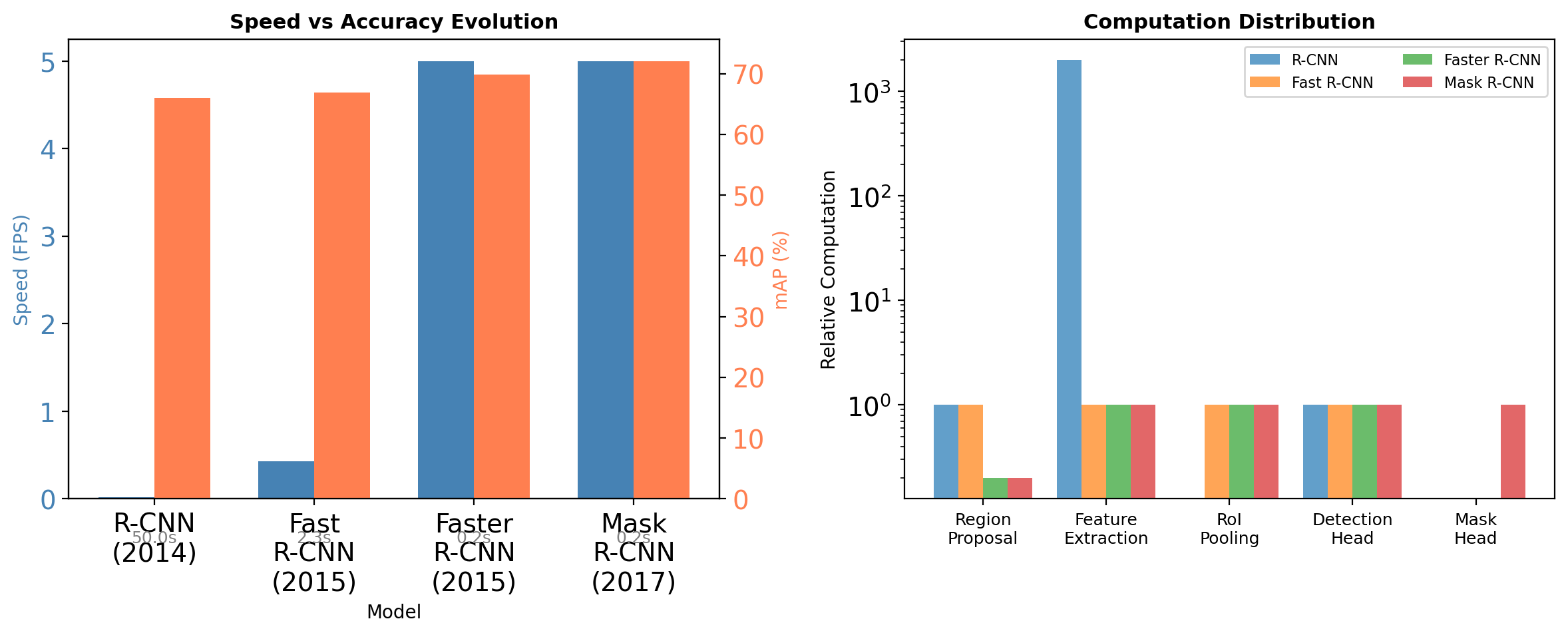
R-CNN: Region-based CNN (2014)
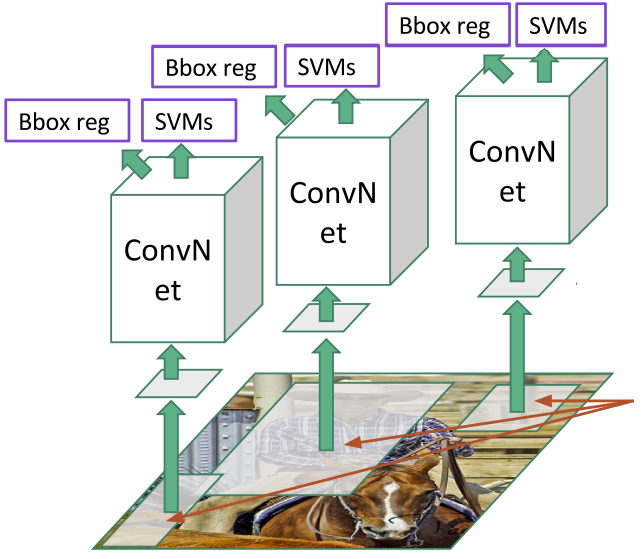
Approach: Apply CNN to region proposals
Pipeline:
- Selective Search: ~2000 region proposals
- Warp: Resize each region to 227×227
- AlexNet quirk: 11×11 kernel, stride 4 = 227×227
- CNN: Extract features (AlexNet/VGG)
- SVM: Classify each region
- Bbox Regression: Refine locations
# Pseudocode
for image in dataset:
regions = selective_search(image) # ~2000 regions
for region in regions: # Sequential!
warped = resize_to_227x227(region)
features = alexnet.forward(warped) # Full forward pass
class_scores = svm_classify(features)
bbox_refined = bbox_regressor(features)Limitations:
- Slow: 47s/image (2000 forward passes)
- Multi-stage training (CNN, SVM, regressors)
- Disk storage for features
Training Complexity:
- Pre-train CNN on ImageNet
- Fine-tune on detection data
- Train separate SVMs for each class
- Train bounding box regressors
R-CNN Architecture
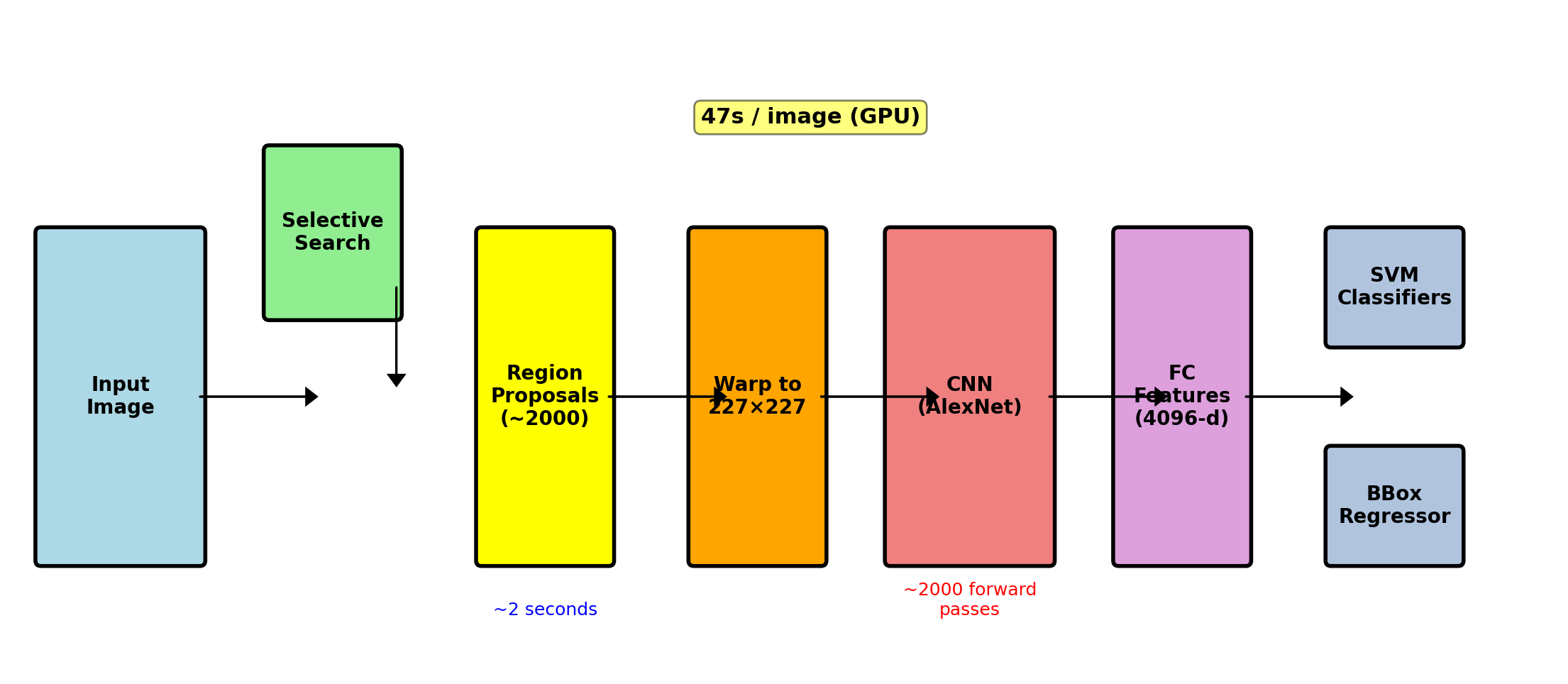
Each region processed independently → no shared computation
R-CNN Training Protocol
Multi-Stage Training
Stage 1: Pre-training
- ImageNet classification (1000 classes)
- Standard AlexNet training
Stage 2: Fine-tuning
- Replace 1000-way FC with (N+1)-way
- Positive: IoU ≥ 0.5 with ground truth
- Negative: IoU < 0.5
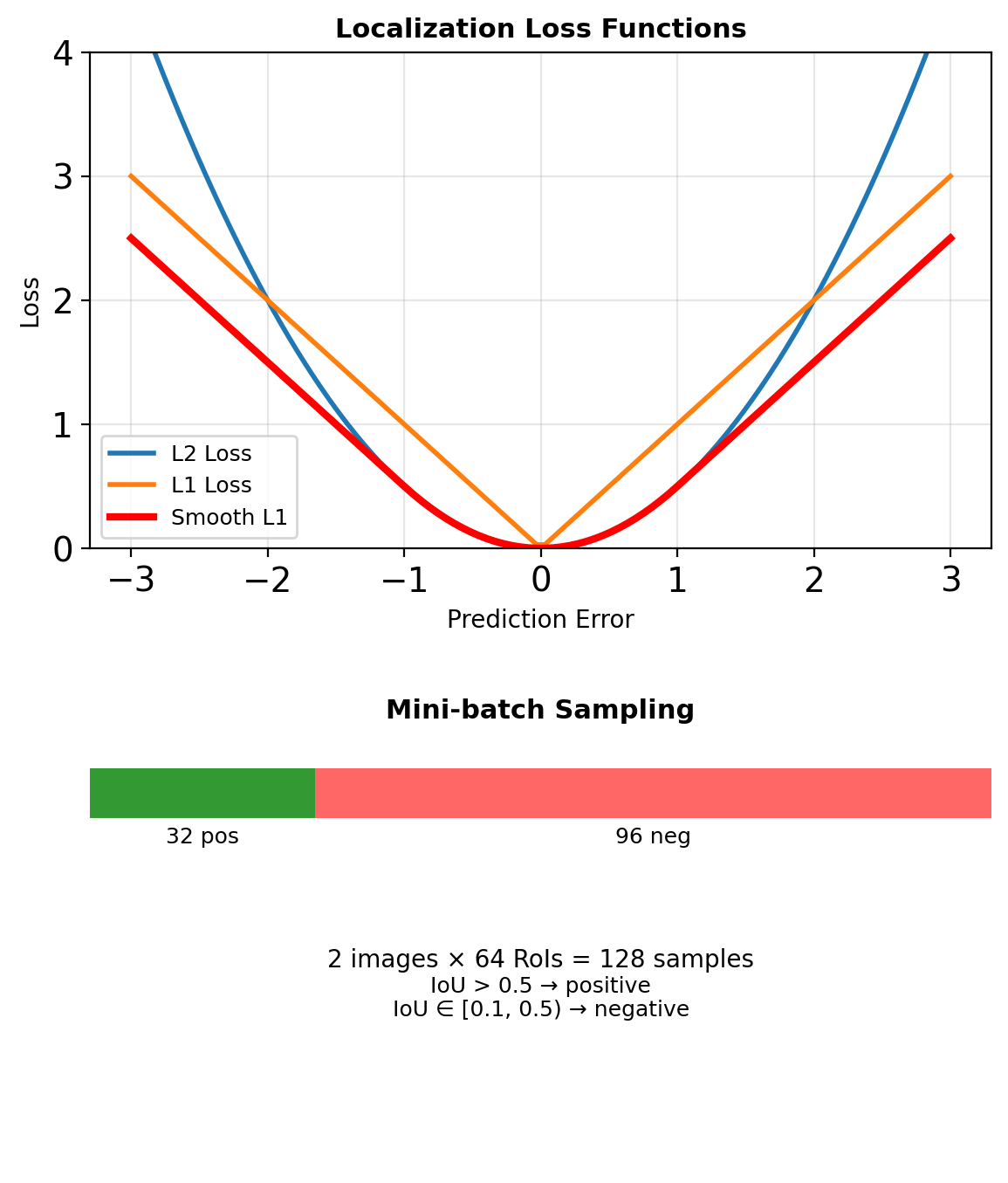
- Mini-batch: 32 positive + 96 negative
Stage 3: SVM Training
- Extract features for all proposals
- Positive: ground truth only
- Negative: IoU < 0.3
- Hard negative mining
Stage 4: Bounding Box Regression
- Learn \((t_x, t_y, t_w, t_h)\) transforms
- Ridge regression on pool5 features
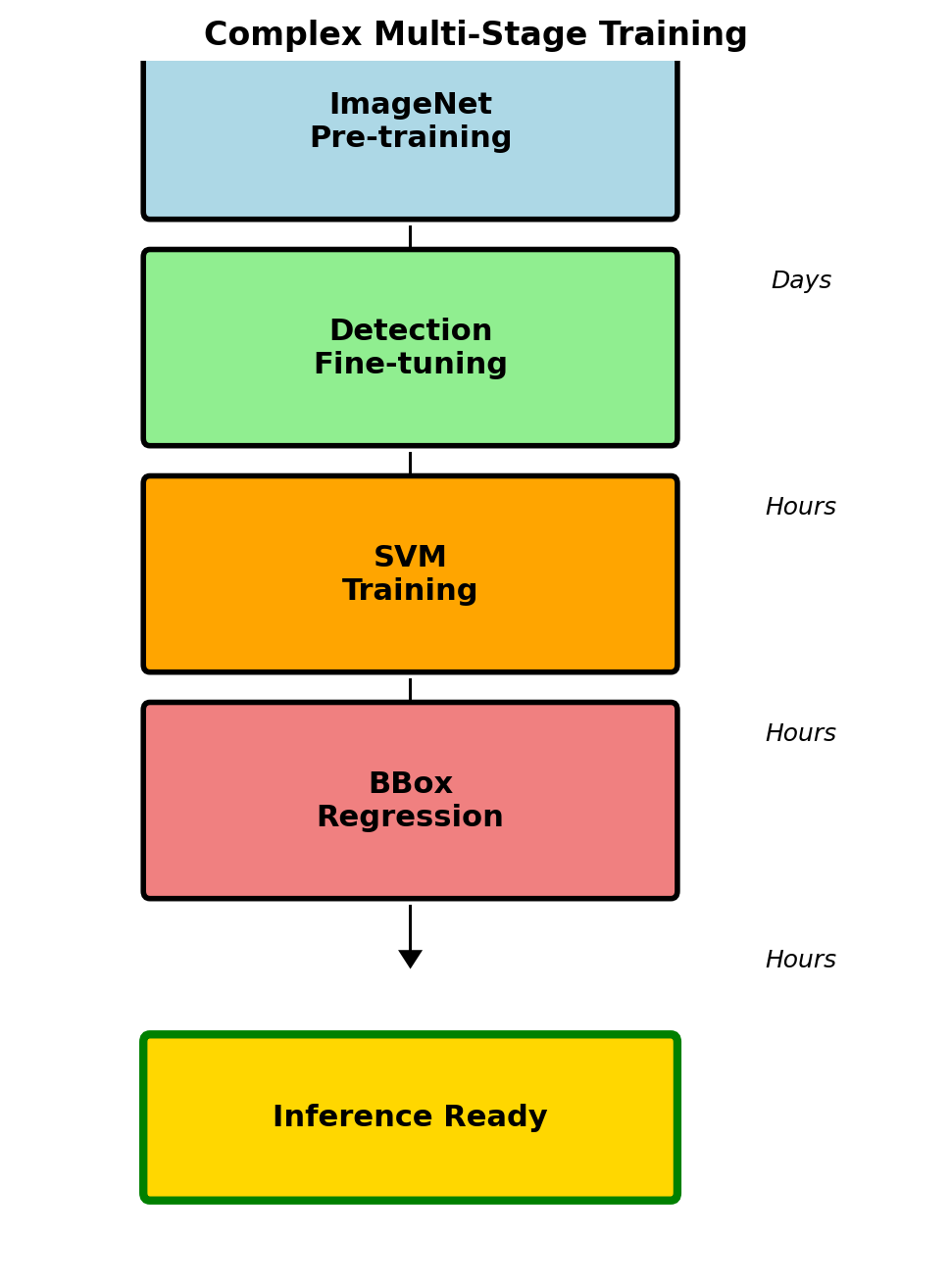
This complexity stems from historical constraints: end-to-end fine-tuning was not well understood
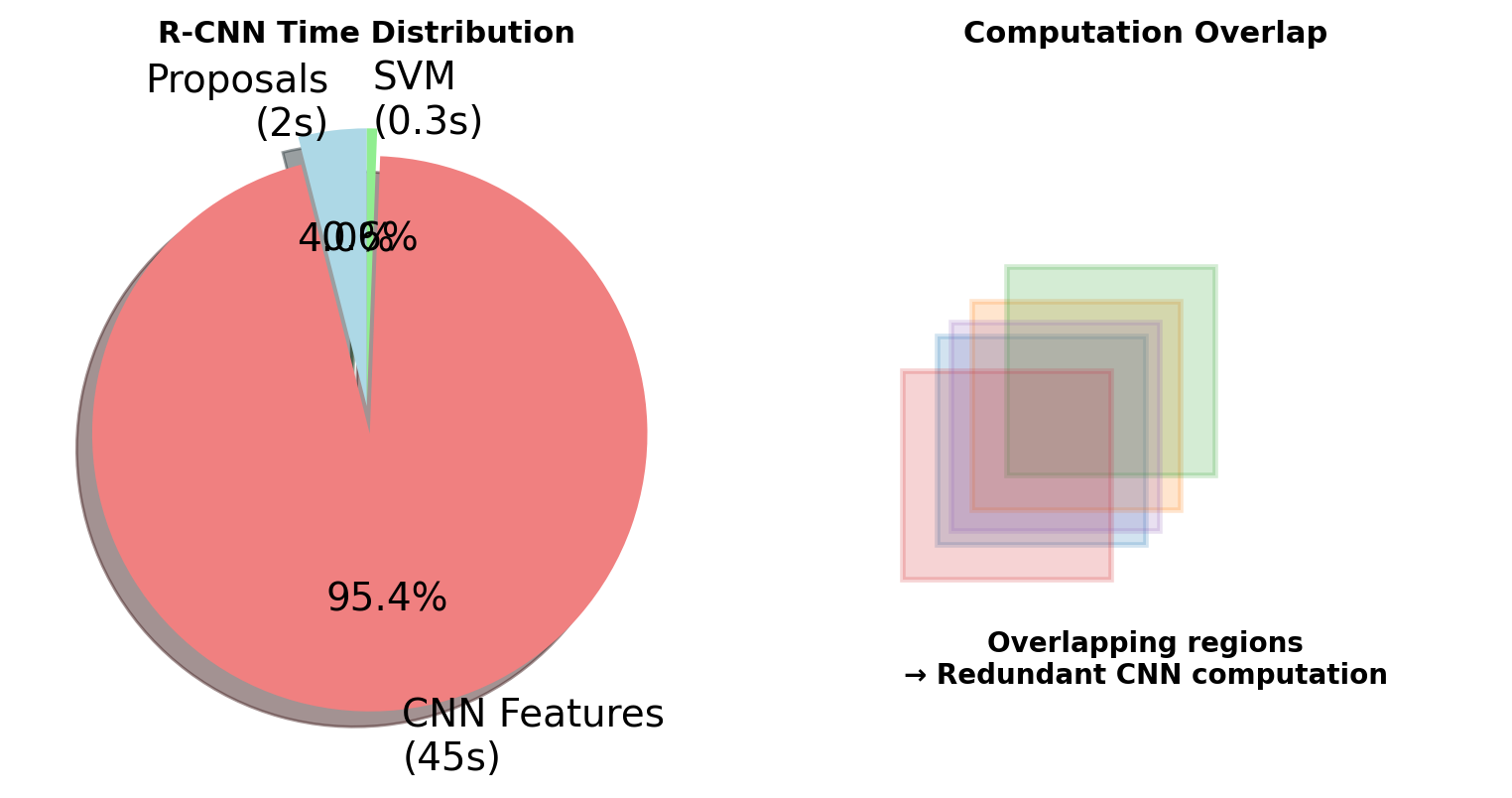
R-CNN Computational Bottleneck
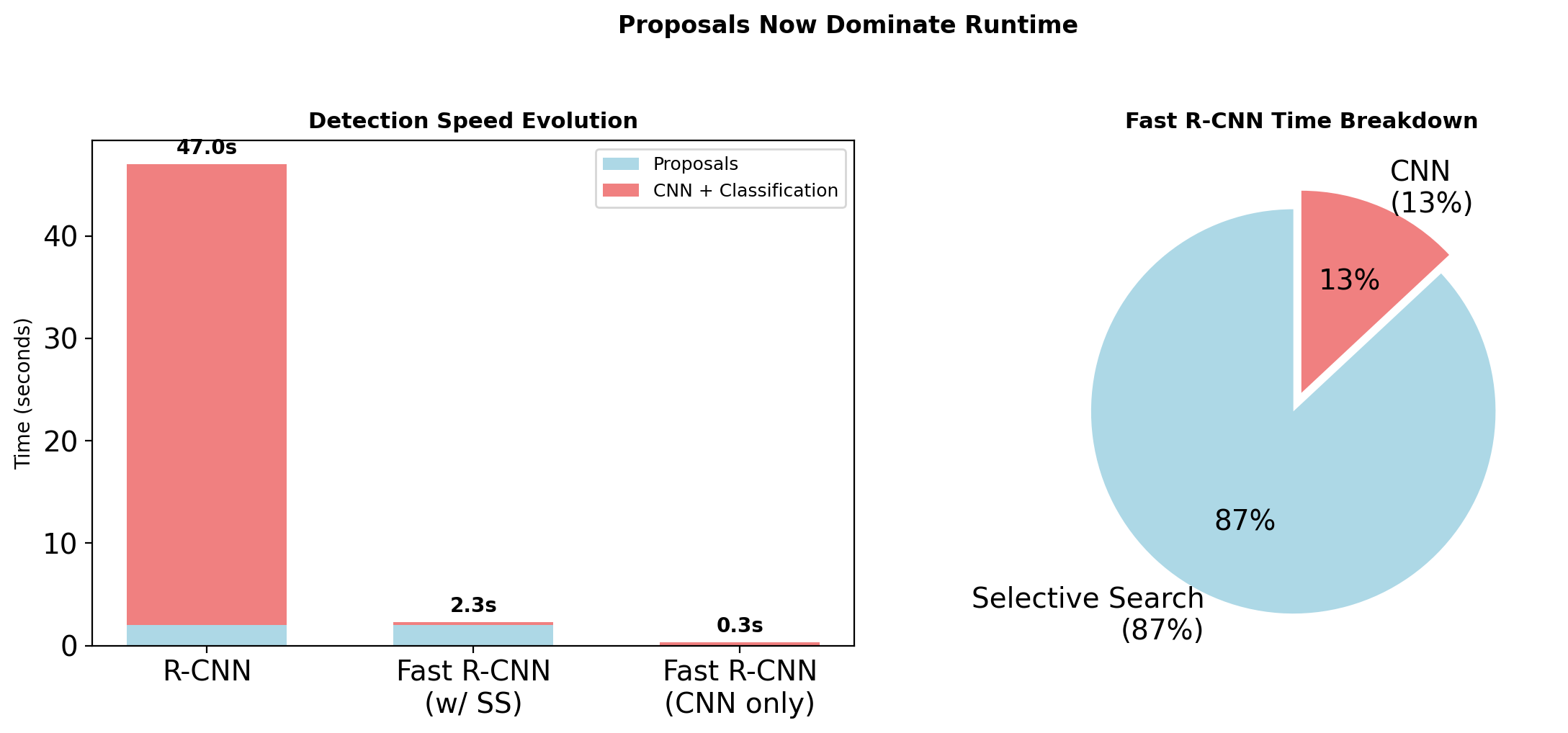
Time Breakdown (per image)
| Component | Time | Percentage |
|---|---|---|
| Selective Search | 2s | 4% |
| Feature Extraction | 45s | 96% |
| - 2000 CNN passes | ||
| - No sharing | ||
| SVM + BBox | 0.3s | <1% |
Takeaway: Repeated feature computation dominates
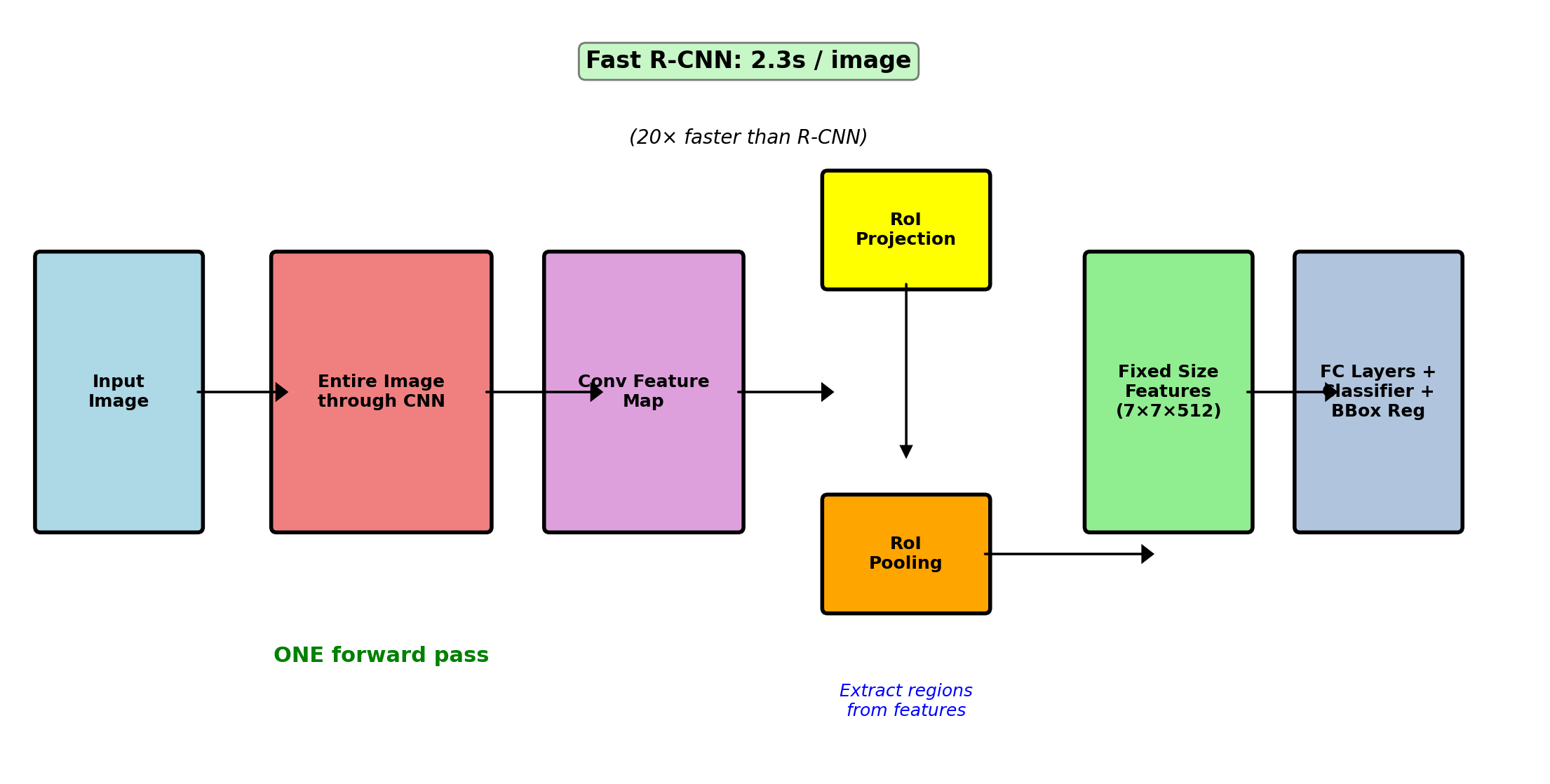
Fast R-CNN: Shared Computation (2015)
Improvment: Share convolutional computation
# Pseudocode
for image in dataset:
# Single forward pass
feature_map = conv_layers.forward(image)
regions = selective_search(image)
for region in regions:
# Project to feature coordinates
roi_features = roi_pool(feature_map, region)
class_scores, bbox_deltas = fc_layers(roi_features)RoI Pooling: Spatial pyramid pooling variant
- Map proposal to conv feature coordinates
- Divide into H×W bins (typically 7×7)
- Max pool within each bin → fixed H×W×C tensor
Joint objective function: \[\mathcal{L} = \mathcal{L}_{cls}(p, u) + \lambda[u \geq 1]\mathcal{L}_{bbox}(t^u, v)\]
- Classification: cross-entropy over C+1 classes
- Regression: smooth L1 on box parameters
Performance: 0.32s/image (146× speedup)
mAP improvement: 66% → 70% on PASCAL VOC
Fast R-CNN: Shared Computation
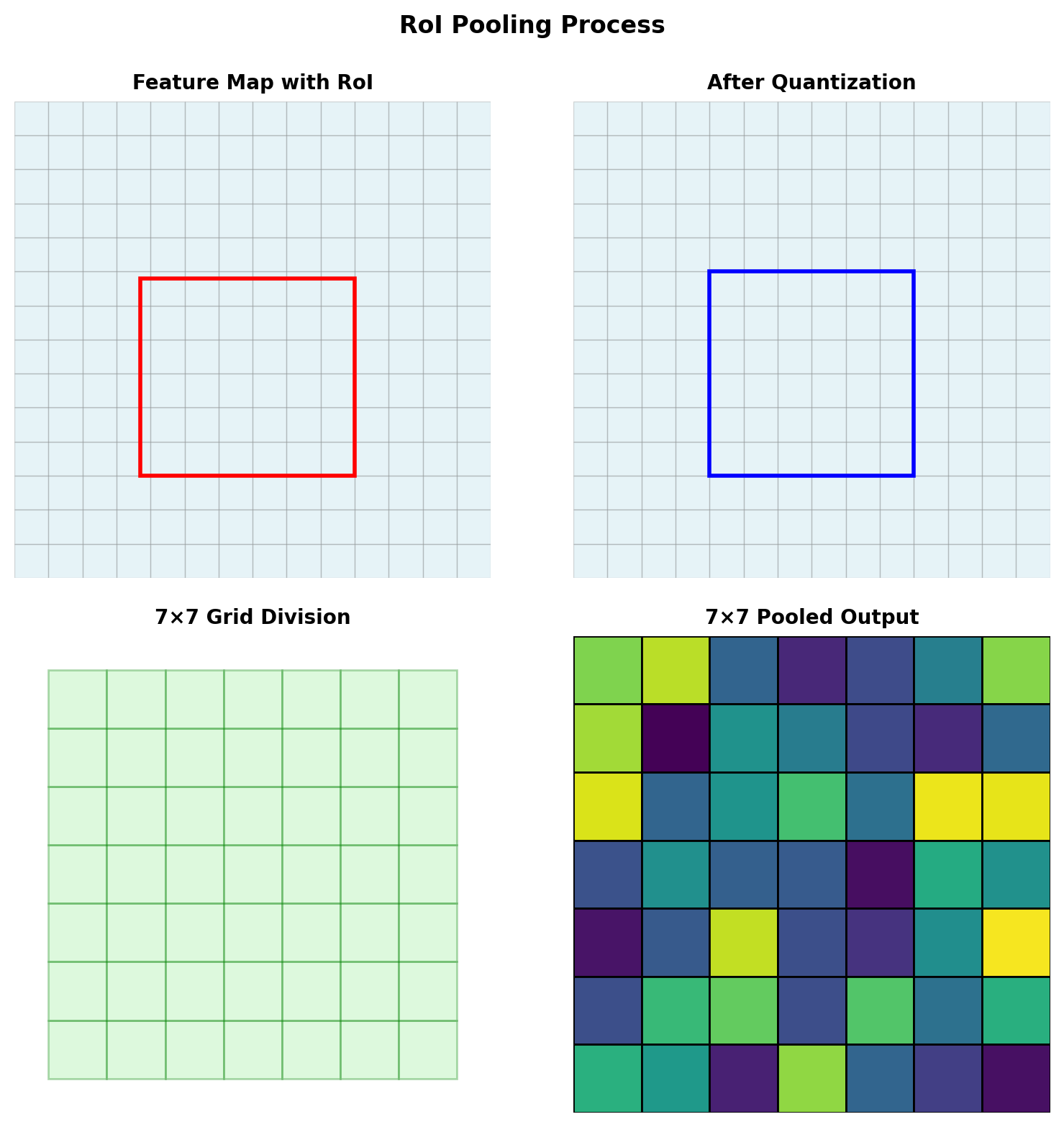
RoI Pooling Math
Operation Definition
Input: Feature map \(F \in \mathbb{R}^{H \times W \times C}\) Region proposal: \((x, y, w, h)\) in image coords
Output: Fixed size \(\mathbb{R}^{H' \times W' \times C}\) (typically \(7 \times 7\))
Algorithm
- Project RoI to feature map: scale by stride
- Divide into \(H' \times W'\) grid
- Max pool within each grid cell
Quantization Problem
\[\tilde{x} = \lfloor x / \text{stride} \rfloor\]
Misalignment accumulates significantly.
Fast R-CNN Training
Joint Multi-Task Loss
\[L(p, u, t^u, v) = L_{cls}(p, u) + \lambda [u \geq 1] L_{loc}(t^u, v)\]
where:
- \(p\): predicted class probabilities
- \(u\): true class
- \(t^u\): predicted box for class \(u\)
- \(v\): true box
- \([u \geq 1]\): indicator (no regression for background)
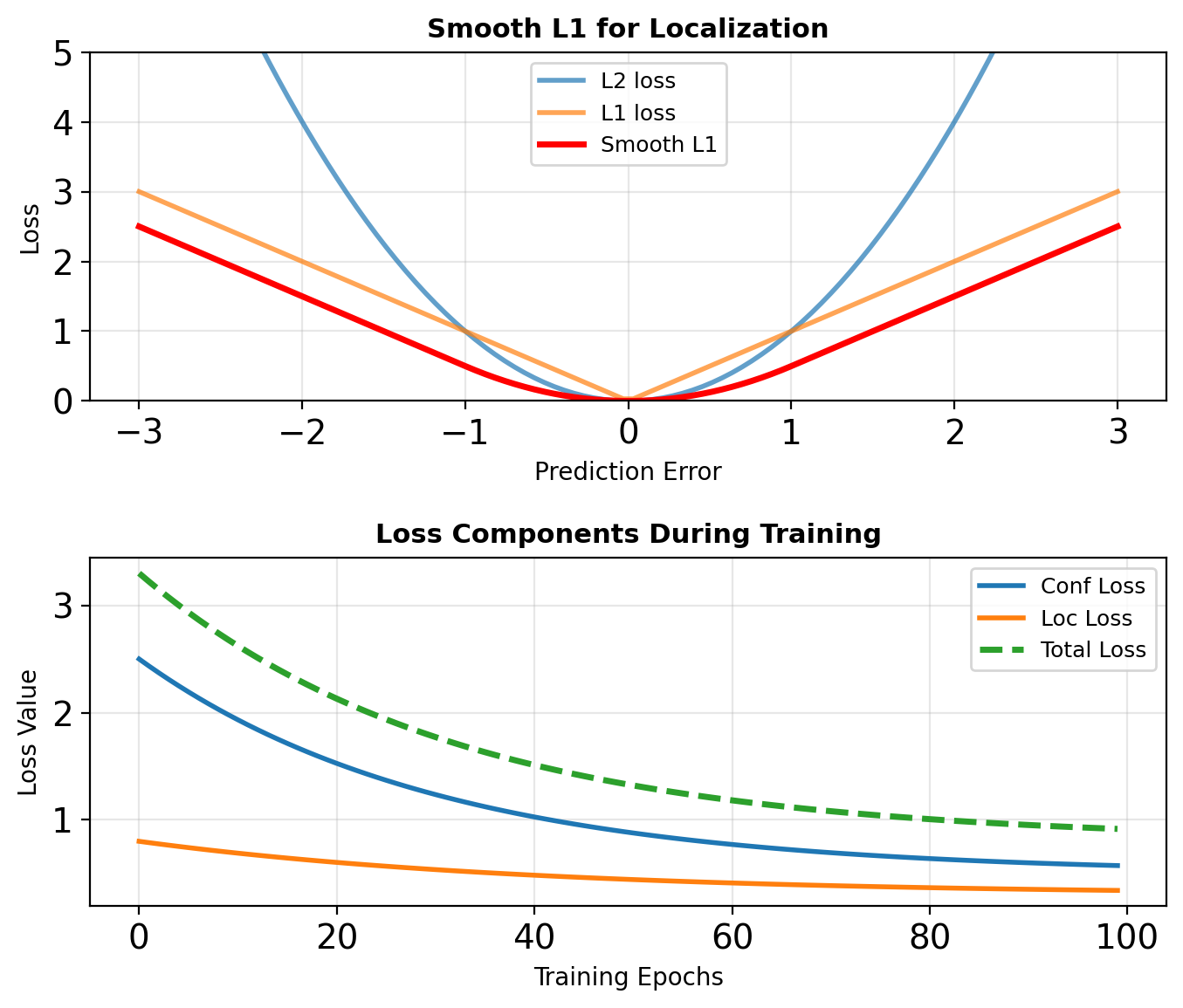
Smooth L1 Loss
\[L_{loc}(t, v) = \sum_{i \in \{x,y,w,h\}} \text{smooth}_{L1}(t_i - v_i)\]
\[\text{smooth}_{L1}(x) = \begin{cases} 0.5x^2 & \text{if } |x| < 1 \\ |x| - 0.5 & \text{otherwise} \end{cases}\]
Region Proposal Bottleneck
Objective: Learn region proposals with a CNN
Faster R-CNN: Learning to Propose (2015)
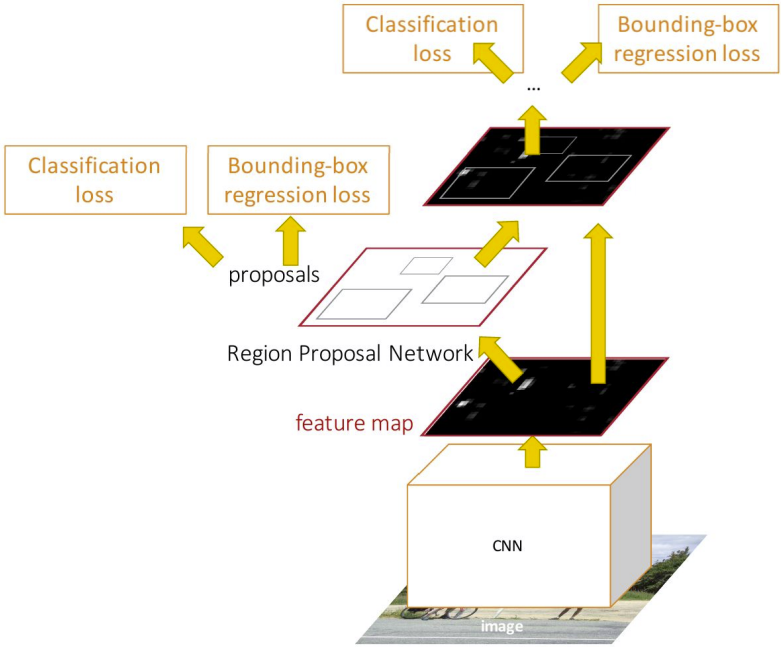
Innovation: Region Proposal Network (RPN)
RPN Components:
- 3×3 conv on feature map
- Two sibling heads:
- cls: 2k scores (object/background)
- reg: 4k coordinates (box refinements)
- k = number of anchors (typically 9)
Two-Stage Architecture:
Stage 1: RPN
- Generate ~300 proposals from anchors
- Binary classification: object vs background
Stage 2: Detection
- Classify proposals (C+1 classes)
- Refine bounding boxes
4-Way Loss Function:
- RPN classification loss (object/not)
- RPN regression loss (proposal refinement)
- Fast R-CNN classification loss (final class)
- Fast R-CNN regression loss (final box)
Speed: 0.2s/image (10 FPS) | Accuracy: State-of-the-art at release
Faster R-CNN: Region Proposal Network
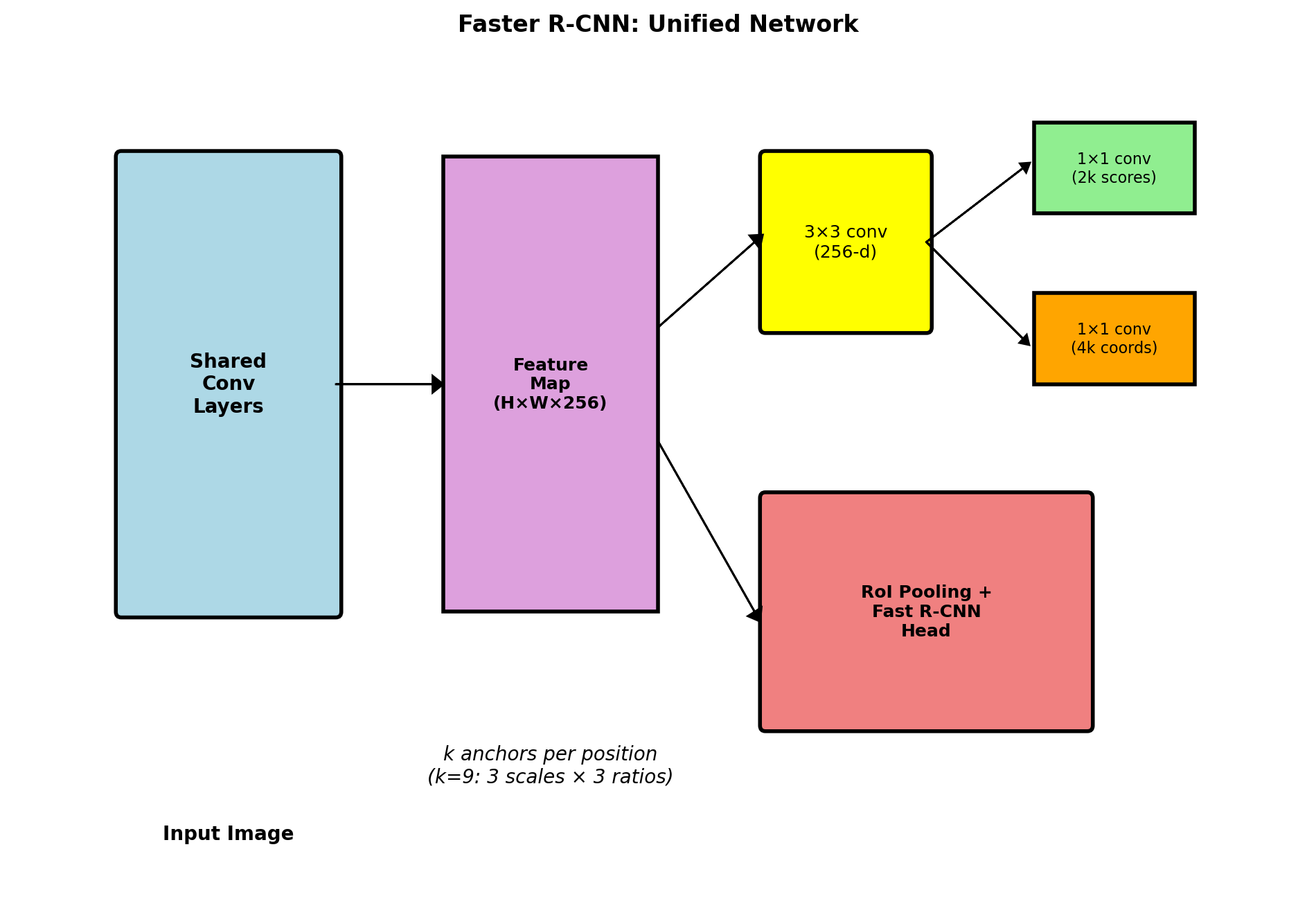
RPN Training
Anchor Assignment
Positive (object):
- IoU > 0.7 with any GT box
- Highest IoU for each GT box
Negative (background):
- IoU < 0.3 with all GT boxes
Ignored:
- IoU ∈ [0.3, 0.7]
Loss Function
\[L = \frac{1}{N_{cls}} \sum_i L_{cls}(p_i, p_i^*) + \lambda \frac{1}{N_{reg}} \sum_i p_i^* L_{reg}(t_i, t_i^*)\]
- Binary classification (object vs background)
- Regression only for positive anchors
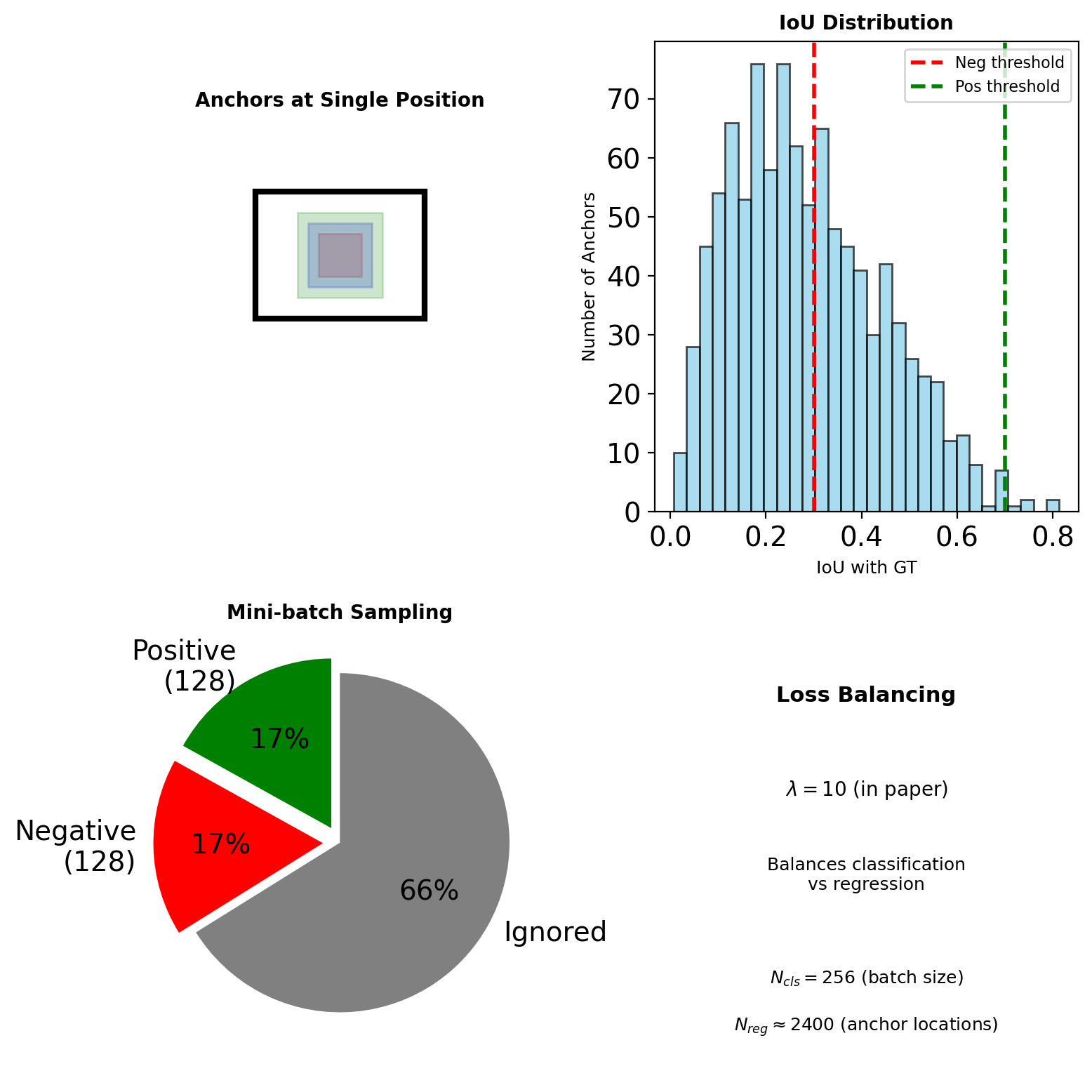
Anchor Design and Coverage
Multi-Scale Detection
Approach 1: Image pyramids
- Multiple scales of input
- Computationally expensive
Approach 2: Feature pyramids
- Multiple filter sizes
- More parameters
Approach 3: Anchor pyramids
- Multiple anchor scales/ratios
- Cost-free at test time
COCO Configuration
- Scales: {32², 64², 128², 256², 512²}
- Ratios: {1:2, 1:1, 2:1}
- 15 anchors per position (5×3)
Non-Maximum Suppression (NMS)
The Duplicate Detection Problem
Single object → multiple overlapping detections
- Adjacent anchors fire
- Multiple scales detect same object
- Overlapping receptive fields
NMS Algorithm
def nms(boxes, scores, threshold):
# Sort by confidence
indices = argsort(scores, descending=True)
keep = []
while indices:
# Keep highest scoring box
i = indices[0]
keep.append(i)
# Compute IoU with remaining
ious = compute_iou(boxes[i], boxes[indices[1:]])
# Remove high overlap boxes
indices = indices[1:][ious < threshold]
return keepThreshold selection:
- 0.5: Standard (misses nearby objects)
- 0.7: Lenient (duplicate detections)
- Class-specific vs global NMS
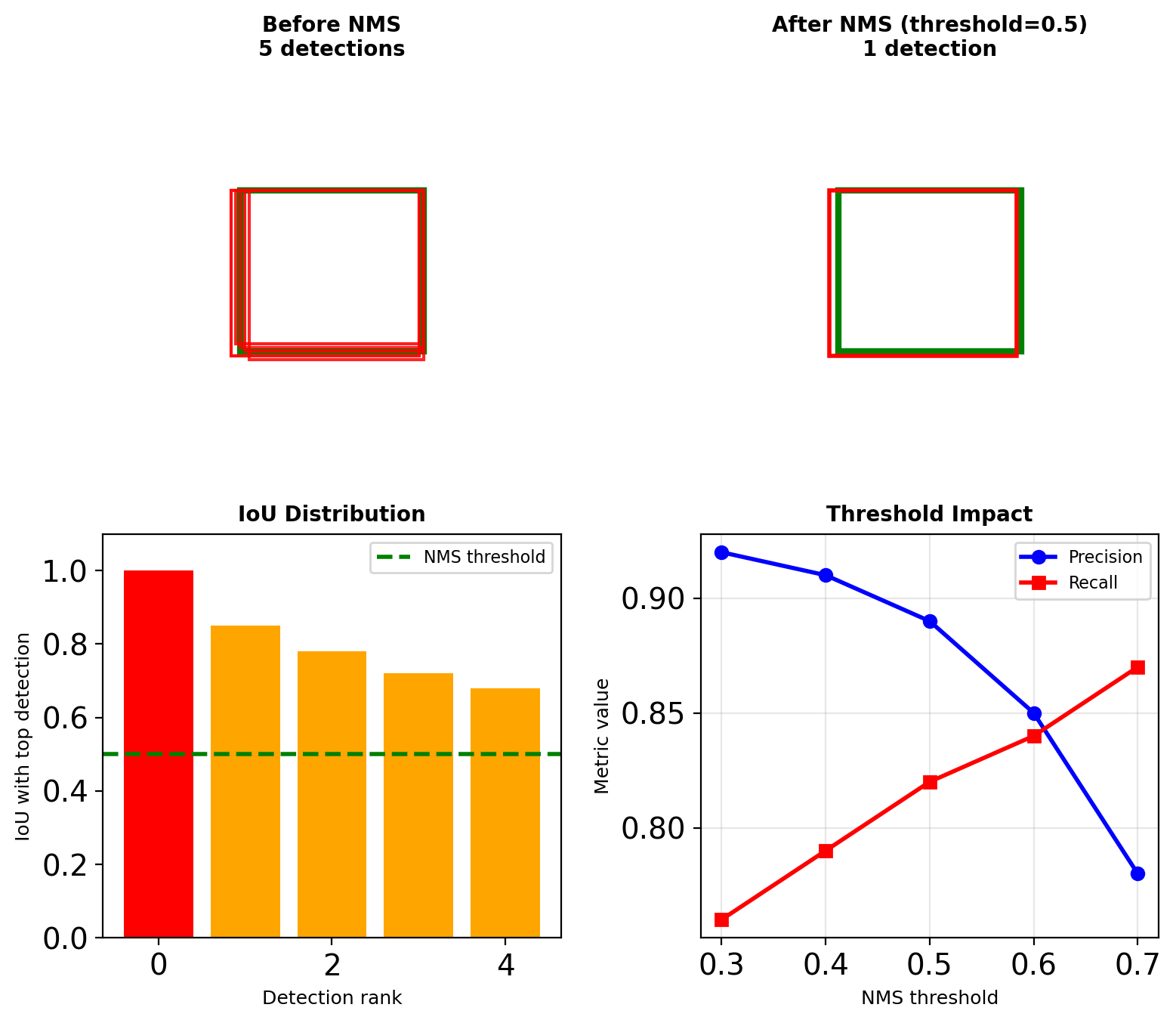
Computational cost: O(N²) for N detections per class
Modern variants: Soft-NMS, Adaptive-NMS, Learned-NMS
Architecture Comparison
Feature Pyramid Networks (FPN) - 2017
Enhancement to Faster R-CNN (Lin et al., CVPR 2017)
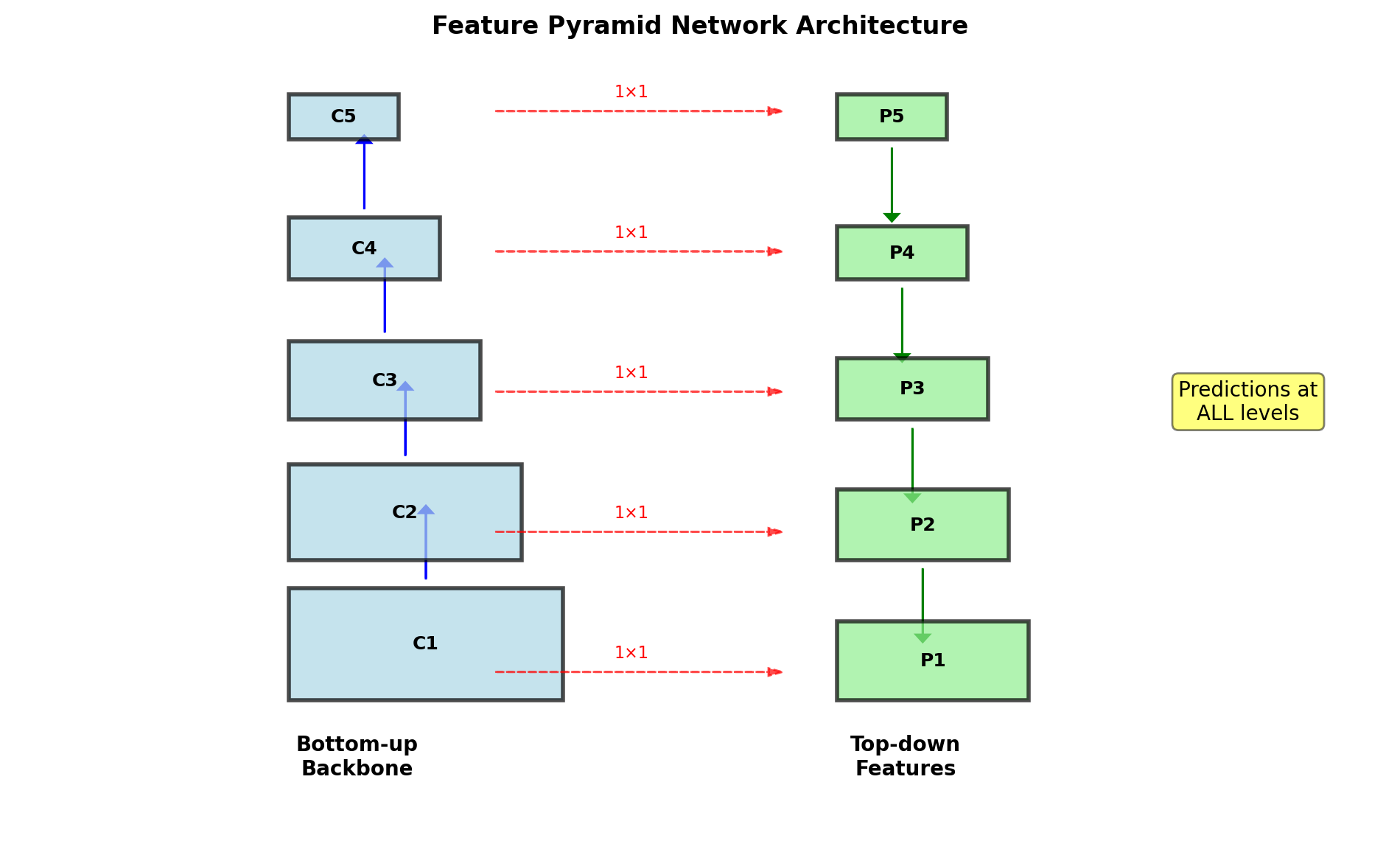
Problem: Faster R-CNN uses single-scale features (C₄ or C₅) → poor for small objects
FPN: Multi-scale feature maps with strong semantics at all scales via top-down pathway
Gain: +2.3 mAP on COCO with minimal speed impact (5-10% slower)
FPN Architecture Details
Construction Process
Bottom-up pathway:
- Standard ConvNet (e.g., ResNet)
- {C₁, C₂, C₃, C₄, C₅} with strides {4, 8, 16, 32, 64}
Top-down pathway:
- Start from C₅ → P₅ (1×1 conv)
- Upsample P₅ by 2×
- Add with C₄ (after 1×1 conv) → P₄
- Repeat for P₃, P₂
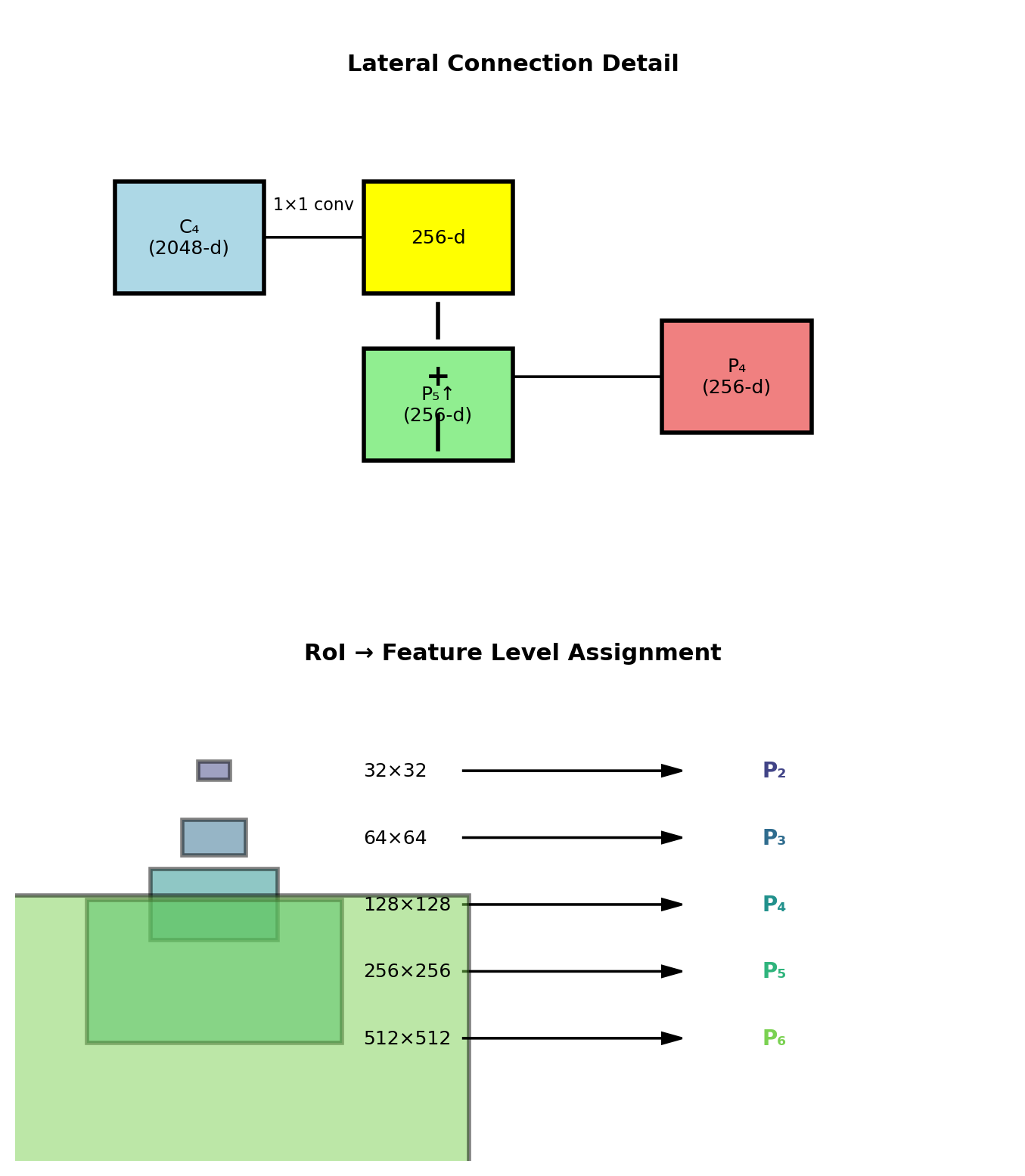
Mathematical formulation: \[P_\ell = \text{Conv}_{1 \times 1}(C_\ell) + \text{Upsample}(P_{\ell+1})\]
Feature dimension: All P layers → 256 channels
Multi-Scale RoI Pooling
- Small objects → fine features (P₂)
- Large objects → coarse features (P₅)
- Assignment by: \(k = \lfloor k_0 + \log_2(\sqrt{wh}/224) \rfloor\)
Performance Evolution
Modern Improvements
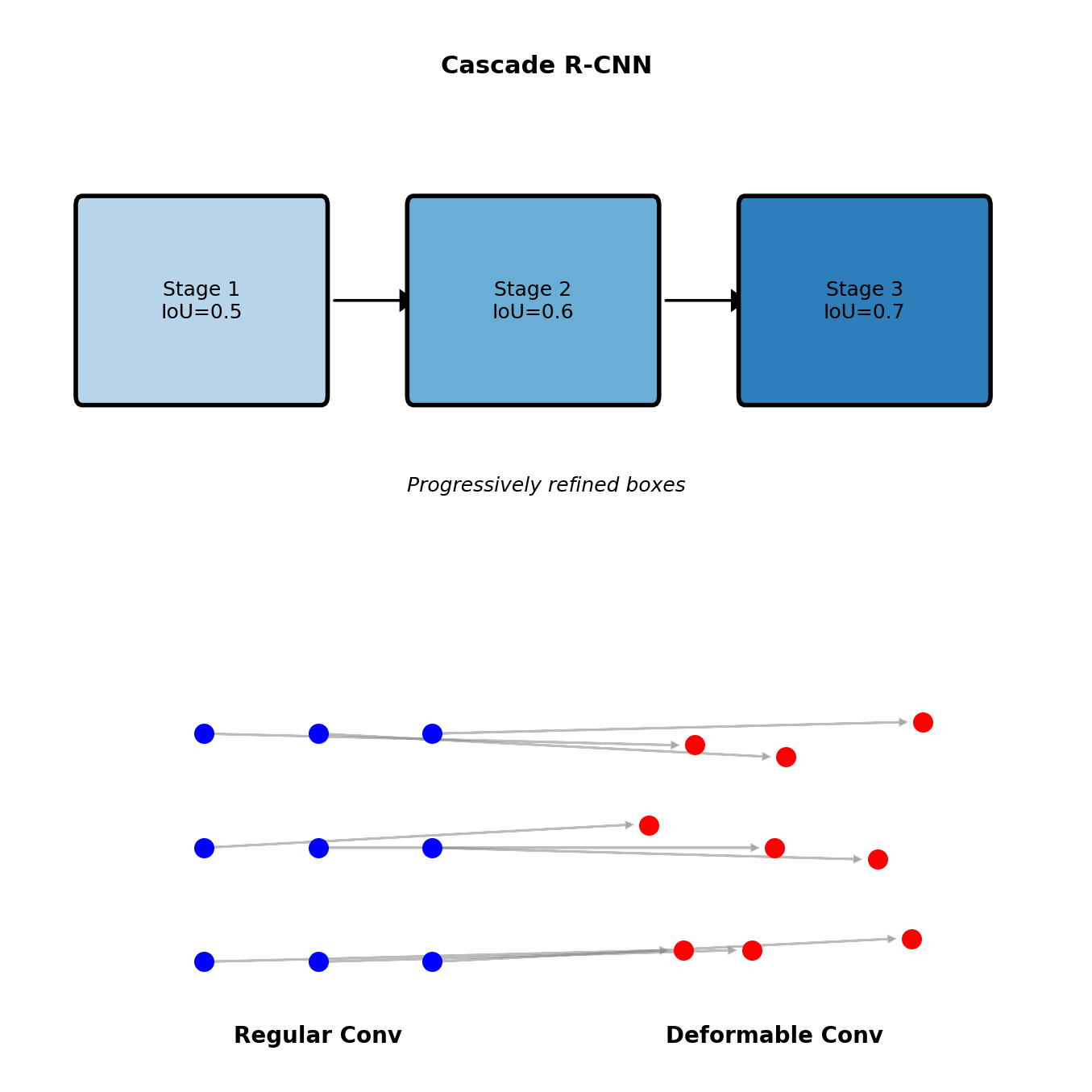
Cascade R-CNN
Progressive refinement with increasing IoU thresholds:
- Stage 1: IoU = 0.5
- Stage 2: IoU = 0.6
- Stage 3: IoU = 0.7
Each stage specialized for its threshold
Deformable Convolutions
Learnable sampling offsets: \[y(p) = \sum_{k=1}^K w_k \cdot x(p + p_k + \Delta p_k)\]
Adaptive receptive fields for objects
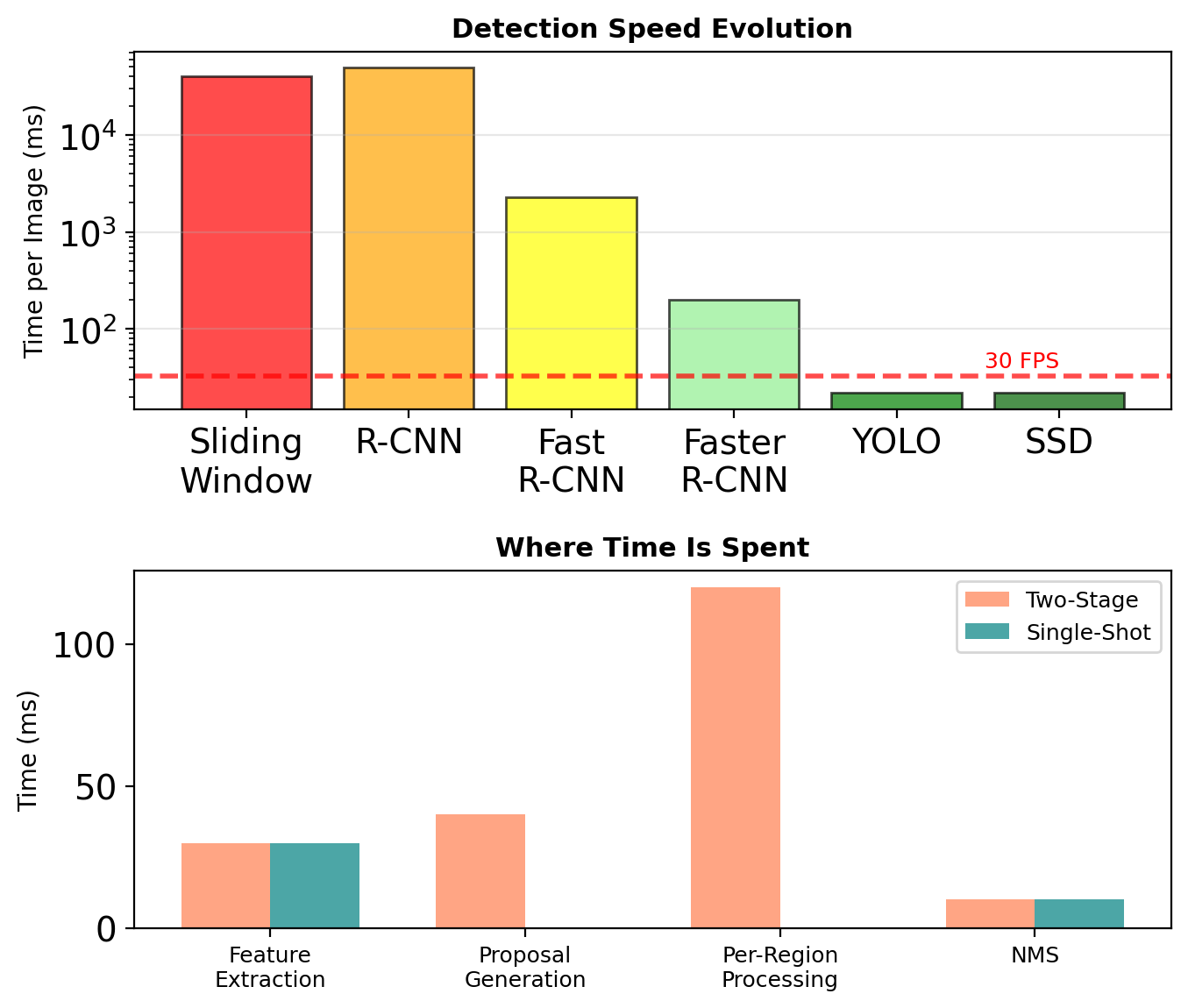
Region-based methods continue to achieve state-of-the-art accuracy on detection benchmarks
Region Detection has a Speed Problem
Two-Stage Bottleneck
Faster R-CNN (2015): ~5 FPS on GPU
- 200ms per image
- ~100ms for RPN
- ~100ms for R-CNN head
Real-time requirement: 30+ FPS (33ms)
Per-Region Processing Cost
For 300 proposals:
- 300 × RoI Align operations
- 300 × classification heads
- 300 × box regression heads
Eliminating region-wise computation through unified detection.
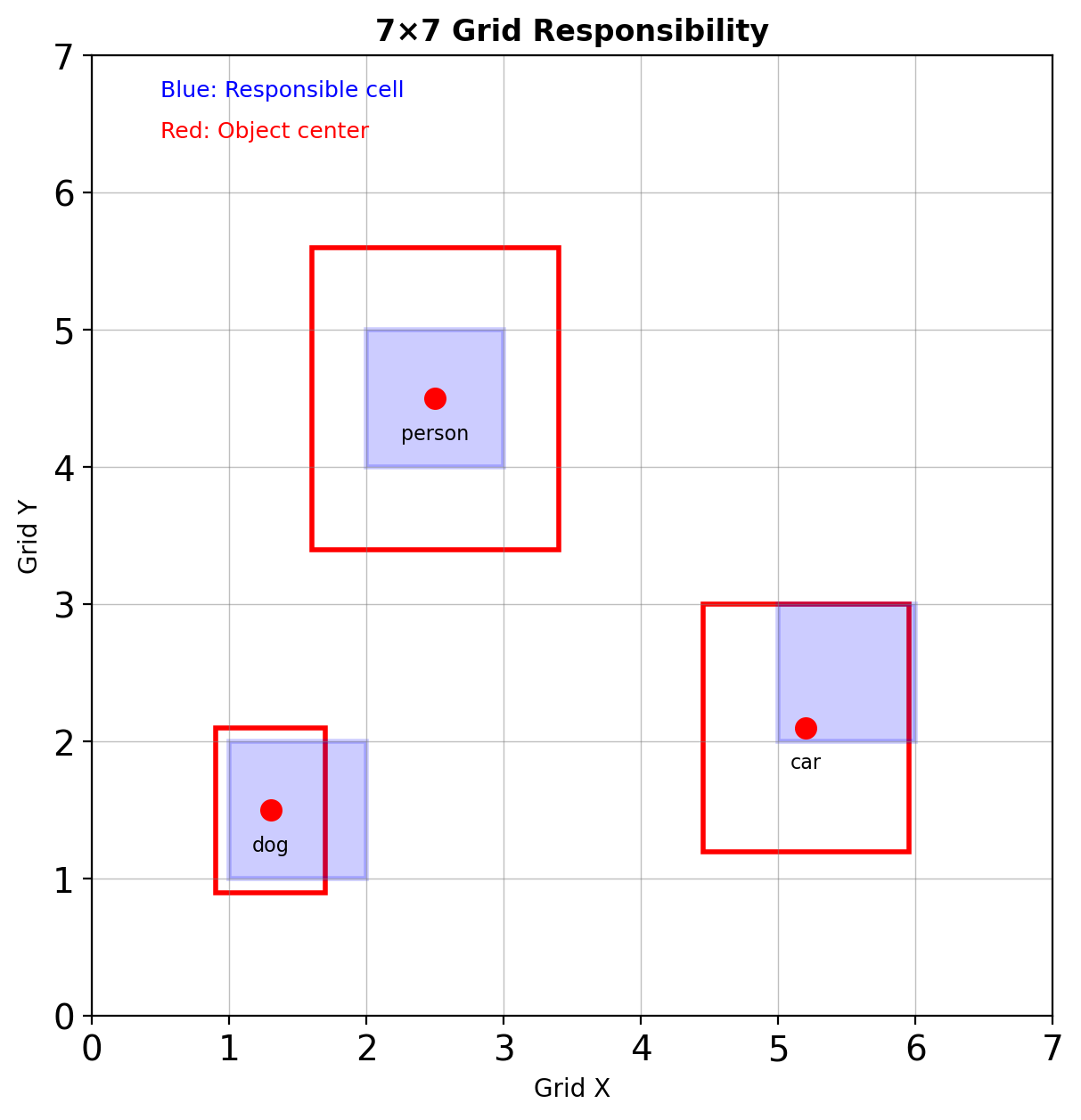
YOLO: Reformulated Detection
Grid-Based Responsibility
Divide image into \(S \times S\) grid (typically \(7 \times 7\))
Each grid cell:
- Predicts \(B\) bounding boxes
- Predicts \(C\) class probabilities
- Responsible if object center falls within
Unified Output Tensor
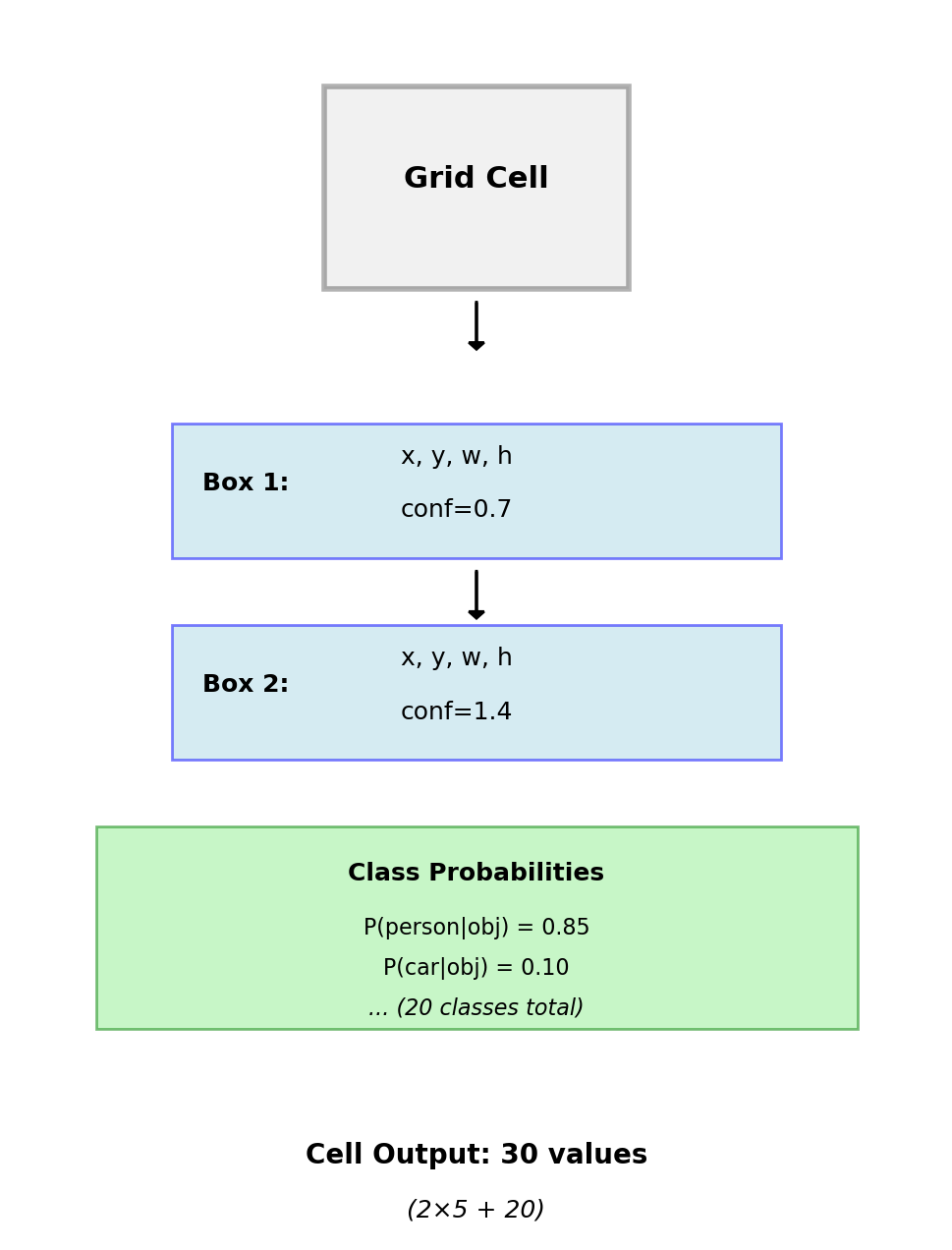
\[\text{Output}: S \times S \times (B \times 5 + C)\]
where each box has:
- \((x, y)\): center relative to grid cell
- \((w, h)\): relative to image
- confidence: \(P(\text{Object}) \times \text{IoU}_{\text{pred}}^{\text{truth}}\)
Single forward pass → all detections
Grid Cell Predictions
Each Cell Outputs
For YOLO v1 with \(B=2\) boxes, \(C=20\) classes:
Bounding boxes (per box):
- \((x, y)\): offset within cell \(\in [0, 1]\)
- \((w, h)\): fraction of image \(\in [0, 1]\)
- Confidence: \(P(\text{Object}) \times \text{IoU}\)
Class probabilities (shared per cell):
- \(P(c_i | \text{Object})\) for each class
- Conditional on containing object
Final Detection Score
\[P(c_i | \text{box}_j) = P(c_i | \text{Object}) \times P(\text{Object}) \times \text{IoU}\]
Threshold and apply NMS for final detections
YOLO Loss Function
Multi-Part Loss
\[\mathcal{L} = \mathcal{L}_{\text{coord}} + \mathcal{L}_{\text{conf}} + \mathcal{L}_{\text{class}}\]
Localization loss (only if object present): \[\lambda_{\text{coord}} \sum_{i}^{S^2} \sum_{j}^{B} \mathbb{1}_{ij}^{\text{obj}} \left[(x_i - \hat{x}_i)^2 + (y_i - \hat{y}_i)^2\right]\]
\[+ \lambda_{\text{coord}} \sum_{i}^{S^2} \sum_{j}^{B} \mathbb{1}_{ij}^{\text{obj}} \left[(\sqrt{w_i} - \sqrt{\hat{w}_i})^2 + (\sqrt{h_i} - \sqrt{\hat{h}_i})^2\right]\]
Confidence loss: \[\sum_{i}^{S^2} \sum_{j}^{B} \mathbb{1}_{ij}^{\text{obj}} (C_i - \hat{C}_i)^2 + \lambda_{\text{noobj}} \sum_{i}^{S^2} \sum_{j}^{B} \mathbb{1}_{ij}^{\text{noobj}} (C_i - \hat{C}_i)^2\]
Classification loss: \[\sum_{i}^{S^2} \mathbb{1}_i^{\text{obj}} \sum_{c \in \text{classes}} (p_i(c) - \hat{p}_i(c))^2\]
Loss Design Choices
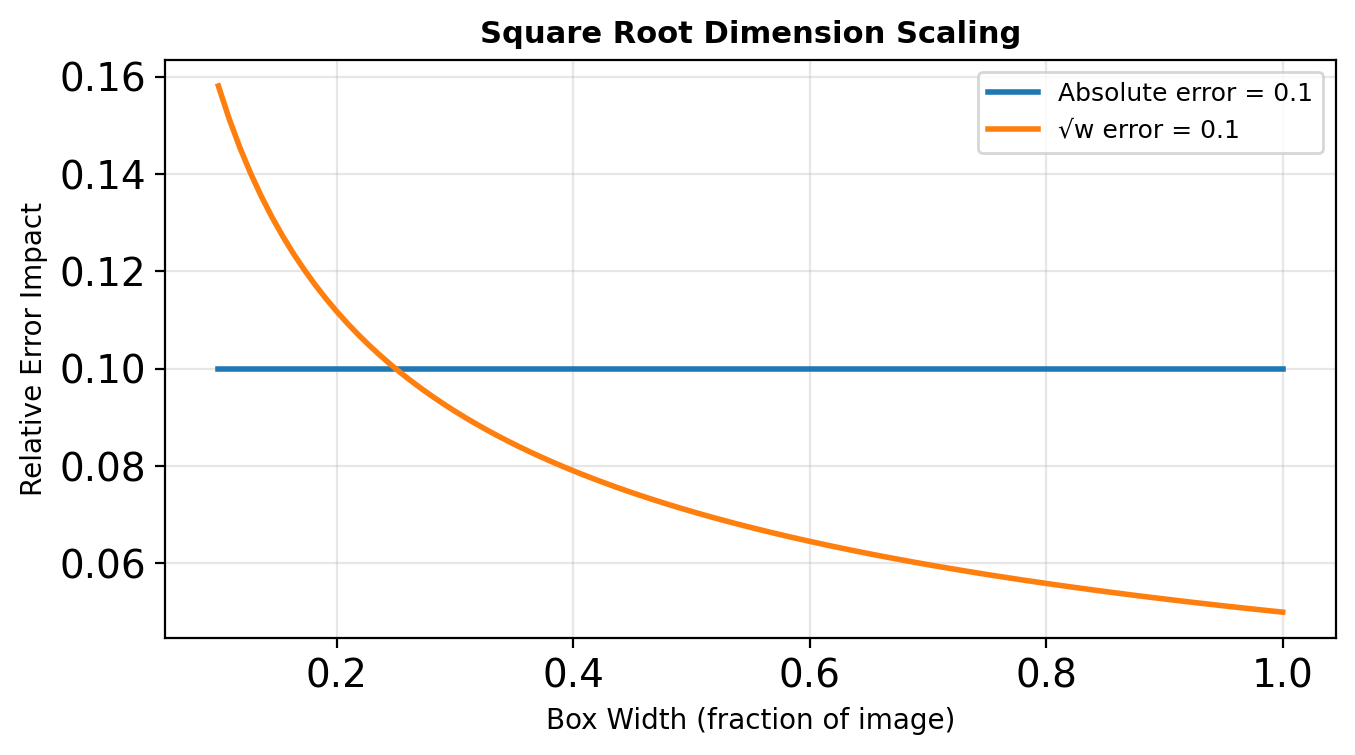
Square root for width/height:
- Small boxes: small absolute errors matter
- Large boxes: can tolerate larger absolute errors
- Square root reduces this imbalance
Loss weights:
- \(\lambda_{\text{coord}} = 5\): emphasize localization
- \(\lambda_{\text{noobj}} = 0.5\): down-weight background
Problems with squared error:
- Treats localization as regression
- Doesn’t align with evaluation metric (IoU)
- Classification should use softmax
YOLO Architecture
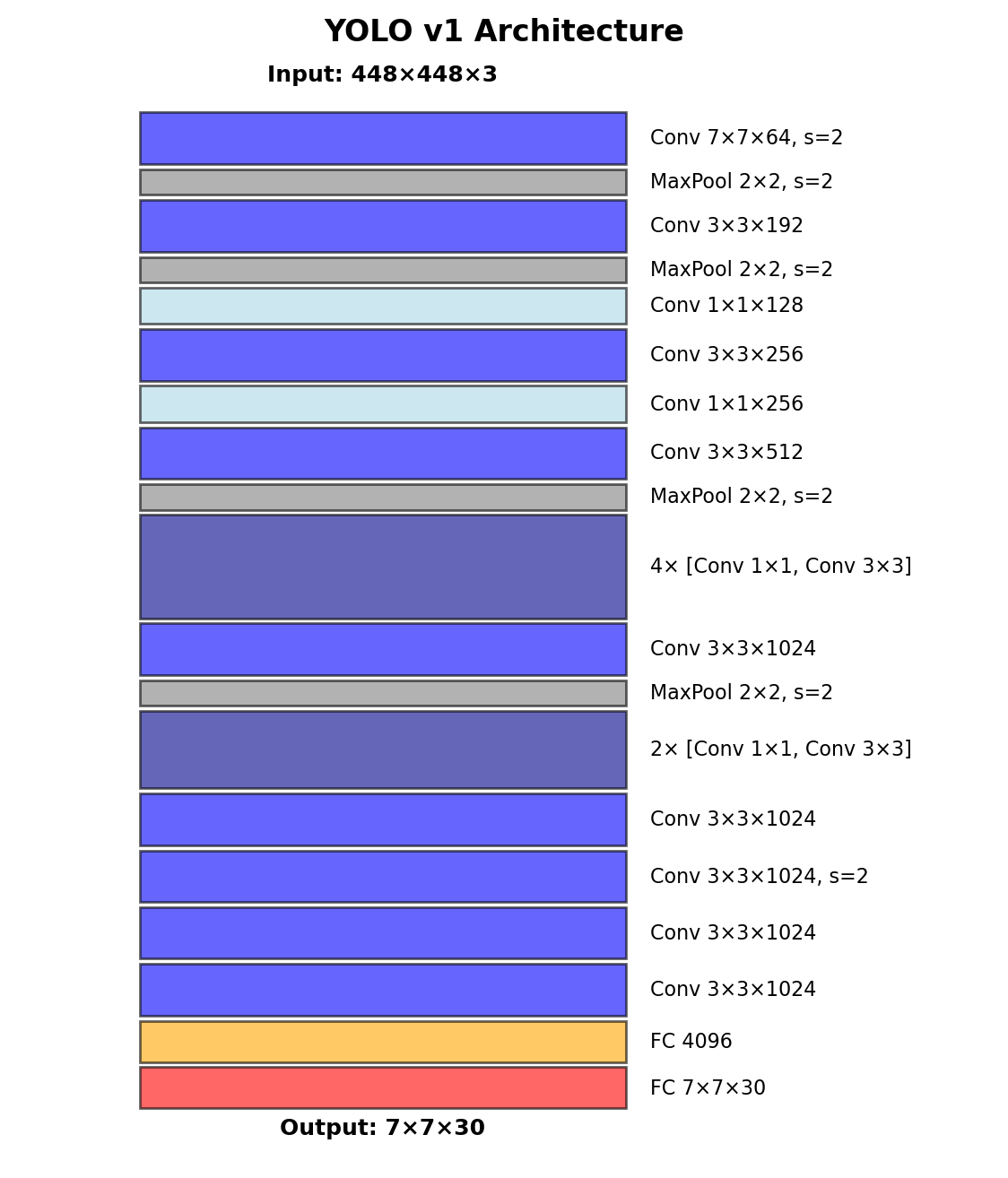
Network Design
24 convolutional layers + 2 fully connected
Inspired by GoogLeNet (but simpler):
- No inception modules
- 1×1 reduction layers alternating with 3×3
Training Strategy
Pretrain on ImageNet (224×224)
- First 20 conv layers
- Achieve 88% top-5 accuracy
Detection fine-tuning (448×448)
- Add 4 conv + 2 FC layers
- Random initialization
- Higher resolution for fine details
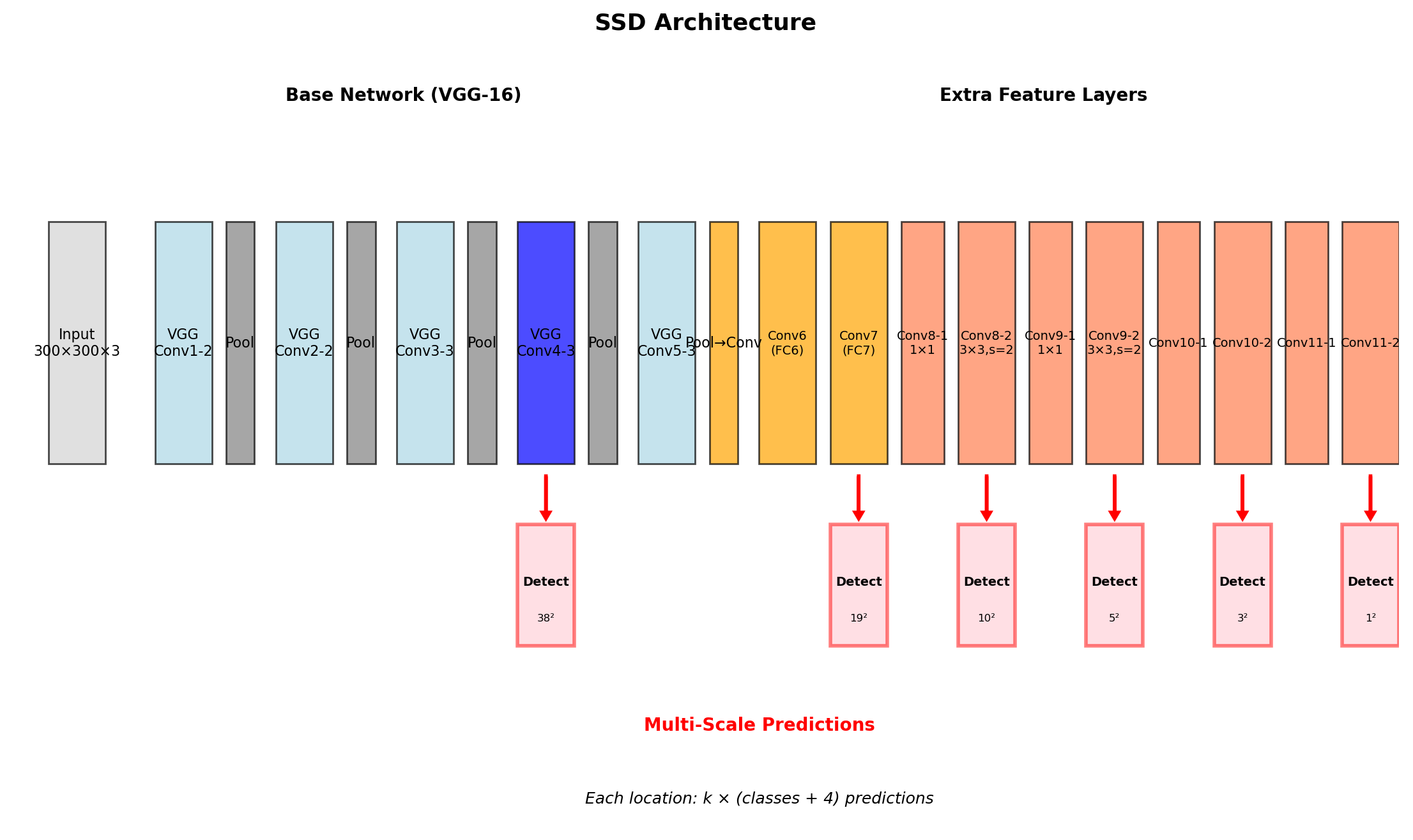
SSD: Multi-Scale Predictions
YOLO’s Scale Problem
Single 7×7 feature map:
- Poor for small objects
- Coarse localization
- Lost fine-grained features
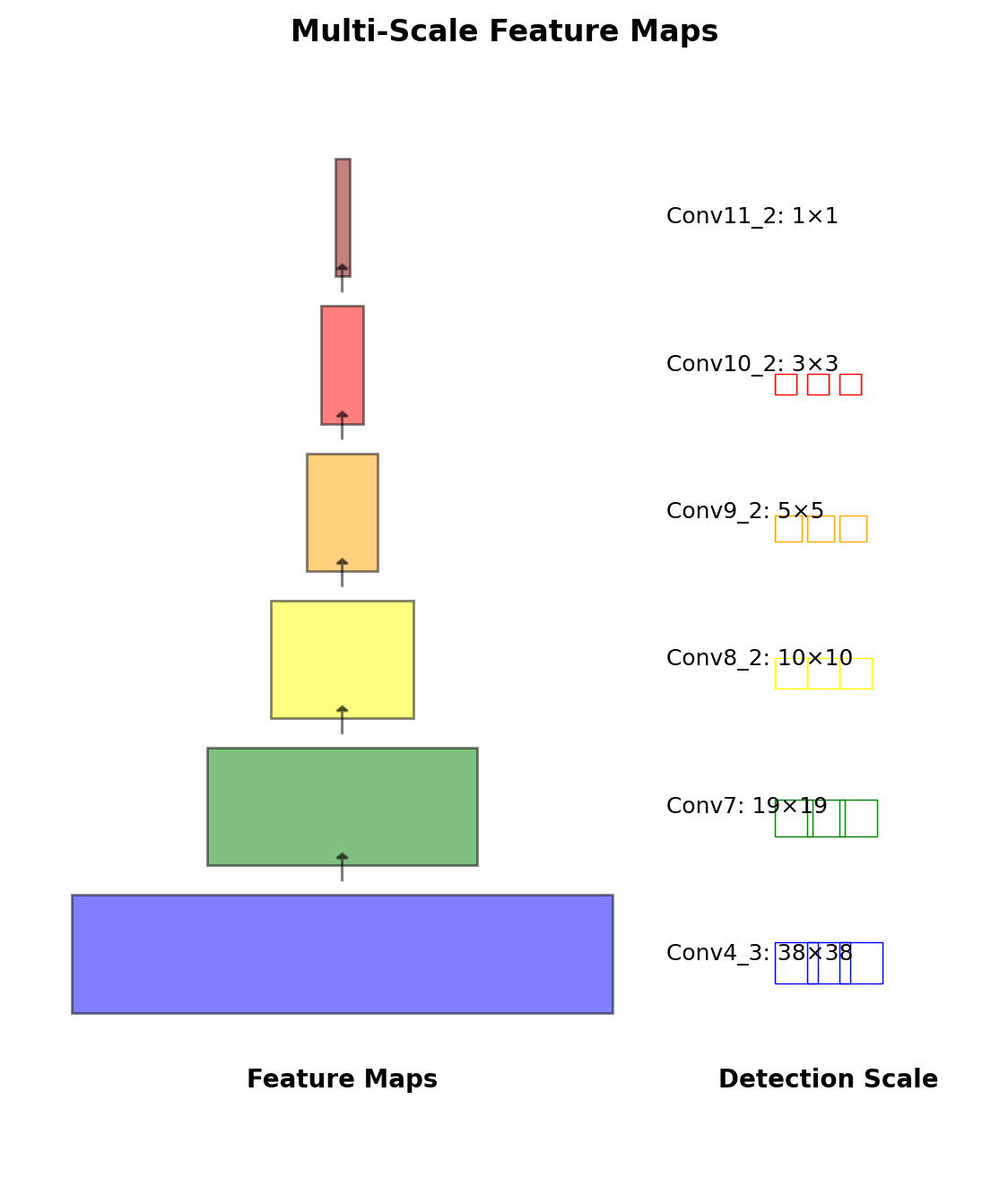
SSD Solution
Predictions from multiple feature maps:
- Conv4_3: 38×38 (small objects)
- Conv7: 19×19
- Conv8_2: 10×10
- Conv9_2: 5×5
- Conv10_2: 3×3
- Conv11_2: 1×1 (large objects)
Each location: multiple default boxes with different scales/ratios
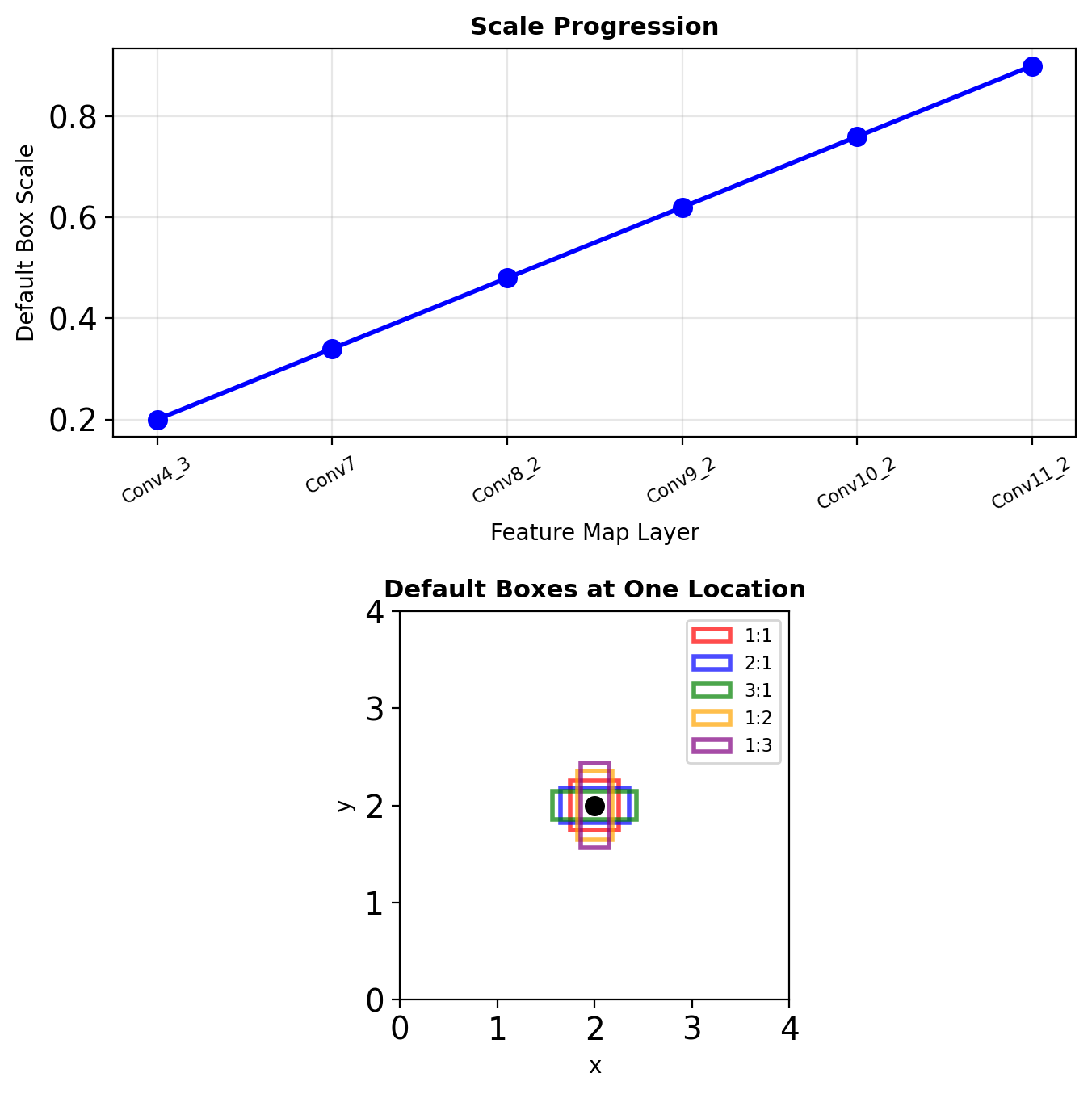
Default Boxes (Anchors)
Scale Calculation
For \(m\) prediction layers, scale at layer \(k\): \[s_k = s_{\min} + \frac{s_{\max} - s_{\min}}{m - 1}(k - 1)\]
where \(s_{\min} = 0.2\), \(s_{\max} = 0.9\)
Aspect Ratios
For ratios \(a_r \in \{1, 2, 3, 1/2, 1/3\}\):
- Width: \(w_k^a = s_k \sqrt{a_r}\)
- Height: \(h_k^a = s_k / \sqrt{a_r}\)
Additional box: \(s'_k = \sqrt{s_k s_{k+1}}\) for \(a_r = 1\)
Total Boxes
38×38×4 + 19×19×6 + 10×10×6 + 5×5×6 + 3×3×4 + 1×1×4 = 8732 default boxes
SSD Architecture
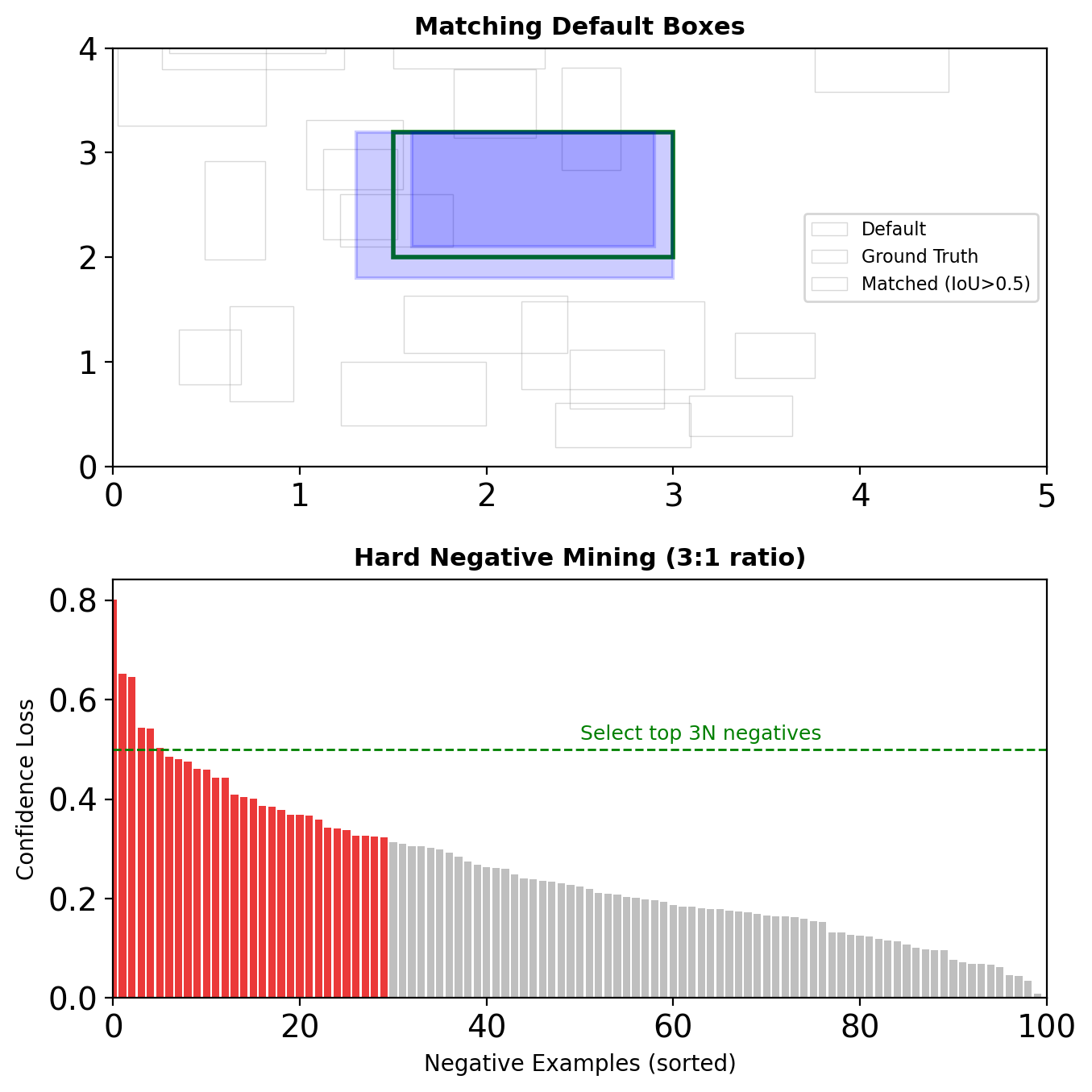
Matching Strategy
Ground Truth Assignment
For each ground truth box:
- Match to default box with highest IoU
- Match any default box with IoU > 0.5
Hard Negative Mining
Problem: ~8700 default boxes, <10 positive
Solution:
- Sort negative boxes by confidence loss
- Pick top ones to maintain 3:1 ratio
- Ensures loss isn’t dominated by easy negatives
Localization Target
Only computed for positive matches: \[t_x = (g_x - d_x)/d_w, \quad t_y = (g_y - d_y)/d_h\] \[t_w = \log(g_w/d_w), \quad t_h = \log(g_h/d_h)\]
where \(g\) = ground truth, \(d\) = default box
SSD Loss Function
Combined Objective
\[L(x, c, l, g) = \frac{1}{N}(L_{\text{conf}}(x, c) + \alpha L_{\text{loc}}(x, l, g))\]
where \(N\) = number of matched default boxes
Localization Loss
Smooth L1 between predicted (\(l\)) and target (\(g\)): \[L_{\text{loc}} = \sum_{i \in \text{Pos}} \sum_{m \in \{x,y,w,h\}} \text{smooth}_{L1}(l_i^m - g_i^m)\]
Confidence Loss
Softmax loss over classes: \[L_{\text{conf}} = -\sum_{i \in \text{Pos}} x_{ij}^p \log(\hat{c}_i^p) - \sum_{i \in \text{Neg}} \log(\hat{c}_i^0)\]
where \(\hat{c}_i^0\) is background class probability
\(\alpha = 1\) in practice (equal weighting)
RetinaNet: The Class Imbalance Problem
Extreme Imbalance
Dense detectors evaluate ~100k locations:
- <100 are positive
- 99,900+ are negative (easy background)
Problems with Standard Loss
Cross-entropy for easy negatives:
- Small individual loss
- Overwhelming collective gradient
- Prevents learning rare classes
Example: \(p = 0.9\) for easy negative
- CE loss = \(-\log(0.9) = 0.1\)
- 10,000 easy negatives = 1,000 total loss
- Drowns out hard examples
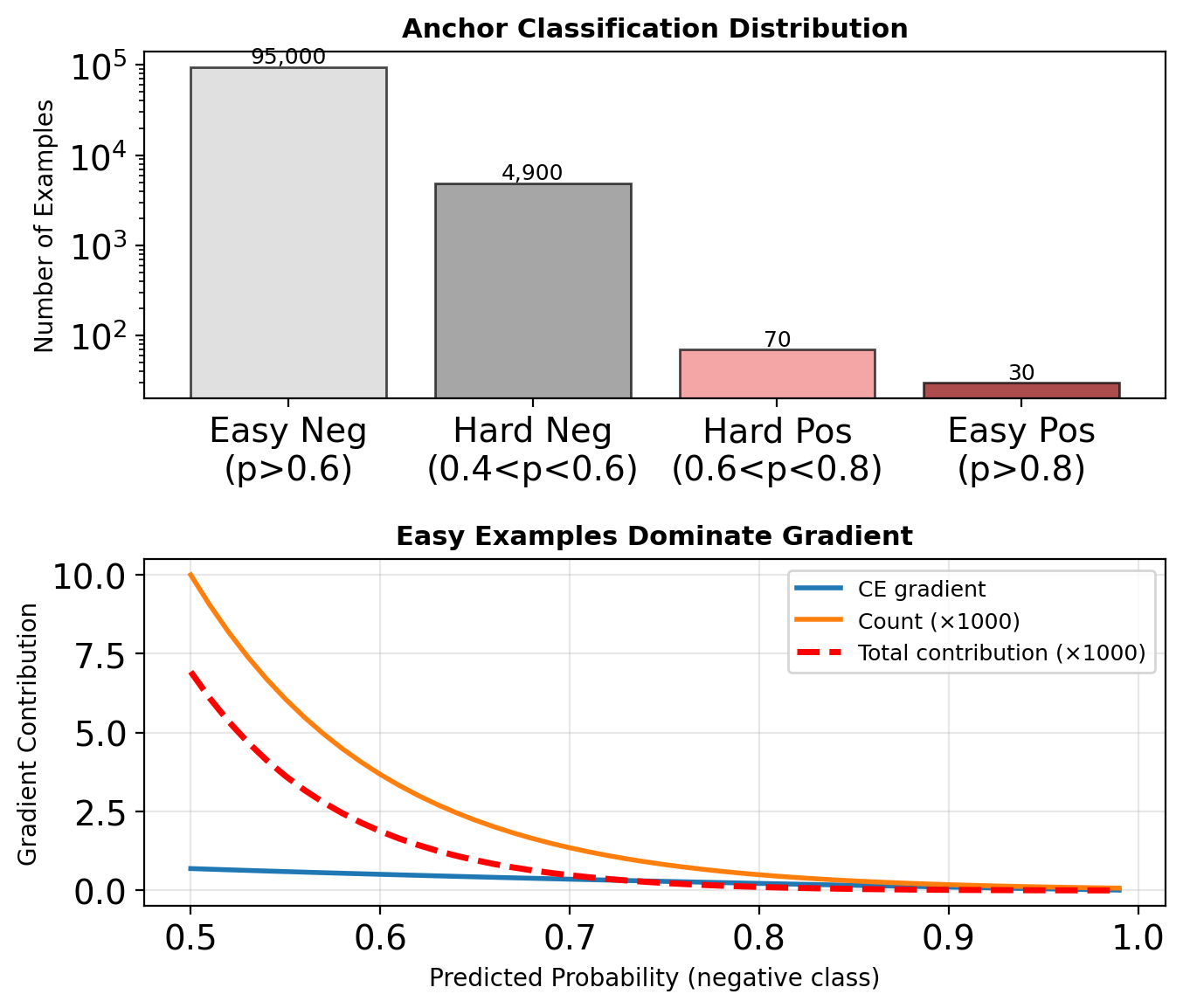
Focal Loss
Definition
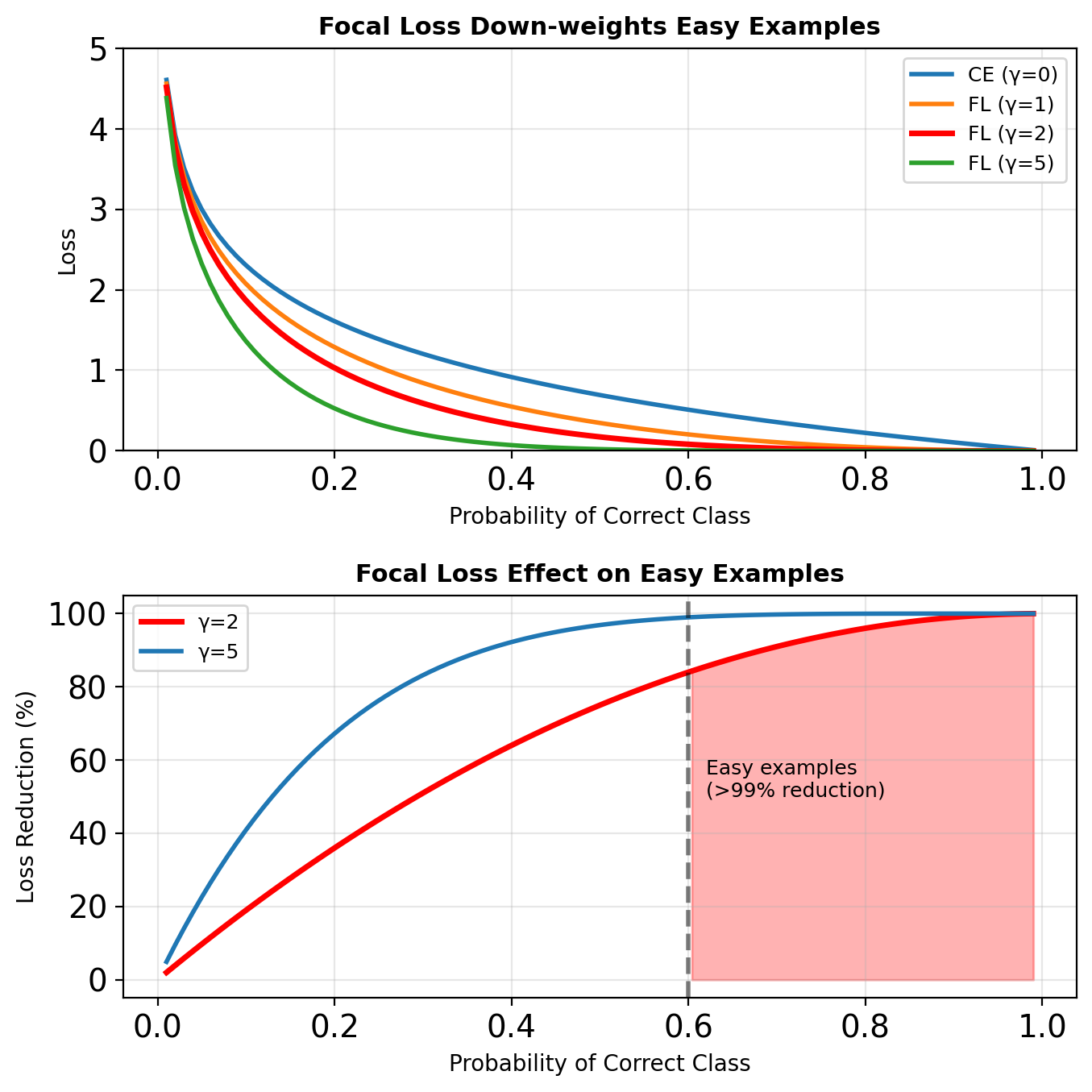
Standard Cross-Entropy: \[\text{CE}(p_t) = -\log(p_t)\]
Focal Loss: \[\text{FL}(p_t) = -\alpha_t(1 - p_t)^\gamma \log(p_t)\]
where:
- \(p_t\) = model’s estimated probability for correct class
- \((1 - p_t)^\gamma\) = modulating factor
- \(\gamma\) = focusing parameter (typically 2)
- \(\alpha_t\) = class balance weight
Gradient Analysis
\[\frac{\partial \text{FL}}{\partial p} = -\alpha(1-p_t)^\gamma \left(\gamma p_t \log(p_t) + (1-p_t)\right)\]
As \(p_t \rightarrow 1\): gradient \(\rightarrow 0\) rapidly
Speed vs Accuracy Trade-offs
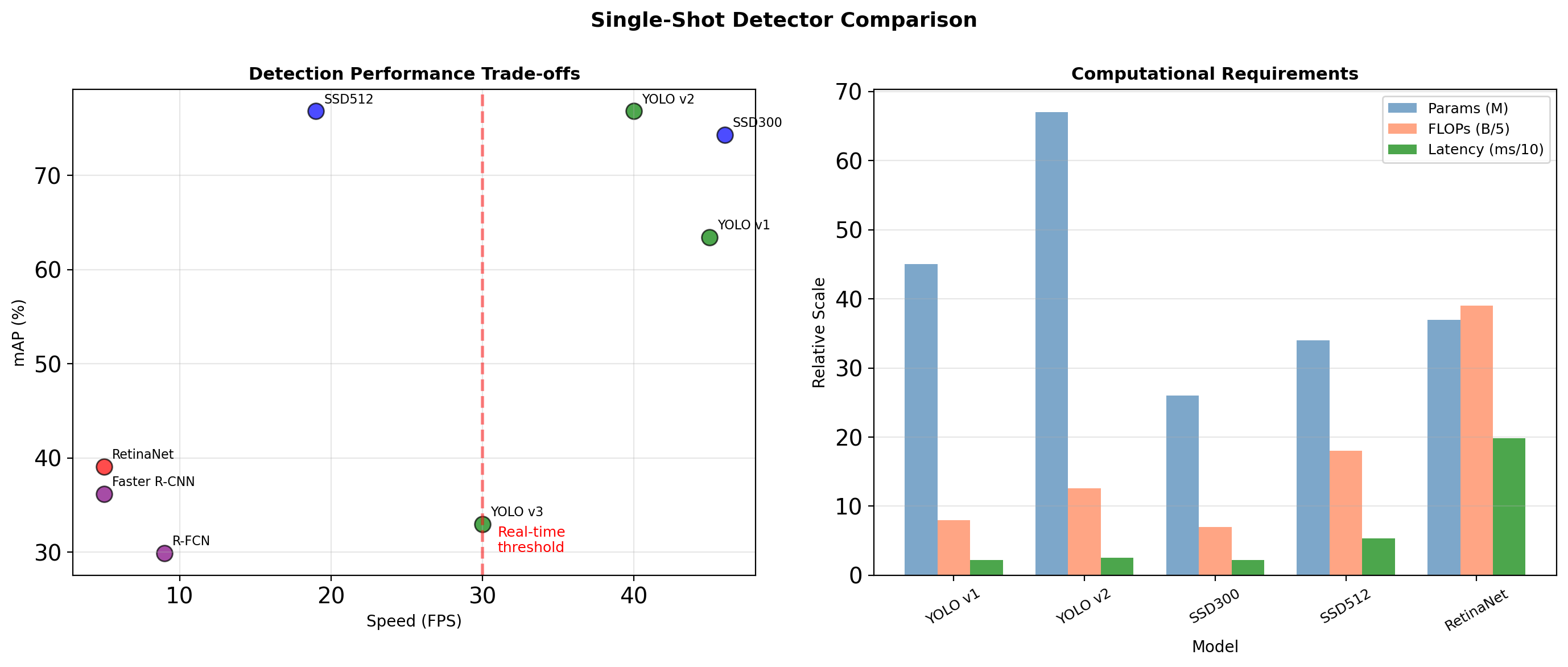
Key insight: FLOPs ≠ Speed. Memory access patterns and parallelization matter.
Anchor-Free Detectors
Motivation
Anchors have hyperparameters:
- Scales, aspect ratios
- Assignment thresholds
- Per-layer configurations
CenterNet: Objects as Points
Predict object centers as keypoints:
- Heatmap for center detection
- Direct regression for size
- No NMS needed (local maxima)
FCOS: Fully Convolutional
For each location \((x, y)\):
- Directly predict \((l, t, r, b)\) to box edges
- Centerness score for quality
- Multi-level prediction with FPN
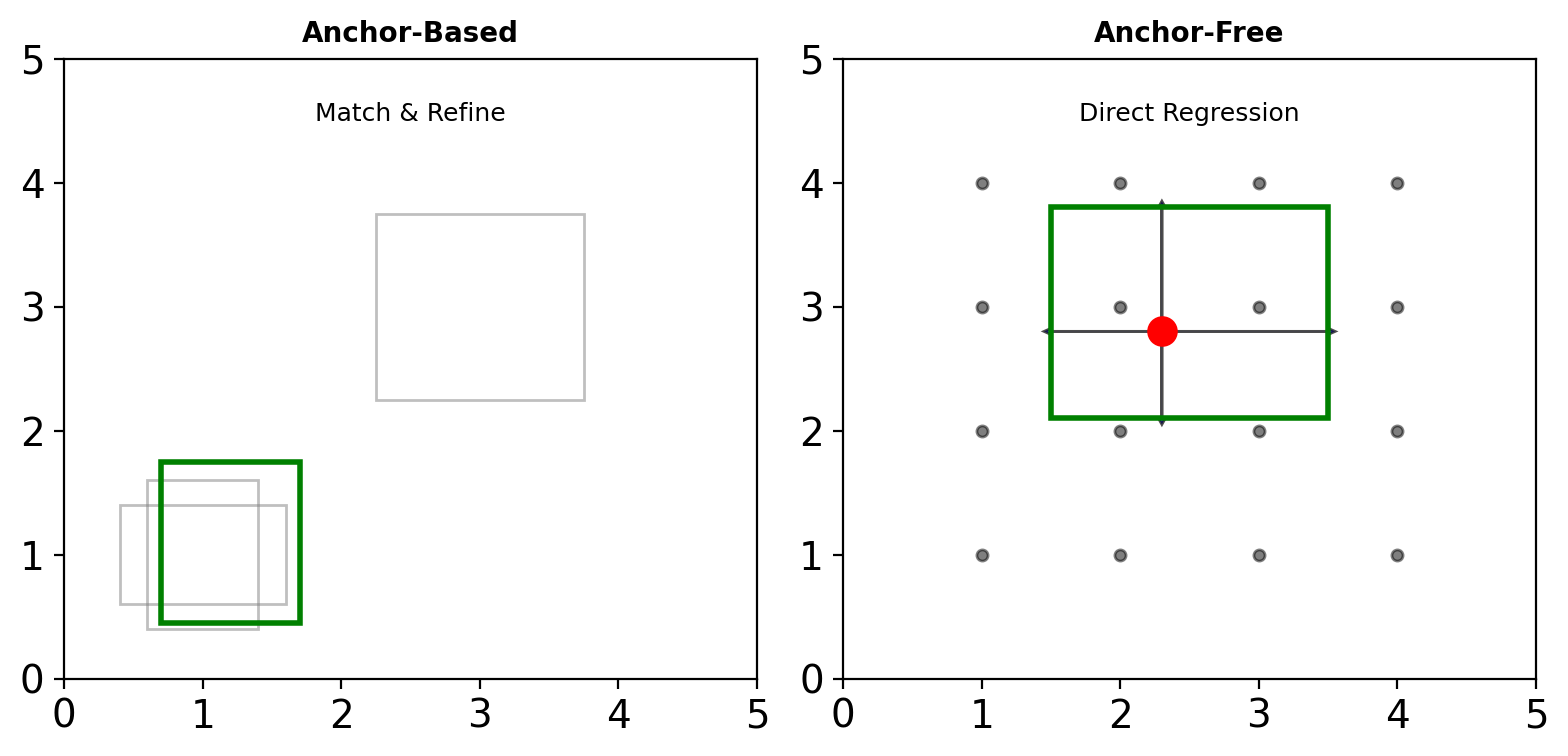
Single-Shot Detection Effectiveness
Dense Predictions
~100k predictions compensate for single pass:
- High recall through coverage
- Redundancy helps precision
- NMS cleans duplicates
Rich Feature Extraction
Modern backbones extract semantic features:
- Pretrained on ImageNet
- Multi-scale feature fusion
- Sufficient for localization
Loss Function Innovation
Better handling of imbalance:
- Focal loss (RetinaNet)
- OHEM (Online Hard Example Mining)
- IoU-based losses for localization
Hardware optimization for single forward pass
Single-shot detectors prioritize efficiency over architectural complexity, achieving real-time performance through dense predictions and sophisticated loss functions.
Dense Prediction Problem
Mathematical Formulation
Input: \(X \in \mathbb{R}^{H \times W \times 3}\)
Semantic Segmentation: \[f: \mathbb{R}^{H \times W \times 3} \rightarrow \{0, 1, ..., C\}^{H' \times W'}\]
Instance Segmentation: \[f: \mathbb{R}^{H \times W \times 3} \rightarrow (\{0, 1\}^{H' \times W'})^N\]
where \(N\) is the number of instances.
The Challenge
- Classification: 1 prediction per image
- Detection: ~100 predictions per image
- Segmentation: \(H \times W\) predictions per image
For 512×512 image: 262,144 predictions

Two Flavors of Segmentation

Semantic: All pixels labeled by class
- Sky is sky, all people are “person”
- No individual identity

Instance: Each object gets unique ID
- Person 1, Person 2, Person 3…
- Detection + pixel-precise masks
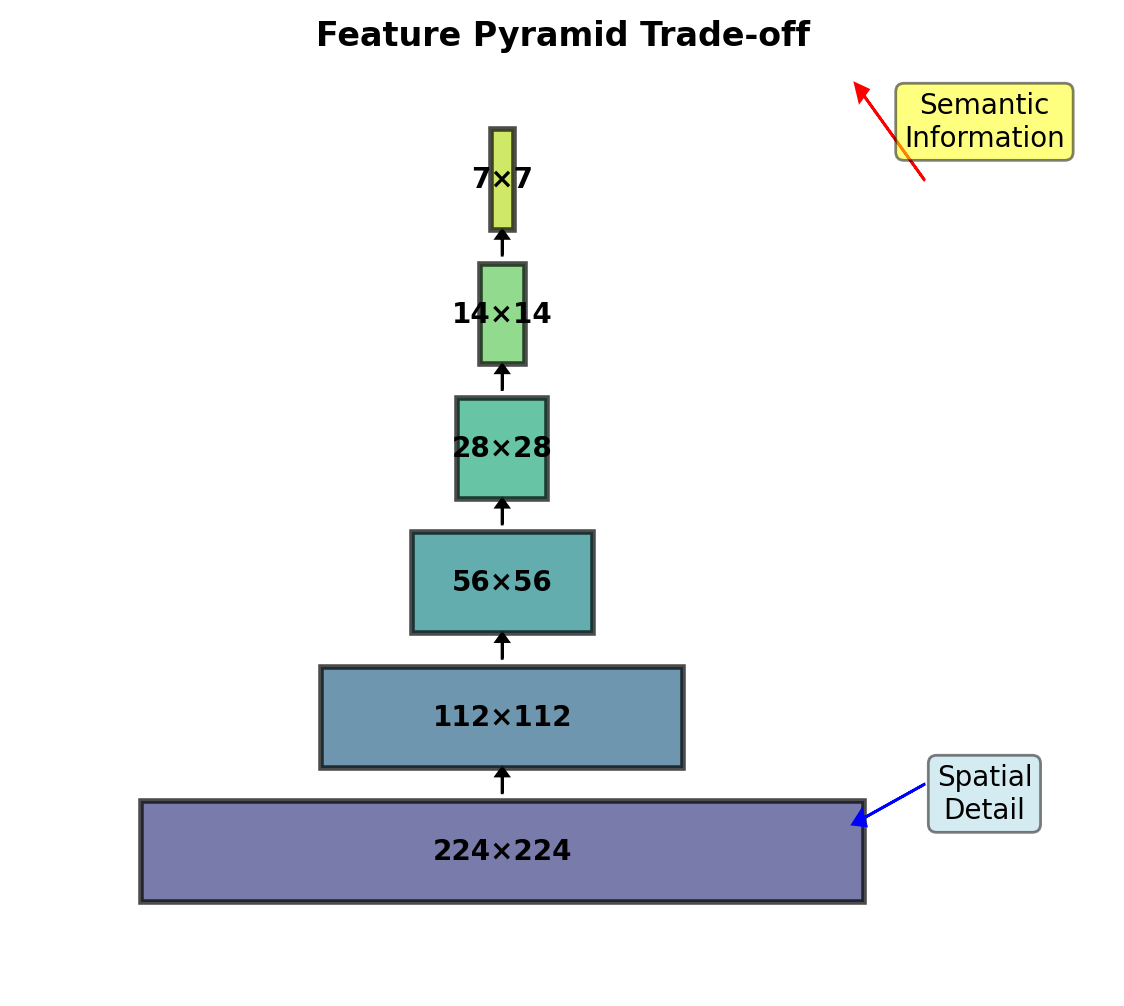
Resolution Preservation Challenge
Progressive Downsampling
Standard CNN (ResNet-50):
- Layer 1: 224×224 → 112×112 (stride 2)
- Layer 2: 112×112 → 56×56 (stride 2)
- Layer 3: 56×56 → 28×28 (stride 2)
- Layer 4: 28×28 → 14×14 (stride 2)
- Layer 5: 14×14 → 7×7 (stride 2)
32× spatial reduction
The Dilemma
High resolution → High memory/computation Low resolution → Lost spatial detail
Need: Semantic understanding + spatial precision
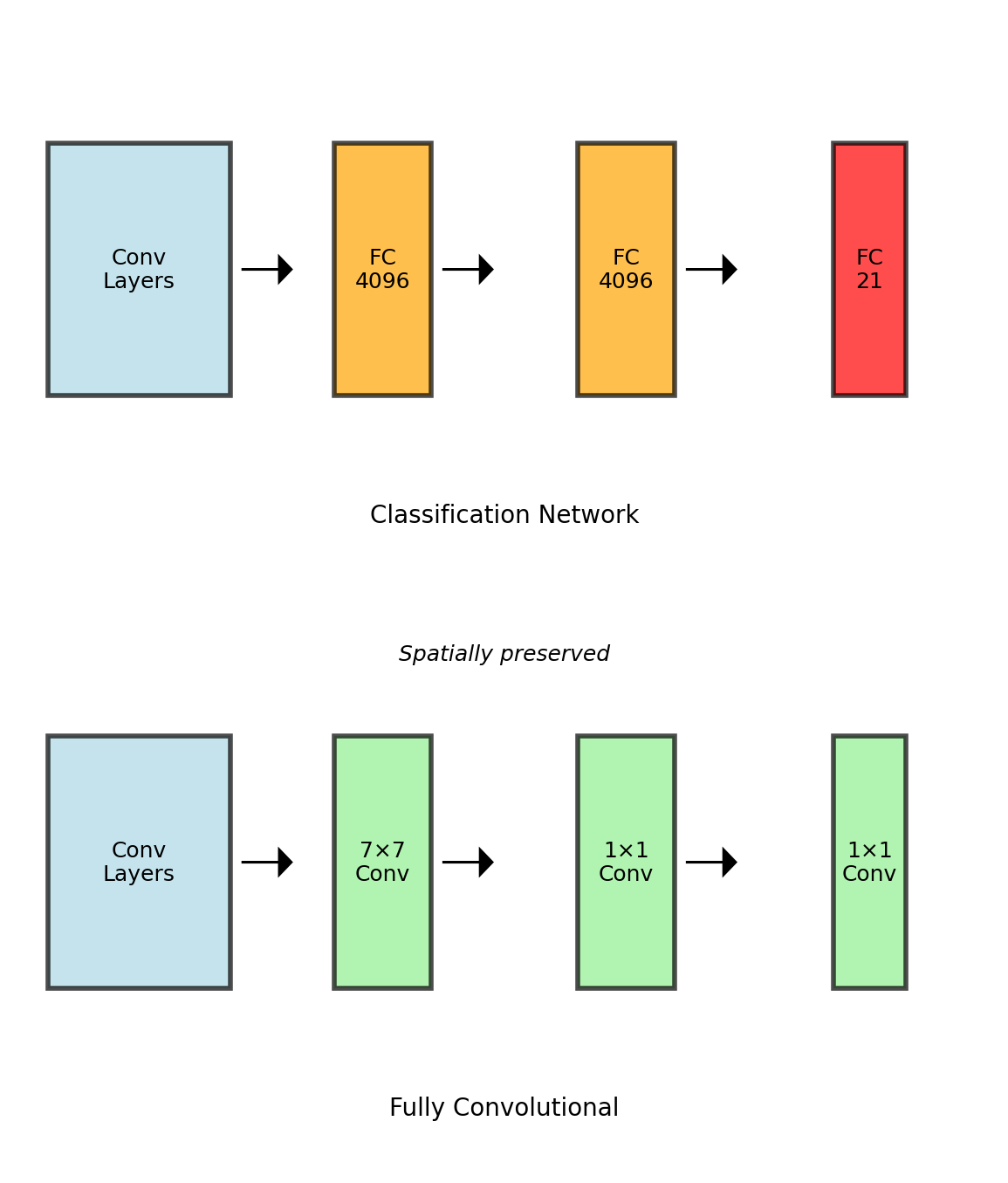
Fully Convolutional Networks
Converting FC to Convolution
FC layer with 4096 neurons on 7×7×512 input:
- Weights: 7×7×512×4096
- Equivalent: 7×7 conv with 4096 filters
Mathematical Equivalence
FC layer: \[y_i = \sum_{j} W_{ij} x_j + b_i\]
As 1×1 convolution after global pool: \[y[0,0,i] = \sum_{h,w,c} W[h,w,c,i] \cdot x[h,w,c] + b[i]\]
Arbitrary Input Sizes
Once fully convolutional:
- 224×224 → 7×7×21 (original)
- 384×384 → 12×12×21 (larger)
- Any H×W → H’×W’×21
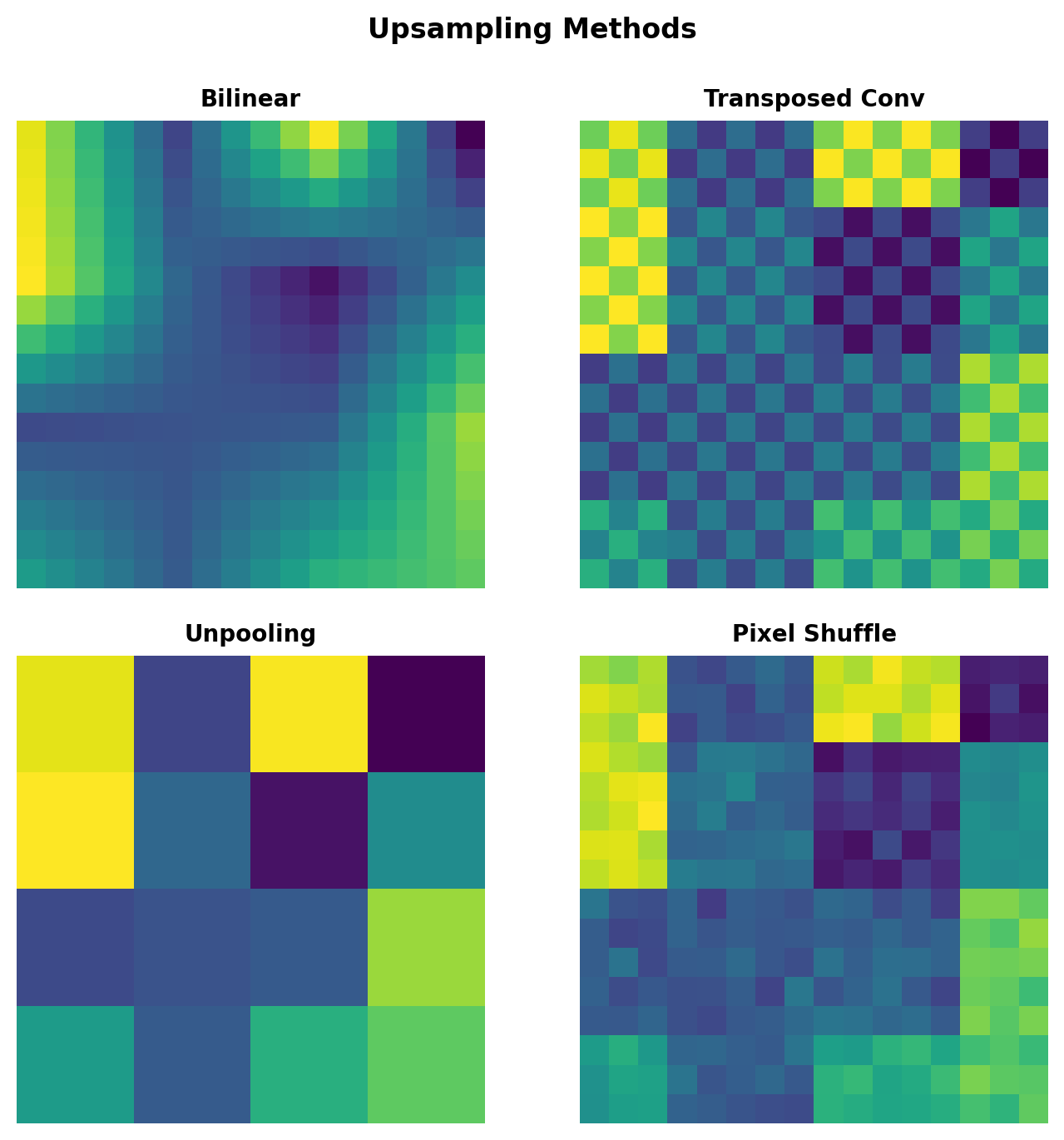
Upsampling Strategies
Bilinear Interpolation
Non-learnable, deterministic: \[y[i,j] = \sum_{m,n} x[\lfloor i/s \rfloor + m, \lfloor j/s \rfloor + n] \cdot W_{mn}\]
where \(W_{mn}\) are bilinear weights based on fractional positions.
Transposed Convolution
Learnable upsampling: \[y[si+m, sj+n] = \sum_{c} h[m,n,c] \cdot x[i,j,c]\]
Equivalent to:
- Insert \((s-1)\) zeros between inputs
- Apply standard convolution
Checkerboard Artifacts
Transposed conv with stride > kernel size causes overlapping patterns
Skip Connections for Detail Recovery
FCN Architecture Variants
FCN-32s: Direct 32× upsampling
- Input → Conv → Pool (5×) → FC → Upsample 32×
- Very coarse output
FCN-16s: Combine pool4 + pool5
- Pool5 predictions → Upsample 2×
- Add pool4 predictions
- Upsample 16× to output
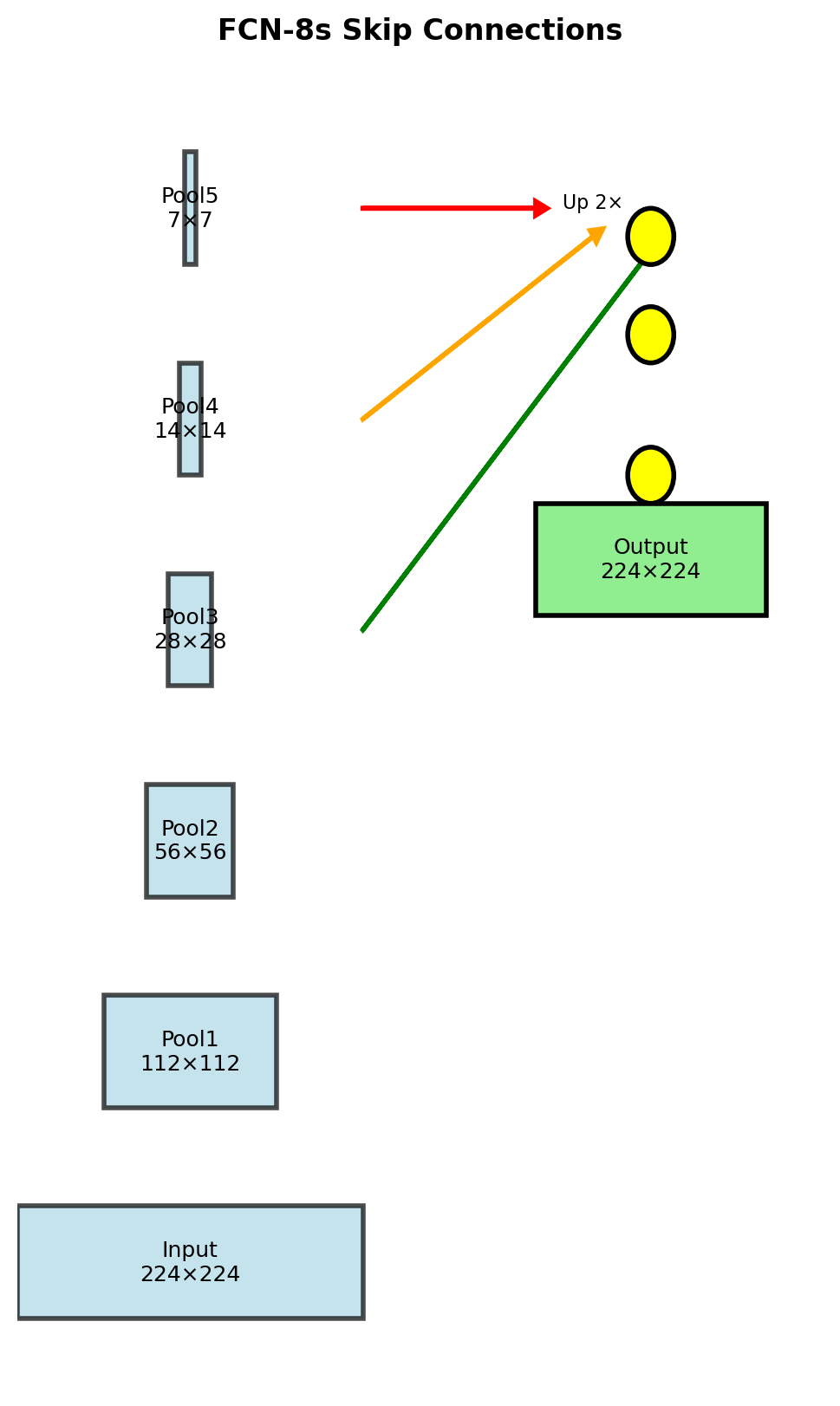
FCN-8s: Combine pool3 + pool4 + pool5
- Pool5 → Up 2× → Add pool4 → Up 2× → Add pool3 → Up 8×
Quantitative Improvements
| Model | Mean IoU | Inference (ms) |
|---|---|---|
| FCN-32s | 59.4 | 80 |
| FCN-16s | 62.4 | 85 |
| FCN-8s | 62.7 | 90 |
Skip connections recover fine details with minimal computational cost
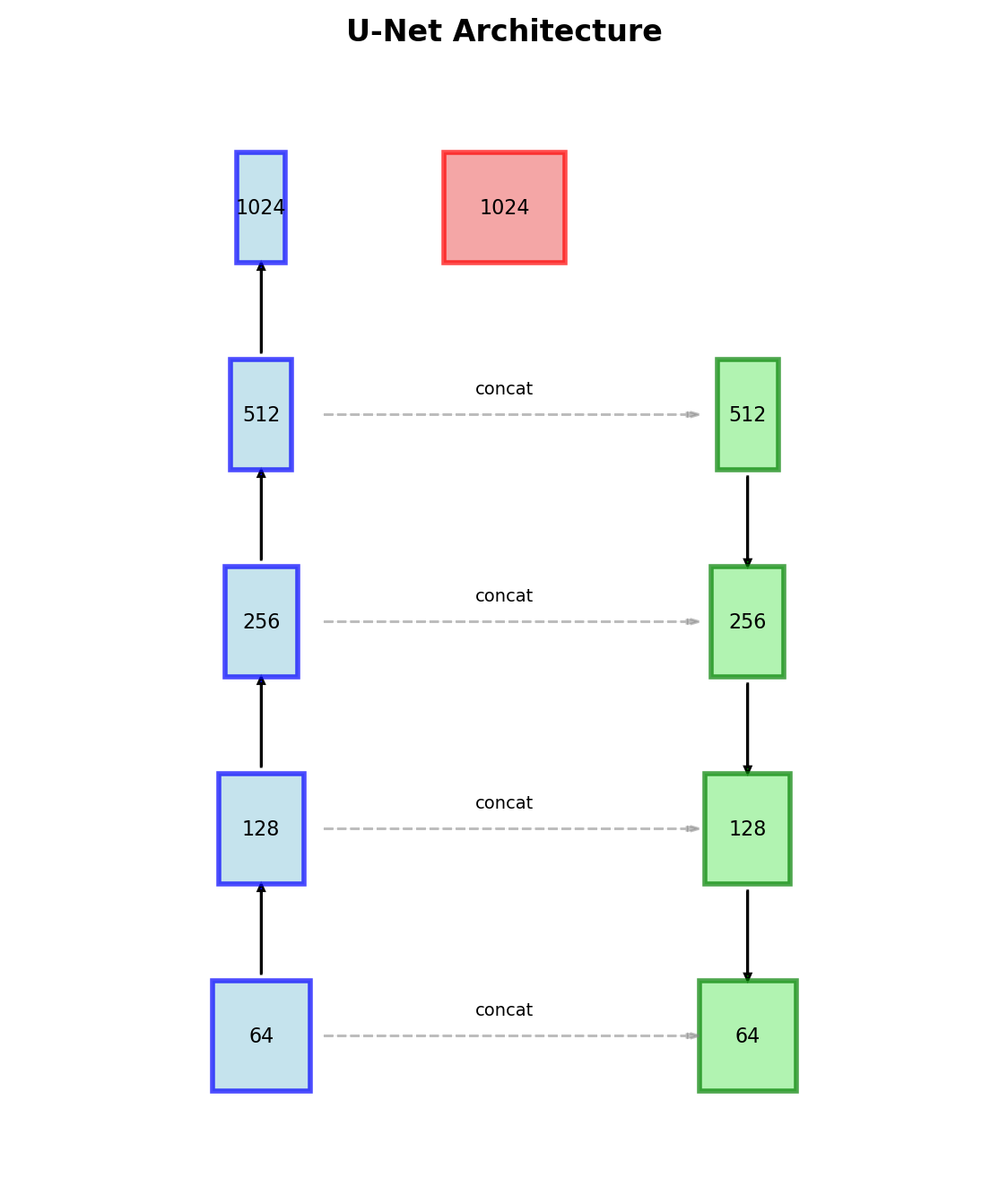
U-Net Architecture
Symmetric Encoder-Decoder
Contracting Path (left):
- Two 3×3 convolutions (unpadded)
- ReLU activation
- 2×2 max pooling (stride 2)
- Double channels at each level
Expanding Path (right):
- 2×2 up-convolution
- Concatenate with cropped encoder features
- Two 3×3 convolutions
- ReLU activation
Concatenation Rationale
Addition (FCN): Features compete Concatenation (U-Net): Network chooses
Total parameters: ~31M (for 64 initial filters)
U-Net Information Flow
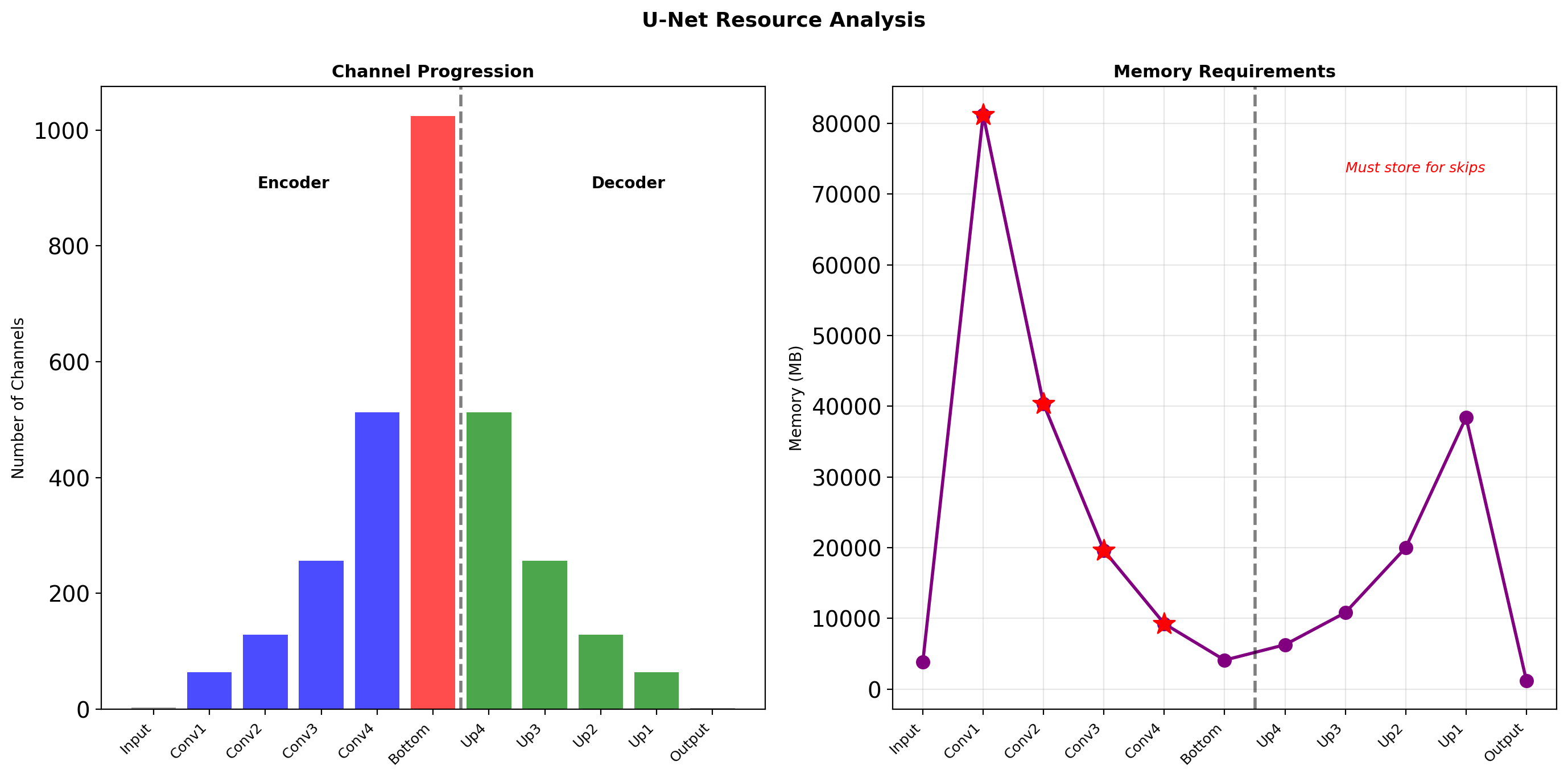
Concatenation doubles channels at each decoder level, increasing expressiveness
DeepLab: Atrous Convolution
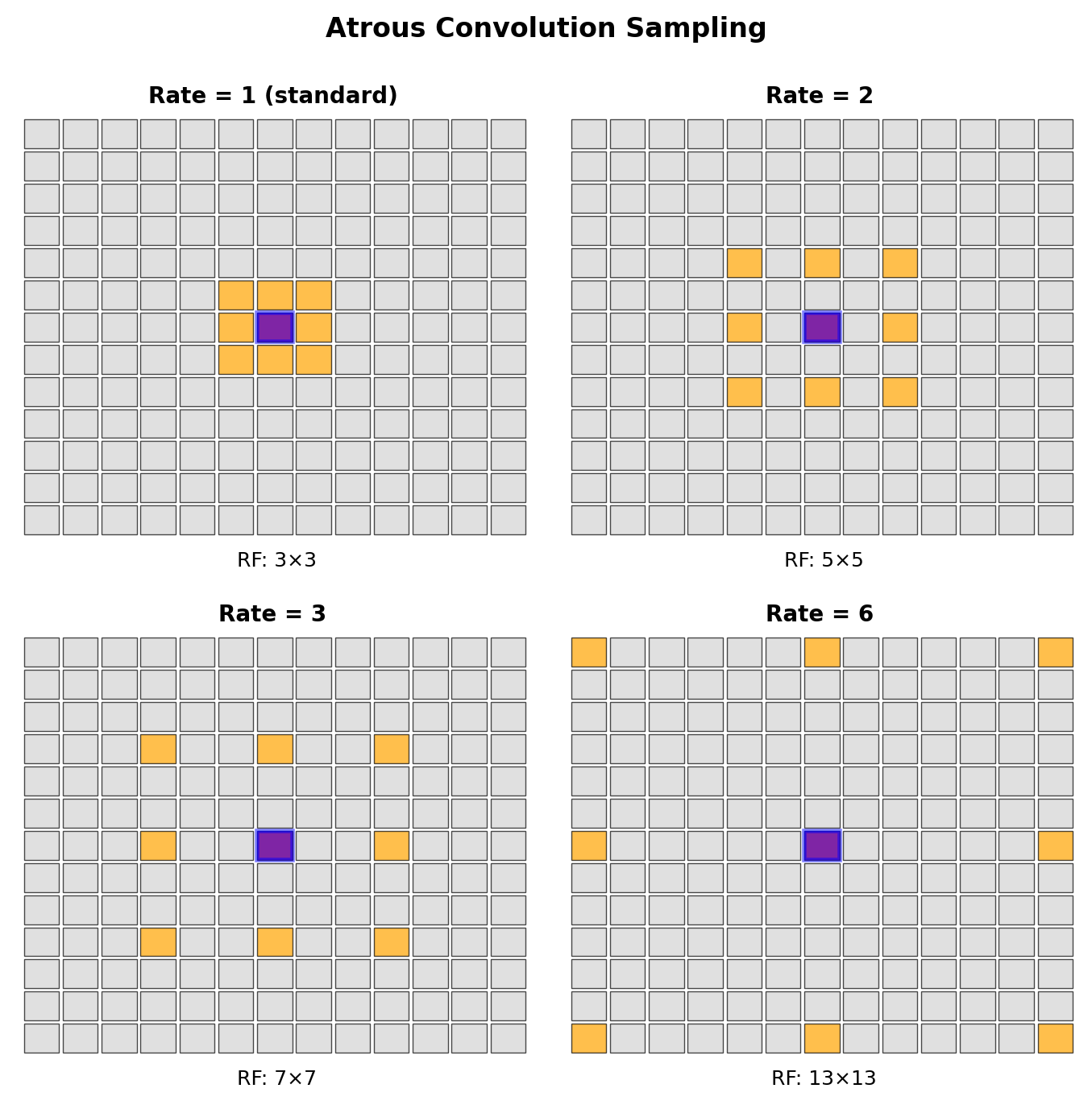
Dilated Convolution
Standard convolution: \[y[i,j] = \sum_{m,n} h[m,n] \cdot x[i+m, j+n]\]
Atrous convolution with rate \(r\): \[y[i,j] = \sum_{m,n} h[m,n] \cdot x[i+rm, j+rn]\]
Receptive Field Without Downsampling
- Rate \(r=1\): Standard 3×3, RF = 3
- Rate \(r=2\): Effective 5×5, RF = 5
- Rate \(r=4\): Effective 9×9, RF = 9
Parameters remain constant: \(k^2\)
Output Stride Control
Replace stride/pooling with dilation to maintain resolution
Atrous Spatial Pyramid Pooling (ASPP)
Multi-Scale Context
Parallel branches with different rates:
- 1×1 convolution (image-level features)
- 3×3 rate=6 (small receptive field)
- 3×3 rate=12 (medium receptive field)
- 3×3 rate=18 (large receptive field)
- Global average pooling → 1×1 conv → bilinear upsample
Concatenate all branches → 1×1 conv to fuse
Mathematical Formulation
\[F_{out} = Conv_{1×1}\left(\bigparallel_{r \in \{1,6,12,18\}} ASPP_r(F_{in}) \parallel GAP(F_{in})\right)\]
where \(\parallel\) denotes concatenation.

Conditional Random Fields
Energy Function
\[E(x) = \sum_i \psi_u(x_i) + \sum_{i,j} \psi_p(x_i, x_j)\]
Unary potential (from CNN): \[\psi_u(x_i) = -\log P(x_i)\]
Pairwise potential (smoothness): \[\psi_p(x_i, x_j) = \mu(x_i, x_j) \sum_{m} w^{(m)} k^{(m)}(f_i, f_j)\]
where kernels based on:
- Color similarity: \(\exp\left(-\frac{|I_i - I_j|^2}{2\sigma_\alpha^2}\right)\)
- Spatial proximity: \(\exp\left(-\frac{|p_i - p_j|^2}{2\sigma_\beta^2}\right)\)
Mean Field Approximation
Iterative update (5-10 iterations): \[Q_i(l) = \frac{1}{Z_i} \exp\{-\psi_u(l) - \sum_j \psi_p(l, Q_j)\}\]

CRF refines boundaries using image appearance
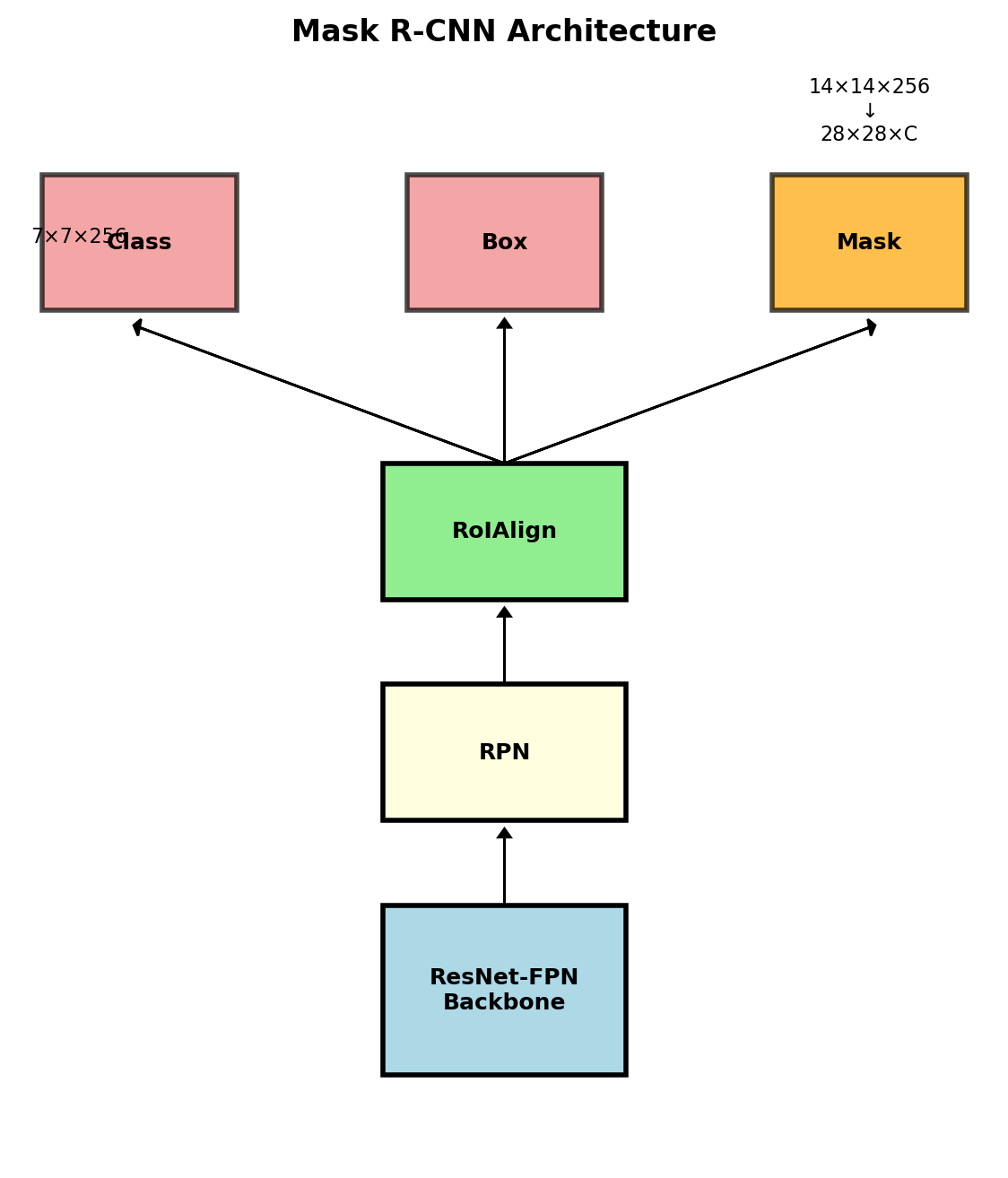
Instance Segmentation: Mask R-CNN
Extending Faster R-CNN
Add mask branch parallel to box/class heads:
Box head: 7×7×256 → FC → class + box Mask head: 14×14×256 → Conv → 28×28×C
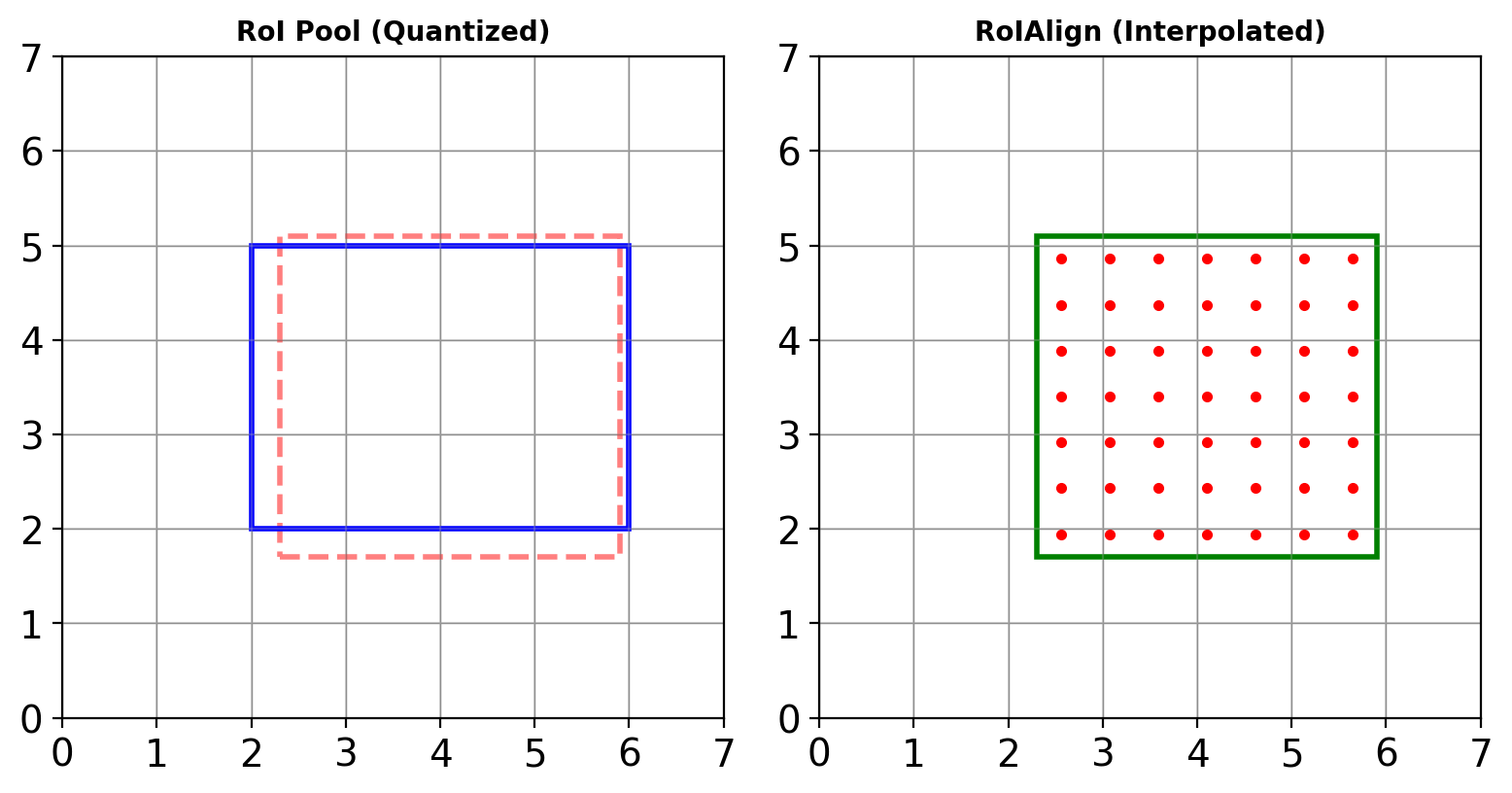
RoIAlign vs RoIPool
RoIPool: Quantization to integer coordinates RoIAlign: Bilinear interpolation at exact locations
\[\text{RoIAlign}(x, y) = \sum_{i,j} x_{ij} \cdot \max(0, 1 - |x - i|) \cdot \max(0, 1 - |y - j|)\]
Mask Loss
Binary cross-entropy per class: \[\mathcal{L}_{mask} = -\frac{1}{m^2} \sum_{i,j} [y_{ij}^k \log \hat{y}_{ij}^k + (1-y_{ij}^k)\log(1-\hat{y}_{ij}^k)]\]
Only computed for ground truth class \(k\)
RoIAlign: Precise Alignment
RoI Pool vs RoIAlign
RoI Pool:
- Quantize RoI boundaries: \(\lfloor x \rfloor\)
- Quantize grid cells
- Max pool in each cell
RoIAlign:
- Keep exact RoI boundaries
- Sample at regular grid points
- Bilinear interpolation at each point
- Max/average pool interpolated values
Impact
- Mask AP: 30.9 → 33.9 (+3.0)
- Box AP: marginal improvement
- Critical for pixel-level tasks
Mask R-CNN Architecture Details

Multi-task learning: \(\mathcal{L} = \mathcal{L}_{cls} + \mathcal{L}_{box} + \mathcal{L}_{mask}\)
Loss Functions for Segmentation
Pixel-wise Cross-Entropy
\[\mathcal{L}_{CE} = -\frac{1}{HW}\sum_{i,j} \sum_{c} y_{ijc} \log(\hat{y}_{ijc})\]
Problem: Class imbalance (background >> foreground)
Dice Loss
\[\mathcal{L}_{Dice} = 1 - \frac{2\sum_{i,j} y_{ij}\hat{y}_{ij} + \epsilon}{\sum_{i,j} y_{ij} + \sum_{i,j} \hat{y}_{ij} + \epsilon}\]
Directly optimizes IoU-like metric
Focal Loss for Segmentation
\[\mathcal{L}_{Focal} = -\alpha(1-\hat{y}_{ij})^\gamma y_{ij}\log(\hat{y}_{ij})\]
Down-weights easy pixels
Boundary Loss
Weight pixels by distance to boundary: \[w_{ij} = 1 + \alpha \cdot \exp\left(-\frac{d_{ij}^2}{2\sigma^2}\right)\]
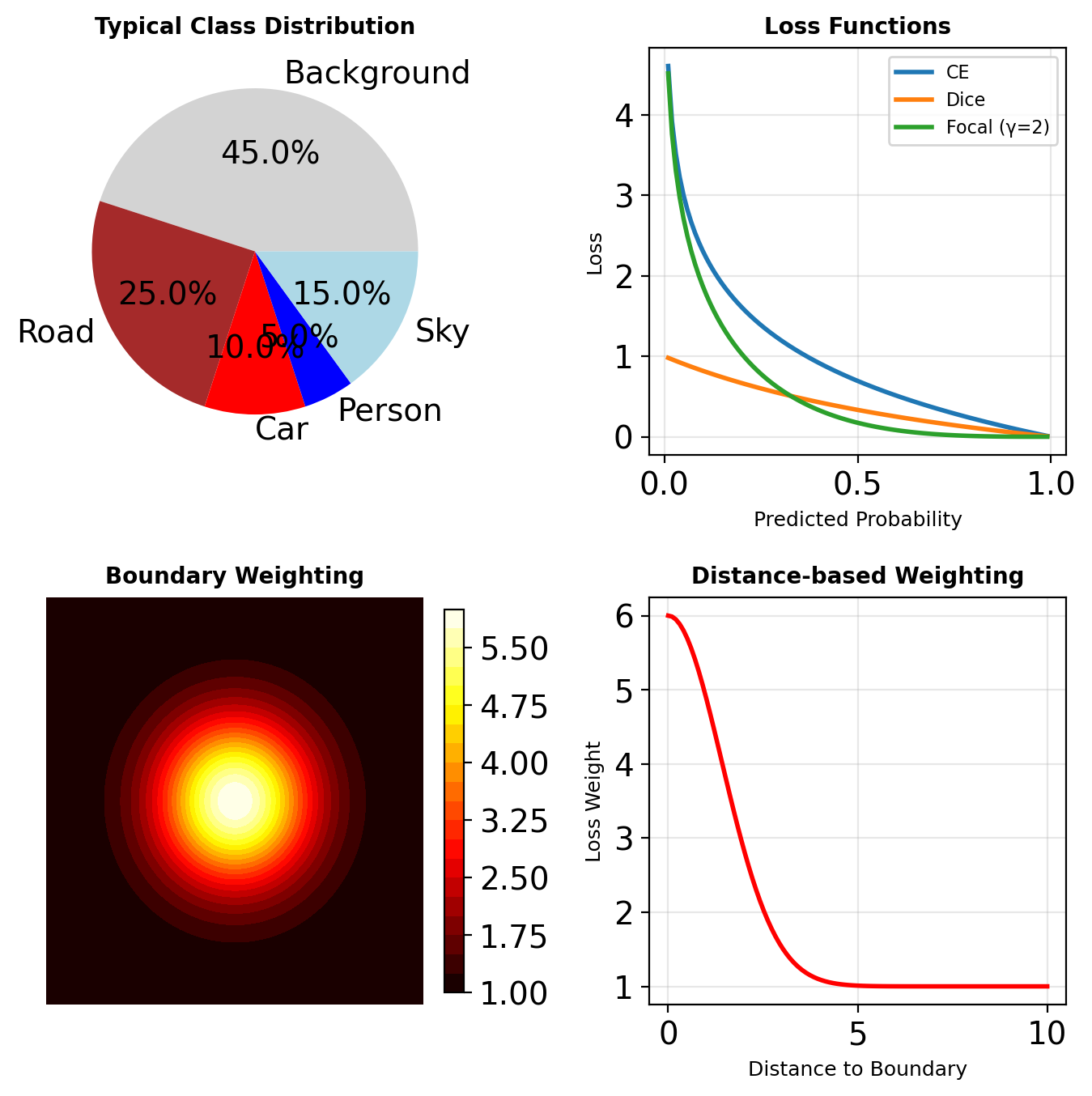
Evaluation Metrics
Mean Intersection over Union
\[\text{mIoU} = \frac{1}{C} \sum_{c=1}^{C} \frac{TP_c}{TP_c + FP_c + FN_c}\]
where for each class \(c\):
- \(TP_c\): True positive pixels
- \(FP_c\): False positive pixels
- \(FN_c\): False negative pixels
Frequency Weighted IoU
\[\text{FWIoU} = \frac{1}{\sum_c n_c} \sum_{c} n_c \cdot \text{IoU}_c\]
Instance Segmentation: Mask AP
Average Precision at different IoU thresholds:
- AP: IoU = 0.50:0.05:0.95
- AP₅₀: IoU = 0.50
- AP₇₅: IoU = 0.75
Panoptic Segmentation
Unifying Semantic and Instance
Stuff: Uncountable regions (sky, road, grass) Things: Countable objects (cars, people)
Panoptic Quality Metric
\[PQ = \frac{\sum_{(p,g) \in TP} \text{IoU}(p,g)}{|TP| + \frac{1}{2}|FP| + \frac{1}{2}|FN|}\]
Decomposes into: \[PQ = \underbrace{\frac{\sum_{(p,g) \in TP} \text{IoU}(p,g)}{|TP|}}_{\text{Segmentation Quality}} \times \underbrace{\frac{|TP|}{|TP| + \frac{1}{2}|FP| + \frac{1}{2}|FN|}}_{\text{Recognition Quality}}\]
Panoptic FPN
Single network for both tasks:
- Shared FPN backbone
- Semantic head for stuff
- Instance head (Mask R-CNN) for things
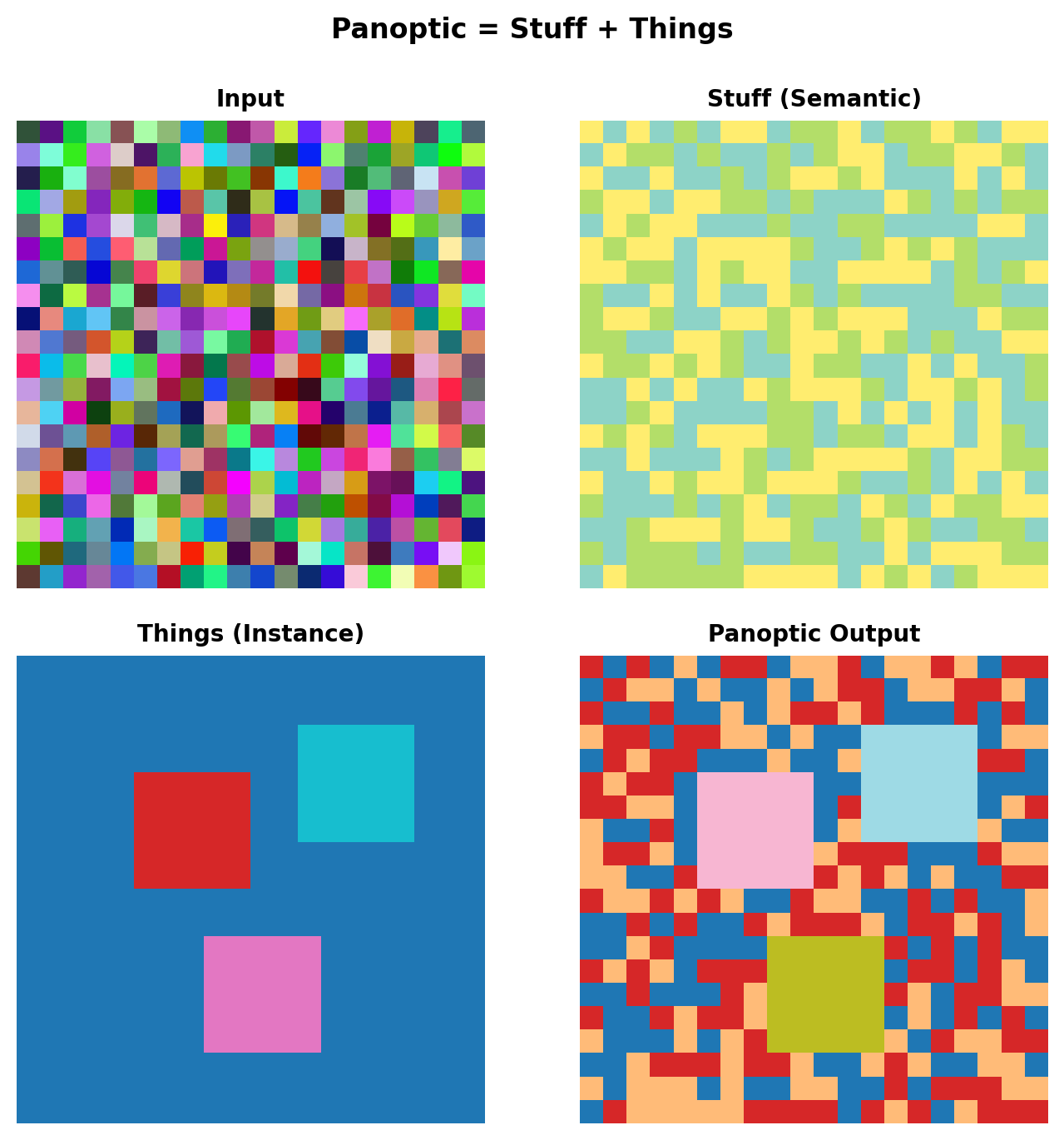
Efficient Segmentation
BiSeNet: Bilateral Segmentation
Two pathways:
Spatial Path: High resolution, shallow
- 1/8 downsampling only
- Preserves spatial detail
Context Path: Low resolution, deep
- Full downsampling
- Captures semantics
Fusion with Feature Fusion Module (FFM)
ENet: Asymmetric Encoder-Decoder
- Early downsampling (block 1)
- Asymmetric convolution: 1×n + n×1
- Bottleneck without projection in decoder
- 18× faster than SegNet
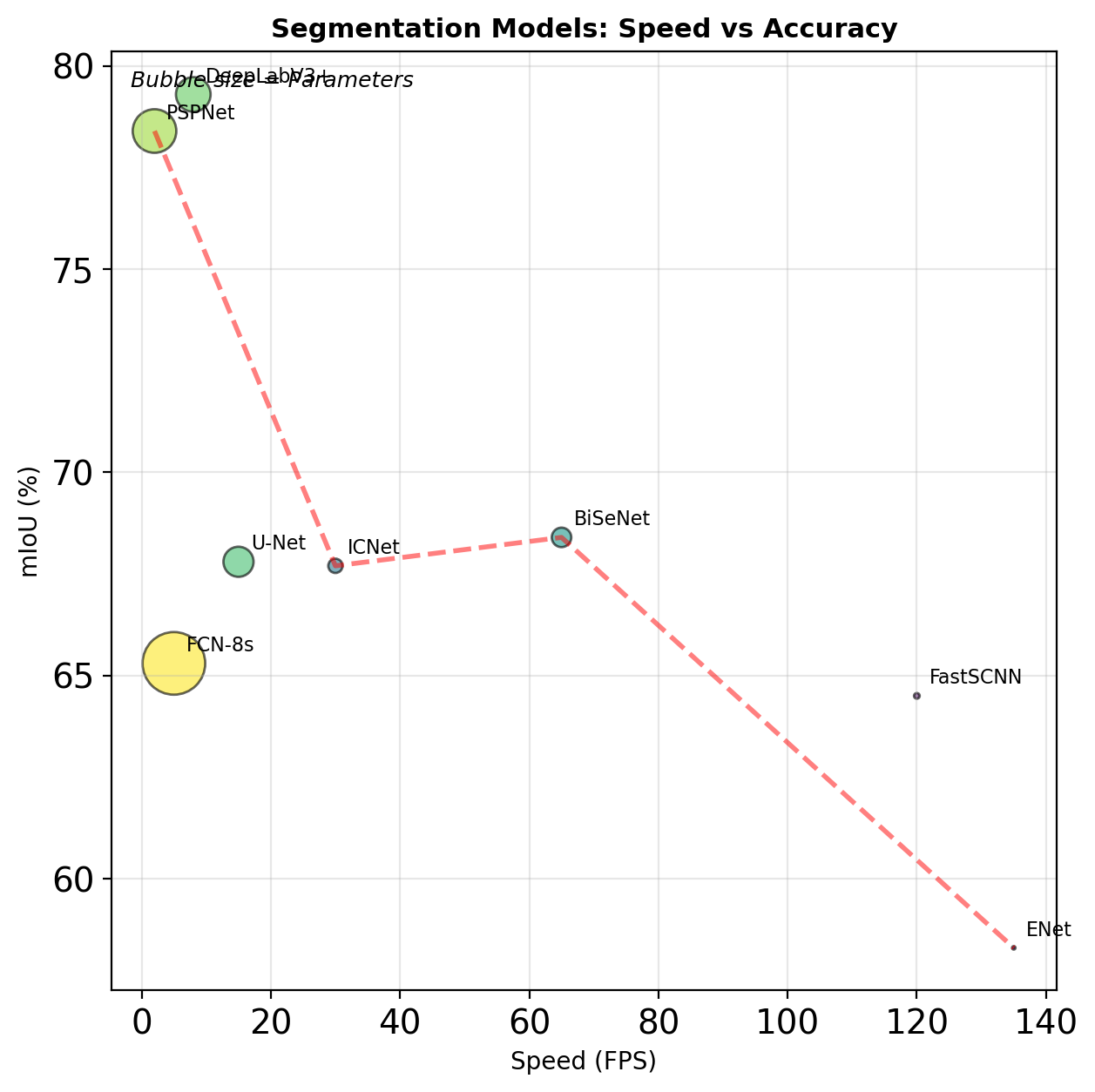
Speed vs Accuracy
| Model | mIoU | FPS | Params |
|---|---|---|---|
| FCN-8s | 65.3 | 5 | 134M |
| U-Net | 67.8 | 15 | 31M |
| BiSeNet | 68.4 | 65 | 13M |
| ENet | 58.3 | 135 | 0.4M |
Modern Developments
HRNet: High-Resolution Network
Maintains high-resolution representations:
- Parallel multi-resolution streams
- Repeated multi-scale fusion
- No recovery from low resolution
\[F_s^{(l+1)} = \sum_{r=1}^{S} \mathcal{T}_{r \rightarrow s}(F_r^{(l)})\]
where \(\mathcal{T}\) is resolution transformation.
PointRend: Rendering Perspective
Treat segmentation as rendering:
- Coarse prediction
- Select uncertain points
- Refine with point-wise MLP
- Iterate until convergence
Segment Anything Model (SAM) - 2023
Foundation model for segmentation:
- Prompt-based (point, box, text)
- Zero-shot generalization
- 1B+ mask dataset
Note: Transformer-based, covered in later lectures
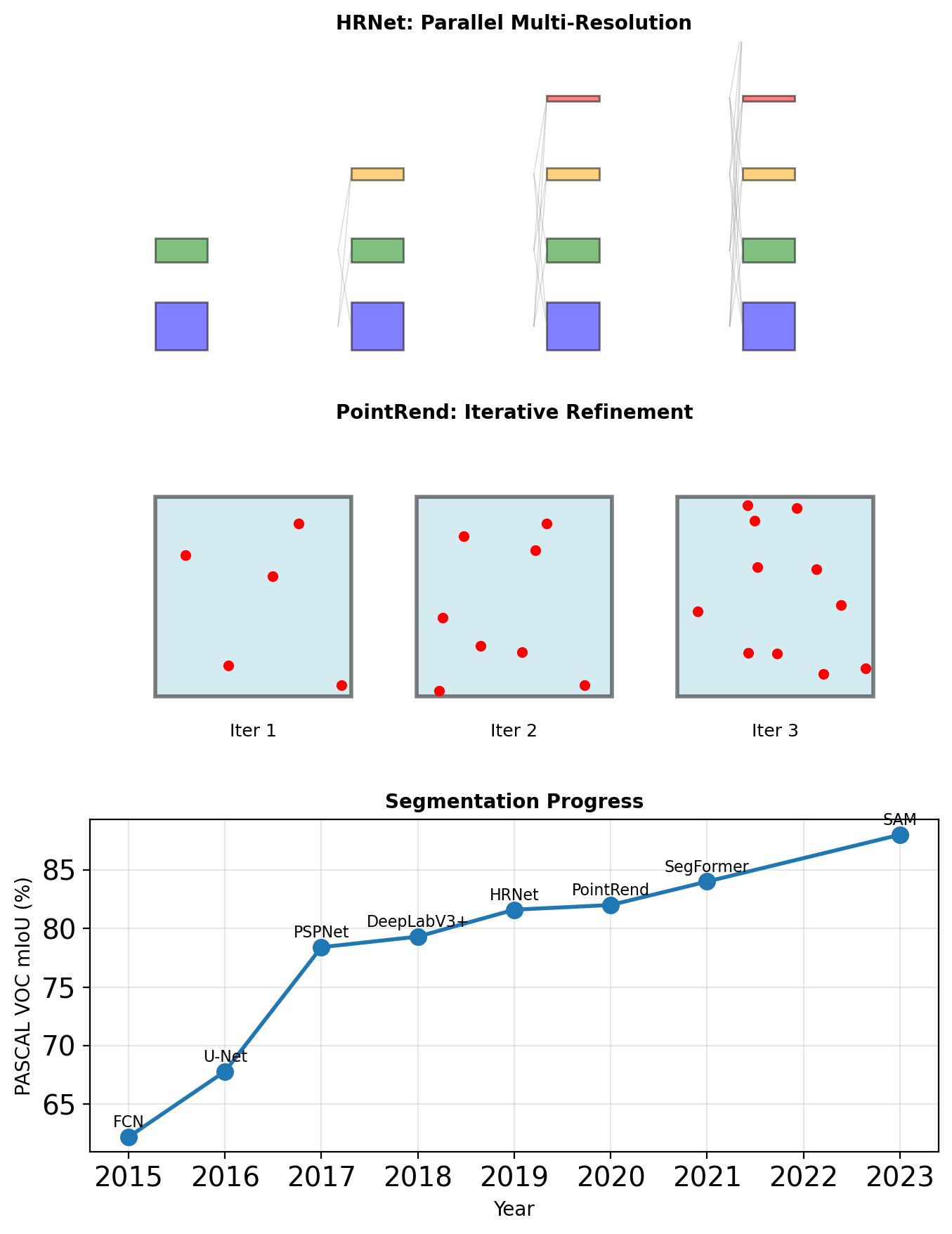
Segmentation has evolved from simple upsampling to sophisticated multi-scale reasoning and iterative refinement
The 3D Representation Problem
Representation Choices
Voxels: Regular 3D grid
- Natural for 3D convolutions
- Memory: \(O(N^3)\) for \(N^3\) resolution
- Mostly empty space (>95%)
Point Clouds: Unordered sets
- Compact: only occupied space
- No regular structure
- Permutation invariance required
Meshes: Vertices + faces
- Efficient surface representation
- Irregular connectivity
- Graph convolution needed
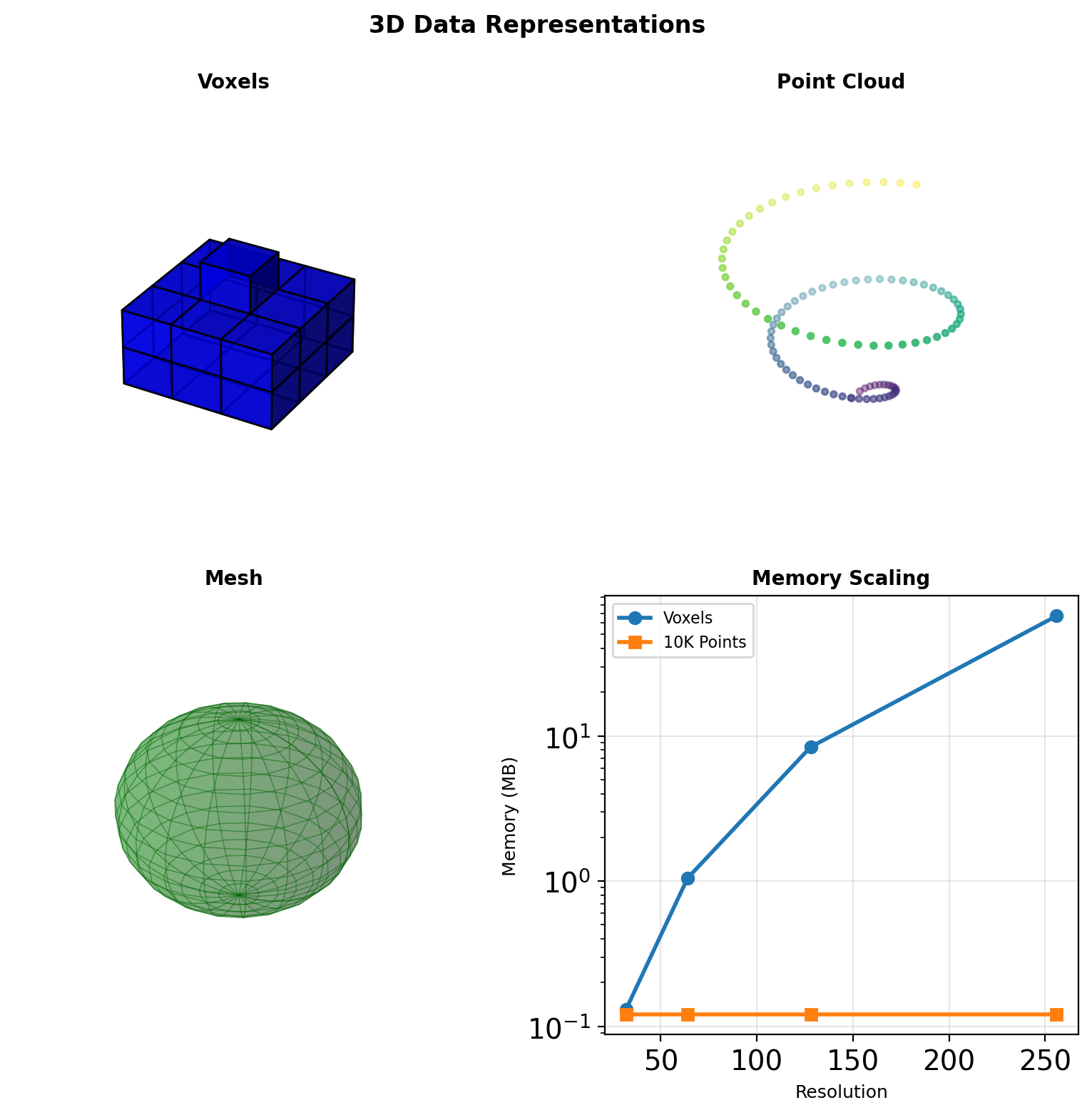
Voxel Representations
3D Convolutions
Standard 3D convolution: \[y[d,i,j] = \sum_{c} \sum_{k,m,n} w[k,m,n,c] \cdot x[d+k, i+m, j+n, c]\]
Computational complexity: \[O(K^3 \cdot C_{in} \cdot C_{out} \cdot D \cdot H \cdot W)\]
# PyTorch 3D convolution
conv3d = nn.Conv3d(
in_channels=32,
out_channels=64,
kernel_size=3,
padding=1
)
# Input: (B, 32, D, H, W)
# Output: (B, 64, D, H, W)Sparse Solutions
Only ~5% voxels occupied → sparse convolutions
- Submanifold sparse convolutions
- Minkowski Engine: generalized sparse convolutions
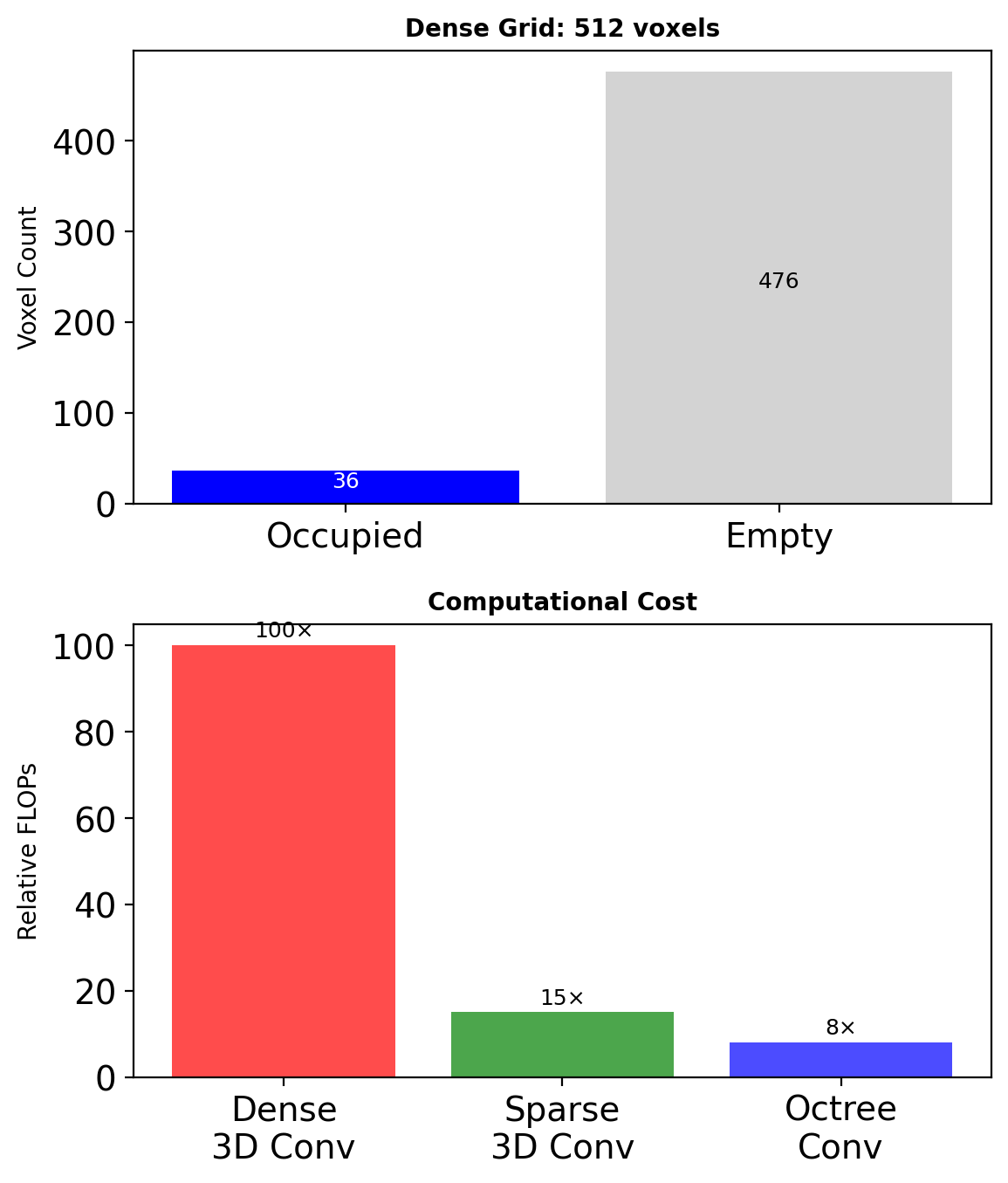
Sparsity: computational necessity at high resolutions
Point Cloud Representations
The Permutation Problem
Point cloud: \(\mathcal{P} = \{p_i\}_{i=1}^N\) where \(p_i \in \mathbb{R}^3\)
Required: \(f(\{p_1, ..., p_N\}) = f(\pi(\{p_1, ..., p_N\}))\)
for any permutation \(\pi\).
PointNet Solution
\[f(\{x_1, ..., x_n\}) = \gamma \left( \max_{i=1,...,n} h(x_i) \right)\]
where:
- \(h\): per-point MLP (shared weights)
- \(\max\): symmetric aggregation
- \(\gamma\): post-processing MLP
Achieves permutation invariance through symmetric function
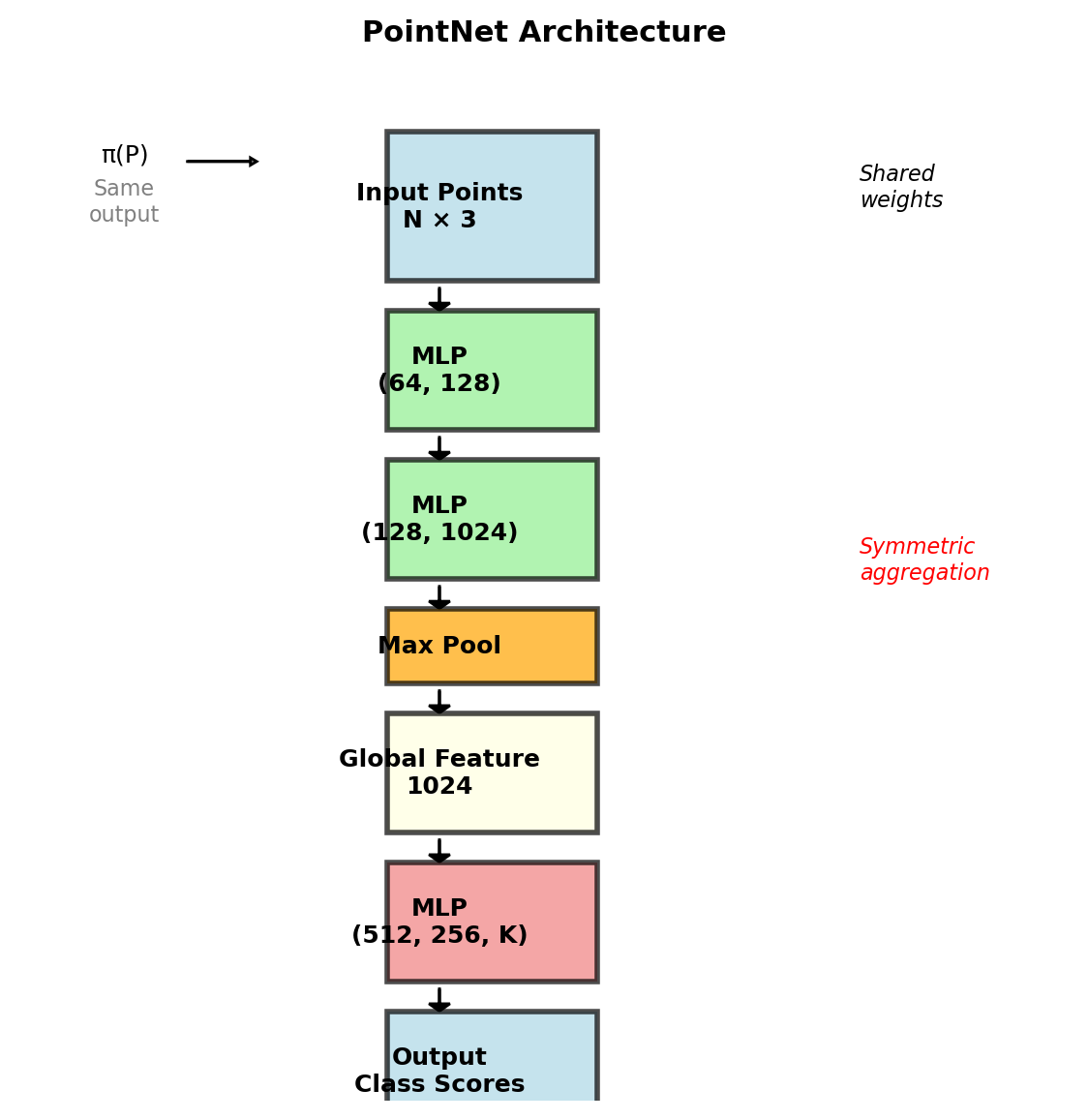
PointNet Architecture
Network Components
T-Net: Learn input transformation
- 3×3 or 64×64 transformation matrix
- Spatial transformer network for points
- Regularization: \(\mathcal{L}_{reg} = ||I - AA^T||^2\)
Feature Extraction:
class PointNetEncoder(nn.Module):
def __init__(self):
self.conv1 = nn.Conv1d(3, 64, 1)
self.conv2 = nn.Conv1d(64, 128, 1)
self.conv3 = nn.Conv1d(128, 1024, 1)
def forward(self, x):
# x: (B, 3, N)
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = self.conv3(x)
# Global max pooling
x = torch.max(x, 2)[0]
return x # (B, 1024)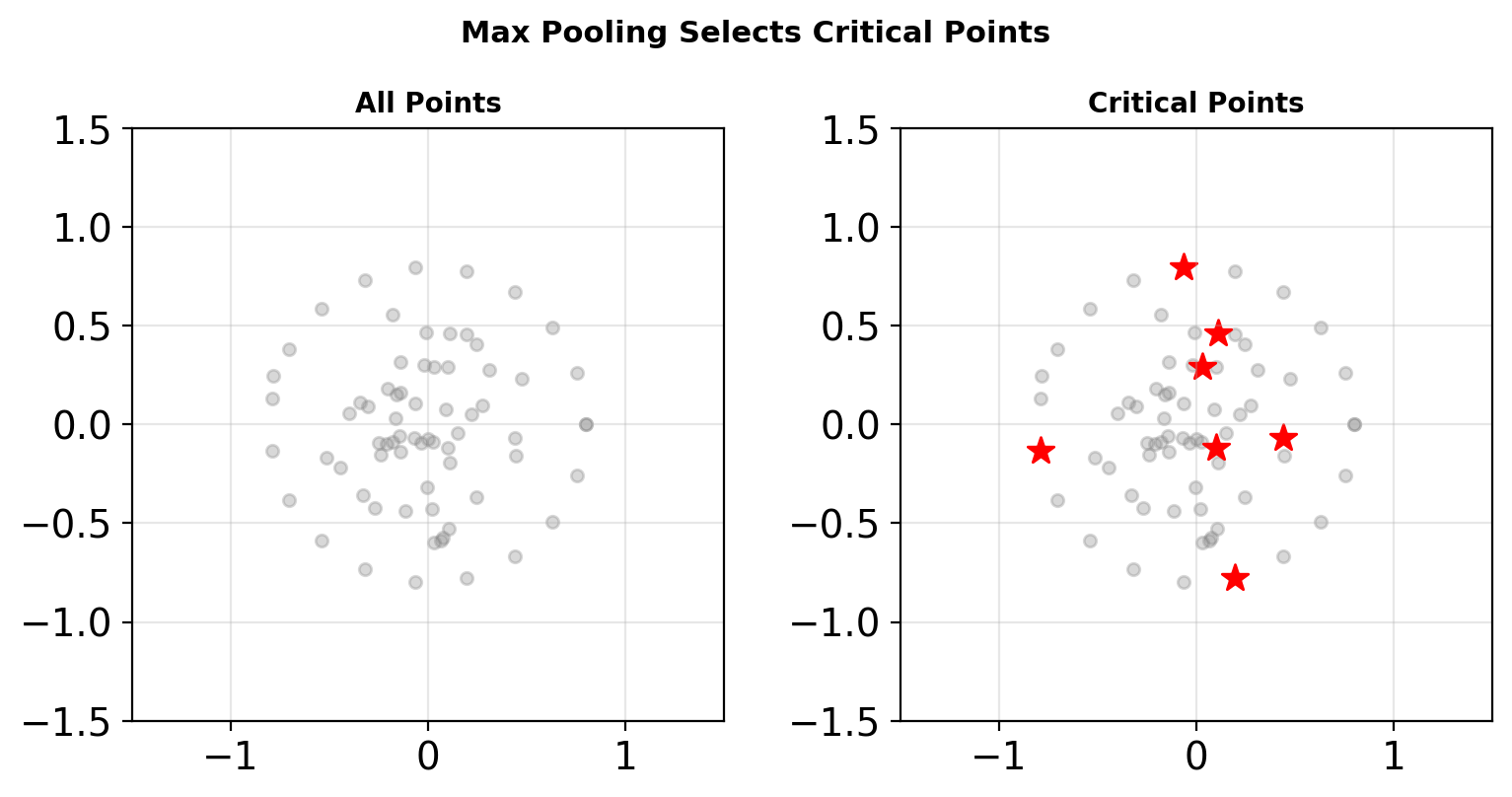
Only subset of points contribute to each feature dimension
Point Cloud Convolutions
PointNet++: Hierarchical Learning
- Sampling: Farthest point sampling
- Grouping: Ball query or k-NN
- PointNet: Process local regions
Dynamic Graph CNN
Build k-NN graph dynamically: \[\mathbf{e}_{ij} = h_\Theta(\mathbf{x}_i, \mathbf{x}_j - \mathbf{x}_i)\]
Edge convolution: \[\mathbf{x}'_i = \max_{j \in \mathcal{N}(i)} \mathbf{e}_{ij}\]
KPConv: Kernel Point Convolution
Place kernel points in 3D space: \[y_i = \sum_{j \in \mathcal{N}(i)} \sum_{k=1}^K h(\mathbf{x}_j - \mathbf{x}_i, \tilde{\mathbf{x}}_k) W_k x_j\]
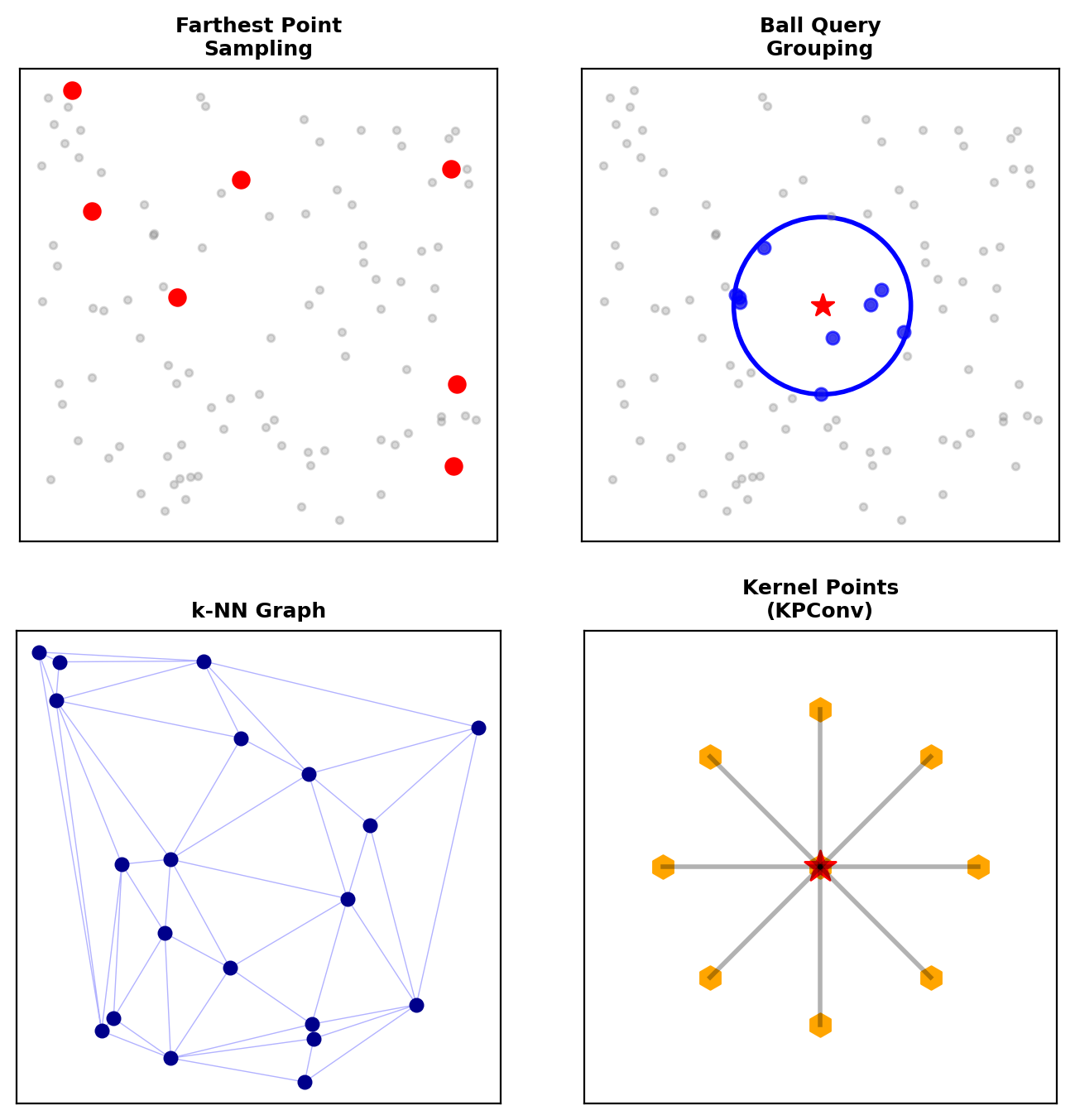
3D Detection in Point Clouds
VoxelNet Pipeline
- Voxelization: Group points into voxels
- Feature encoding: PointNet per voxel
- 3D convolution: Process voxel grid
- RPN: Generate 3D proposals
SECOND: Sparse Convolutions
- Spatially sparse convolutional networks
- 3-5× speedup over dense
- Rule generation for sparse operations
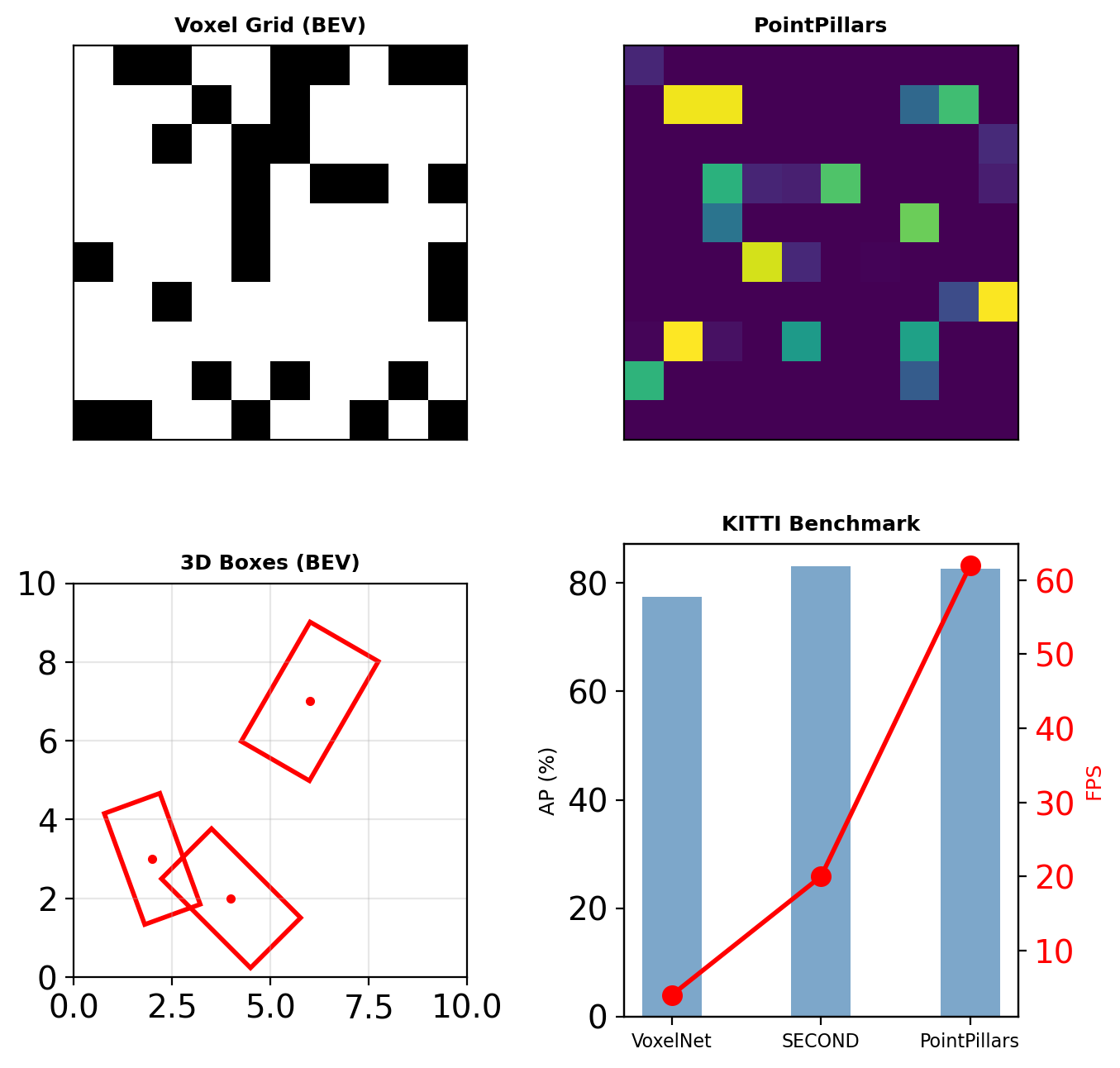
PointPillars
- Organize as vertical columns (pillars)
- Pseudo-image from bird’s eye view
- Enables 2D convolutions (faster)
KITTI benchmark: Cars @ 0.7 IoU
- PointPillars: 82.6% AP, 62 FPS
- SECOND: 83.1% AP, 20 FPS
- VoxelNet: 77.5% AP, 4 FPS
Mesh and Multi-view Approaches
Mesh Convolutions
Graph structure: \(\mathcal{G} = (\mathcal{V}, \mathcal{E})\)
Spectral convolution: \[y = U g_\theta U^T x\]
where \(U\) are eigenvectors of graph Laplacian.
Spatial convolution (MoNet): \[y_i = \sum_{j \in \mathcal{N}(i)} w(\mathbf{u}_{ij}) x_j\]
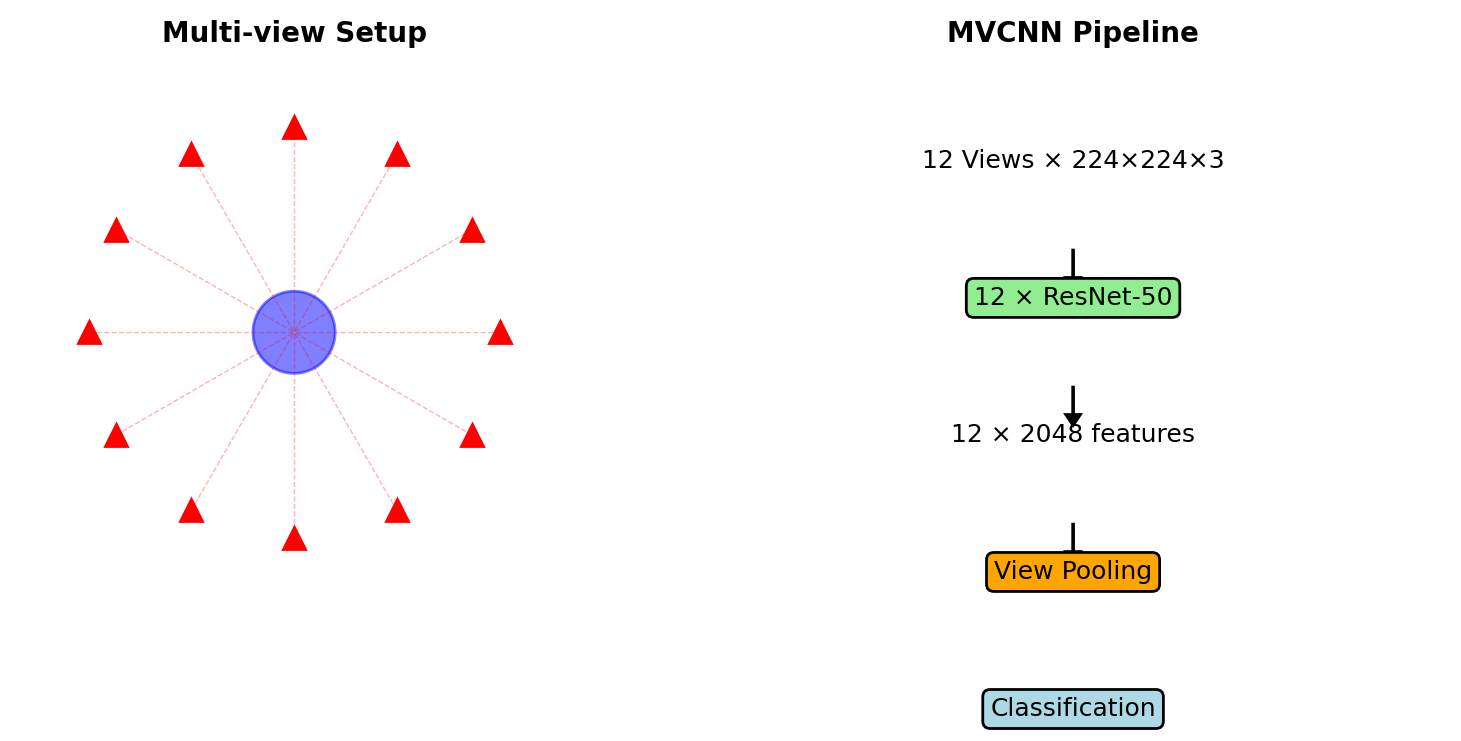
Multi-view CNNs
- Render 3D object from multiple views
- Process each view with 2D CNN
- Aggregate: max/mean pooling
- Leverage ImageNet pre-training
MVCNN: 90.1% accuracy on ModelNet40 (vs 77% for voxels, 89.2% for PointNet)
Depth Estimation from Single Images
Monocular Depth as Dense Regression
Output: \(D \in \mathbb{R}^{H \times W}\)
Scale-invariant loss: \[\mathcal{L}_{si} = \frac{1}{n}\sum_i d_i^2 - \frac{\lambda}{n^2}\left(\sum_i d_i\right)^2\]
where \(d_i = \log \hat{D}_i - \log D_i\)
Ordinal loss (relative depth): \[\mathcal{L}_{ord} = \sum_{(i,j) \in \mathcal{P}} -\log \sigma(z_i - z_j)\]
where \(\mathcal{P}\) are pairs with known ordering
Self-supervised from Video
Structure from motion constraint: \[I_{t+1} \approx \text{warp}(I_t, D_t, T_{t \rightarrow t+1})\]
Photometric loss: \[\mathcal{L}_{photo} = ||I_{t+1} - \hat{I}_{t+1}||_1 + \text{SSIM}(I_{t+1}, \hat{I}_{t+1})\]
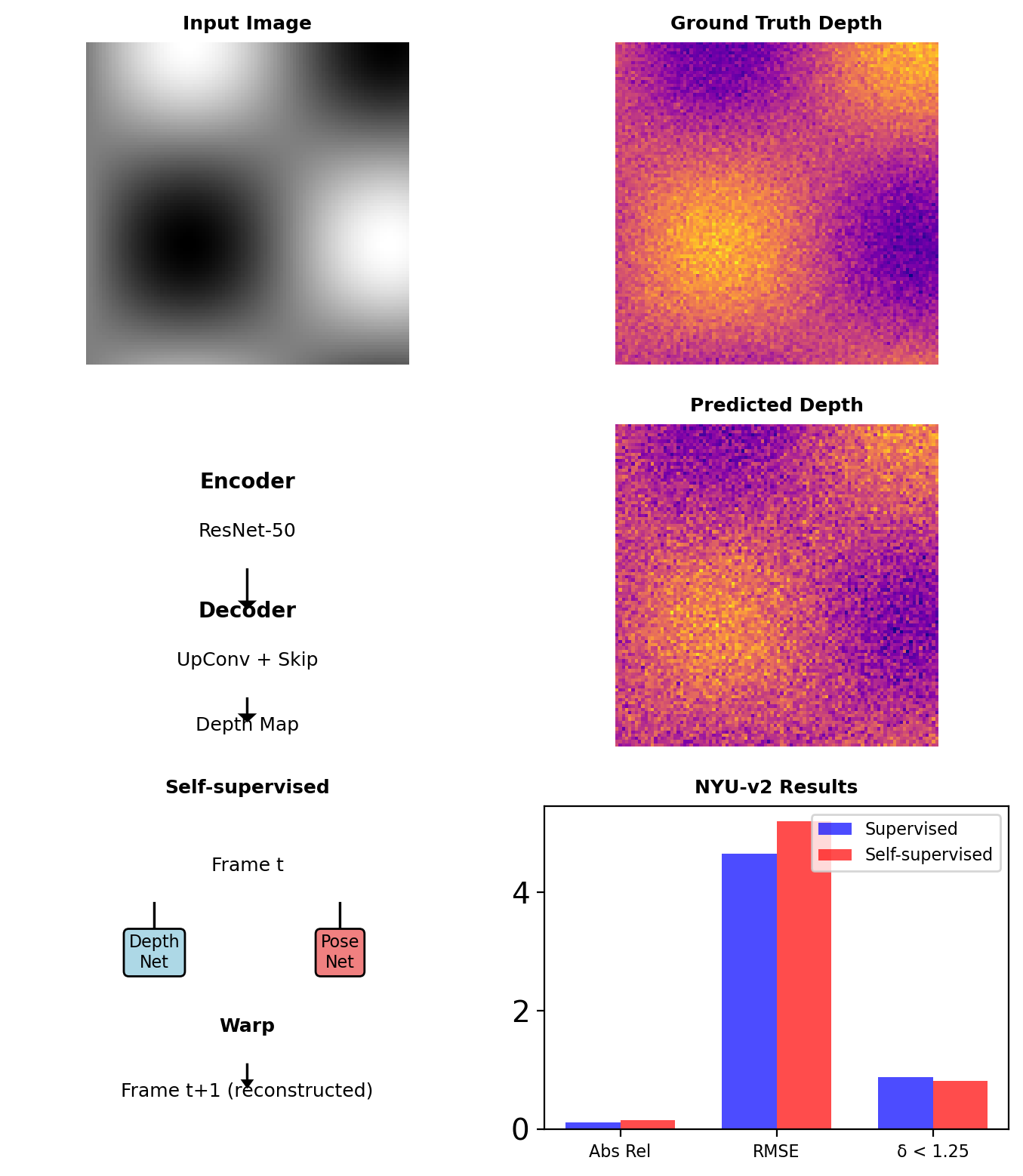
Self-supervision enables training on unlimited video data without depth labels
[1]
Z. Zou, K. Chen, Z. Shi, Y. Guo, and J. Ye, “Object detection in 20 years: A survey,” Proceedings of the IEEE, vol. 111, no. 3, pp. 257–276, 2023.
[2]
S. Ren, K. He, R. Girshick, and J. Sun, “Faster r-CNN: Towards real-time object detection with region proposal networks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 6, pp. 1137–1149, 2016.
[3]
T.-Y. Lin, P. Goyal, R. Girshick, K. He, and P. Dollár, “Focal loss for dense object detection,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2980–2988.
[4]
G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, “Densely connected convolutional networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 4700–4708.
[5]
J. Redmon, S. Divvala, R. Girshick, and A. Farhadi, “You only look once: Unified, real-time object detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 779–788.
[6]
T.-Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan, and S. Belongie, “Feature pyramid networks for object detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2117–2125.
[7]
K. He, G. Gkioxari, P. Dollár, and R. Girshick, “Mask r-CNN,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2961–2969.
[8]
M. Tan and Q. Le, “EfficientNet: Rethinking model scaling for convolutional neural networks,” in International conference on machine learning, PMLR, 2019, pp. 6105–6114.
[9]
Z. Cao, G. Hidalgo, T. Simon, S.-E. Wei, and Y. Sheikh, “OpenPose: Realtime multi-person 2D pose estimation using part affinity fields,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 43, no. 1, pp. 172–186, 2019.
[10]
A. Kirillov et al., “Segment anything,” in Proceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4015–4026.